bean searcher
v4.3.5

Anglais | Chine
Documentation:https://bs.zhxu.cn
Numéro 1 : https://www.aliyun.com/minisite/goods?userCode=zugtbi5w
Blog JueJin:
Une seule ligne de code à réaliser :
Design thinking : la réflexion de Bean Searcher
Architecture:
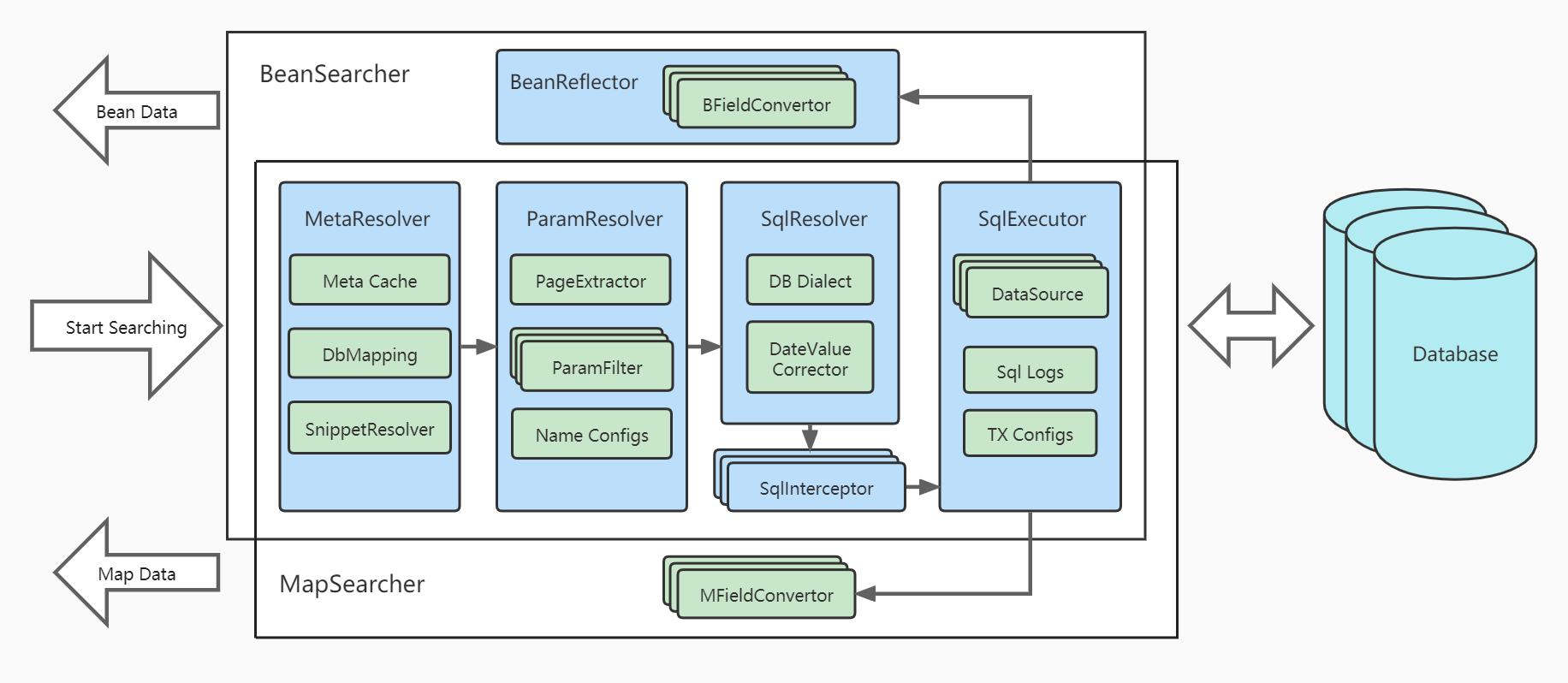
Bien que CREATE/UPDATE/DELETE soient les points forts d'Hibernate, MyBatis, DataJDBC et autres ORM, les requêtes, en particulier les requêtes de liste complexes avec multi conditions , multi tables , pagination , sorting , ont toujours été leurs faiblesses.
L'ORM traditionnel est difficile à réaliser une récupération de liste complexe avec moins de code, mais Bean Searcher a fait de gros efforts à cet égard. Ces requêtes complexes peuvent être résolues en presque une seule ligne de code.
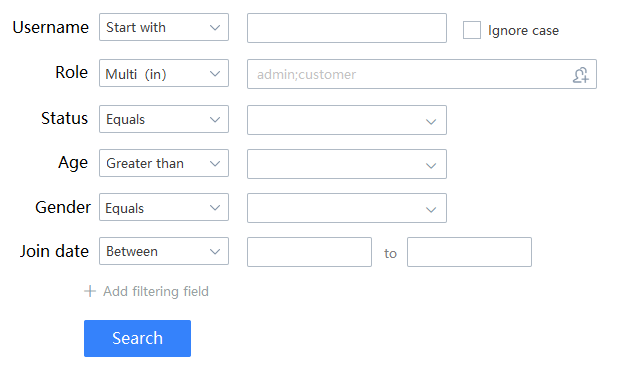
Le back-end doit écrire une API de récupération, et si elle est écrite avec un ORM traditionnel, la complexité du code est très élevée
Mais Bean Searcher peut :
Tout d’abord, vous disposez d’une classe Entity :
@ SearchBean ( tables = "user u, role r" , joinCond = "u.role_id = r.id" , autoMapTo = "u" )
public class User {
private long id ;
private String username ;
private int status ;
private int age ;
private String gender ;
private Date joinDate ;
private int roleId ;
@ DbField ( "r.name" )
private String roleName ;
// Getters and setters...
}Ensuite vous pouvez compléter l'API avec une seule ligne de code :
@ RestController
@ RequestMapping ( "/user" )
public class UserController {
@ Autowired
private BeanSearcher beanSearcher ; // Inject BeanSearcher
@ GetMapping ( "/index" )
public SearchResult < User > index ( HttpServletRequest request ) {
// Only one line of code written here
return beanSearcher . search ( User . class , MapUtils . flat ( request . getParameterMap ()), new String []{ "age" });
}
}Cette ligne de code peut réaliser:
agePar exemple, cette API peut être demandée comme suit :
GET: /user/index
Récupération par pagination par défaut :
{
"dataList" : [
{
"id" : 1 ,
"username" : " Jack " ,
"status" : 1 ,
"age" : 25 ,
"gender" : " Male " ,
"joinDate" : " 2021-10-01 " ,
"roleId" : 1 ,
"roleName" : " User "
},
... // 15 records default
],
"totalCount" : 100 ,
"summaries" : [
2500 // age statistics
]
} GET: /user/index? page=1 & size=10
Récupération par pagination spécifiée
GET: /user/index? status=1
Récupération avec status = 1 par pagination par défaut
GET: /user/index? name=Jac & name-op=sw
Récupération avec name commençant par Jac par pagination par défaut
GET: /user/index? name=Jack & name-ic=true
Récupération avec name = Jack (cas ignoré) par pagination par défaut
GET: /user/index? sort=age & order=desc
Tri de récupération par age décroissant et par pagination par défaut
GET: /user/index? onlySelect=username,age
username,age uniquement par pagination par défaut :
{
"dataList" : [
{
"username" : " Jack " ,
"age" : 25 ,
},
... // 15 records default
],
"totalCount" : 100 ,
"summaries" : [
2500 // age statistics
]
} GET: /user/index? selectExclude=joinDate
Récupération de la pagination par défaut exclue joinDate
Map < String , Object > params = MapUtils . builder ()
. selectExclude ( User :: getJoinDate ) // Exclude joinDate field
. field ( User :: getStatus , 1 ) // Filter:status = 1
. field ( User :: getName , "Jack" ). ic () // Filter:name = 'Jack' (case ignored)
. field ( User :: getAge , 20 , 30 ). op ( Opetator . Between ) // Filter:age between 20 and 30
. orderBy ( User :: getAge , "asc" ) // Sorting by age ascending
. page ( 0 , 15 ) // Pagination: page=0 and size=15
. build ();
List < User > users = beanSearcher . searchList ( User . class , params );Démos :
L'utilisation de Bean Searcher peut considérablement économiser le temps de développement des API de récupération de listes complexes !
domain d'origine, sans définir de nouvelle EntityBean Searcher peut fonctionner avec n'importe quel framework JavaWeb, tel que : SpringBoot, SpringMVC, Grails, Jfinal, etc.
Il vous suffit d'ajouter une dépendance :
implementation ' cn.zhxu:bean-searcher-boot-stater:4.3.4 ' puis vous pouvez injecter Searcher dans un Controller ou Service :
/**
* Inject a MapSearcher, which retrieved data is Map objects
*/
@Autowired
private MapSearcher mapSearcher;
/**
* Inject a BeanSearcher, which retrieved data is generic objects
*/
@Autowired
private BeanSearcher beanSearcher;Il vous suffit d'ajouter une dépendance :
implementation ' cn.zhxu:bean-searcher-solon-plugin:4.3.4 ' puis vous pouvez injecter Searcher dans un Controller ou Service :
/**
* Inject a MapSearcher, which retrieved data is Map objects
*/
@Inject
private MapSearcher mapSearcher;
/**
* Inject a BeanSearcher, which retrieved data is generic objects
*/
@Inject
private BeanSearcher beanSearcher;En ajoutant cette dépendance :
implementation ' cn.zhxu:bean-searcher:4.3.4 ' alors vous pouvez créer un Searcher avec SearcherBuilder :
DataSource dataSource = ... // Get the dataSource of the application
// DefaultSqlExecutor suports multi datasources
SqlExecutor sqlExecutor = new DefaultSqlExecutor ( dataSource );
// build a MapSearcher
MapSearcher mapSearcher = SearcherBuilder . mapSearcher ()
. sqlExecutor ( sqlExecutor )
. build ();
// build a BeanSearcher
BeanSearcher beanSearcher = SearcherBuilder . beanSearcher ()
. sqlExecutor ( sqlExecutor )
. build ();Vous pouvez personnaliser et étendre n'importe quel composant dans Bean Searcher.
Par exemple:
FieldOp pour prendre en charge d'autres opérateurs de terrainDbMapping pour prendre en charge les annotations d'autres ORMParamResolver pour prendre en charge les paramètres de requête JSONFieldConvertor pour prendre en charge tout type de champDialect pour prendre en charge davantage de bases de donnéesRéférence:https://bs.zhxu.cn
[ Sa-Token ]
[ Fluent MyBatis ] MyBatis 语法增强框架, 综合了 MyBatisPlus, DynamicSql,Jpa 等框架的特性和优点,利用注解处理器生成代码
[ OkHttps ]轻量却强大的 HTTP 客户端,前后端通用,支持 WebSocket 与 Stomp 协议
[hrun4j]
[ JsonKit ]超轻量级 JSON 门面工具,用法简单,不依赖具体实现,让业务代码与 Jackson、Gson、Fastjson 等解耦!
[ UI gratuite ] avec Vue3 + TypeScript , et avec UI UI !
git checkout -b feat/xxxxgit commit -am 'feat(function): add xxxxx'git push origin feat/xxxxpull request

