genai_robotics
1.0.0
Ce référentiel contient une configuration expérimentale respectueuse de la confidentialité pour exploiter les méthodes d'IA générative dans le contrôle robotique. Avec la solution présentée ici, un utilisateur peut définir librement des actions vocales qui se traduisent en plans qu'un robot aspirateur peut exécuter dans un environnement de monde ouvert observé par une caméra.
Les avantages fondamentaux des méthodes présentées ici sont :
Le système a été développé lors d'un hackathon de 3 jours en tant qu'exercice d'apprentissage et preuve de concept selon lequel les outils d'IA modernes peuvent réduire considérablement le temps de développement des solutions de contrôle robotique.
Pour utiliser toutes les fonctionnalités de ce référentiel, voici ce que vous devez avoir :
Pour commencer, suivez les étapes ci-dessous :
requirements.txt dans un environnement Python (tests avec Python 3.11)src/config.template.toml en config.toml . Pour toutes les étapes ci-dessous, insérez les informations d'identification acquises dans config.tomlpython-roborock .src/run.py pour exécuter le flux de travail. La meilleure façon de comprendre ce que fait ce référentiel en détail et comment les éléments interagissent est d'utiliser un diagramme d'architecture :
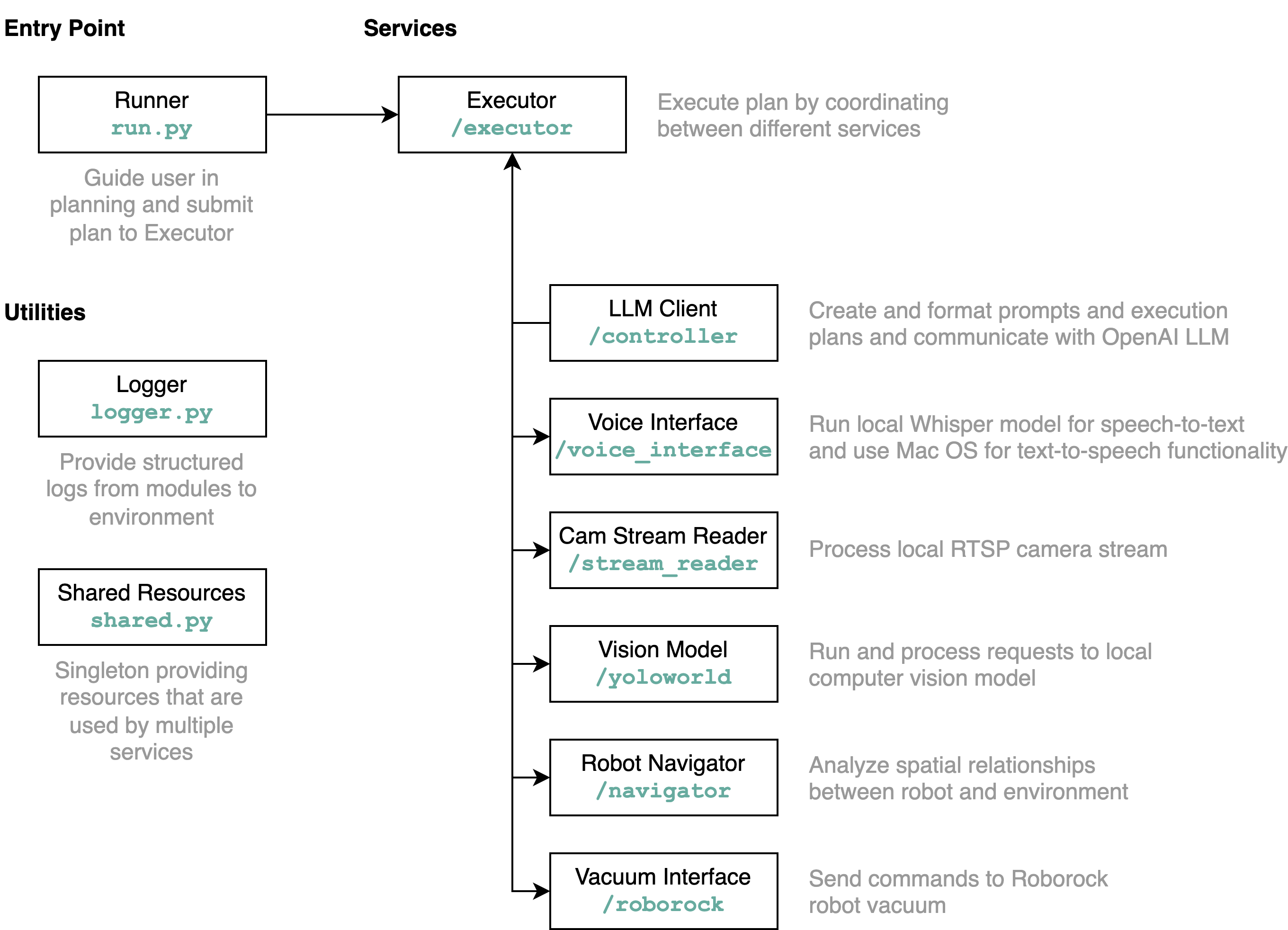
Lorsque vous exécutez le fichier run.py comme décrit ci-dessus, voici ce qui se passe et comment cela fonctionne :
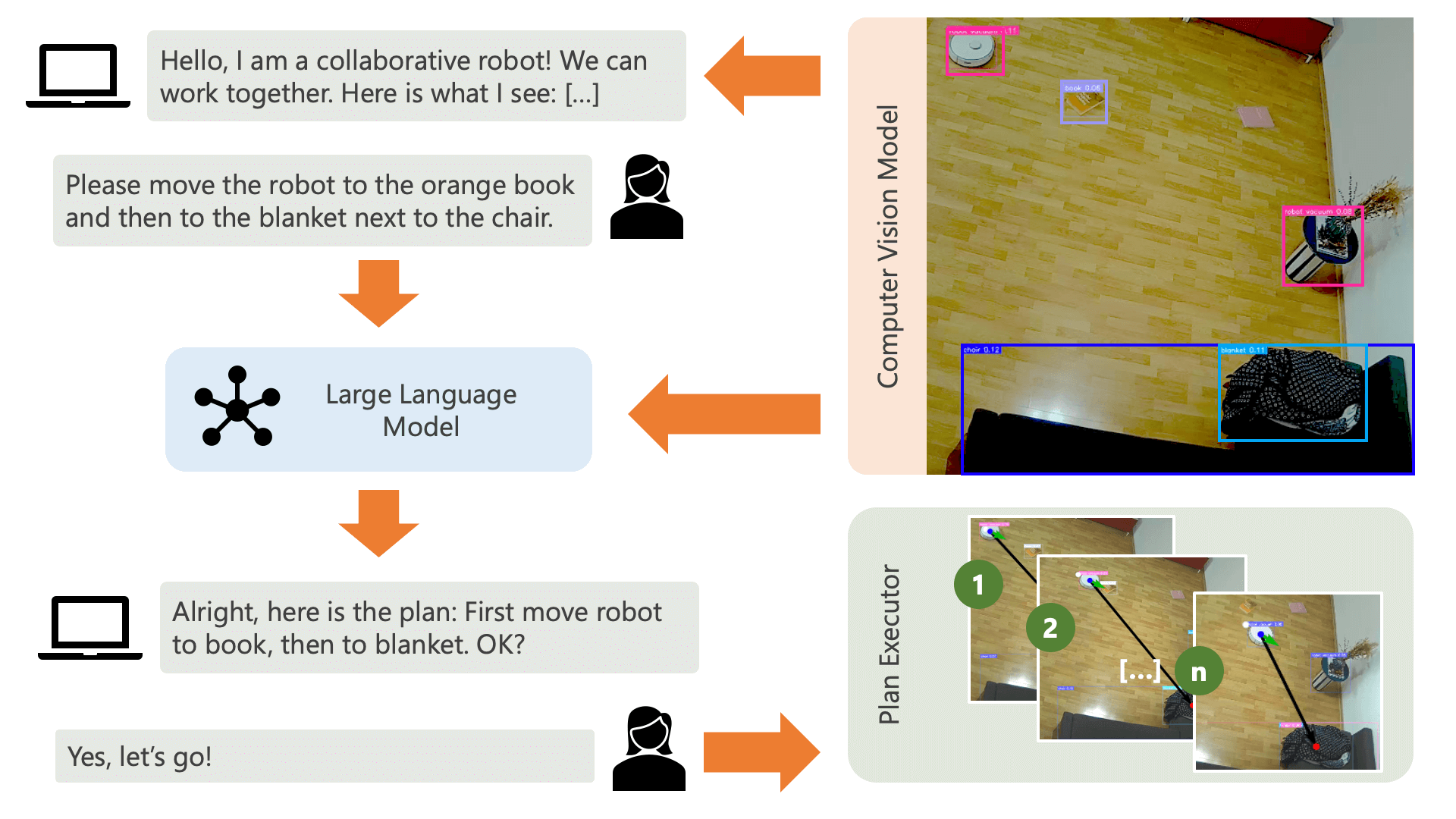
Le système accueille l'utilisateur avec un message audio et s'attend à ce qu'il dise au système ce qu'il souhaite faire. Par exemple, un utilisateur peut souhaiter que le robot récupère le café d’une personne assise sur une chaise jaune et le transporte vers une autre personne assise sur un canapé noir. Le système créerait alors un plan pour exécuter ces actions.
De quoi le système a-t-il besoin pour comprendre comment il peut réaliser ce que l’utilisateur souhaite faire ? Le système doit être conscient de son environnement et des actions qui peuvent être exécutées dans cet environnement. Ici, nous utilisons un modèle de vision par ordinateur avec détection d'objets pour fournir des informations sur l'environnement au système. L'aspirateur lui-même peut exécuter 3 actions simples : avancer, se tourner et ne rien faire. Une autre action dans l'environnement consiste à attendre que l'utilisateur effectue une certaine action.
Pour éviter toute confusion du côté de l’utilisateur, il est important que celui-ci sache comment l’IA perçoit son environnement. Par exemple, si un objet n’est pas reconnu par le modèle de vision par ordinateur, l’IA ne pourra pas l’inclure dans un plan. Il est également important que l'utilisateur soit conscient qu'il existe une incertitude quant à la reconnaissance des modèles. À l'aide du grand modèle de langage GPT-4o d'OpenAI avec l'invite de description, le système propose une explication de son environnement et la lit à l'utilisateur juste avant de lui demander ce qu'il veut que le système fasse.
Compte tenu des informations sur l'environnement et des commentaires de l'utilisateur concernant ce qu'il souhaite faire, le système peut alors élaborer un plan. Ici, nous demandons au LLM de proposer un plan, compte tenu des entrées de l'utilisateur et de la description de l'environnement. Vous pouvez trouver le modèle d'invite dans le répertoire controller . L'astuce intéressante ici est que le LLM n'est conscient de son environnement qu'à travers deux tableaux générés à partir des sorties du modèle de vision par ordinateur. Voici un exemple :
Item locations:
| id | label | position | confidence | color_rgb |
|-----:|:-------------|:----------------|-------------:|:----------------|
| 0 | robot vacuum | (122.0, 140.0) | 0.23 | [205, 206, 210] |
| 1 | blanket | (1697.0, 923.0) | 0.59 | [60, 72, 90] |
| 2 | chair | (532.5, 210.0) | 0.39 | [177, 177, 171] |
| 3 | chair | (160.0, 521.5) | 0.24 | [99, 99, 98] |
| 4 | book | (1216.5, 601.0) | 0.2 | [137, 141, 155] |
Distances:
| id | 0 | 1 | 2 | 3 | 4 |
|-----:|-----:|-----:|-----:|-----:|-----:|
| 0 | 0 | 1758 | 416 | 383 | 1187 |
| 1 | 1758 | 0 | 1365 | 1588 | 578 |
| 2 | 416 | 1365 | 0 | 485 | 787 |
| 3 | 383 | 1588 | 485 | 0 | 1059 |
| 4 | 1187 | 578 | 787 | 1059 | 0 |
Une fois que le LLM a traité l'invite de planification, il génère deux éléments : le raisonnement et le plan. Avant que le système ne procède à l'exécution du plan, il utilisera l'invite d'explication pour générer un bref résumé du plan dans le but d'obtenir la confirmation de l'utilisateur que le plan correspond à ce qu'il a demandé de faire. Cela s’inscrit dans l’esprit d’une approche humaine dans la boucle où nous opérons à partir du point de vue que dans un environnement physique réel et ouvert, les personnes peuvent potentiellement être blessées par les actions de l’IA. Il est donc raisonnable de demander l’intervention humaine. commentaires avant que l’IA ne procède à l’exécution d’un plan qu’elle a élaboré elle-même.
Une fois que l'utilisateur a confirmé, le système procède à l'exécution du plan. Un tel plan, tel que généré par le LLM, pourrait ressembler à ceci :
[
{ "action" : " MOVE " , "location" : [ 1216.5 , 601.0 ]},
{ "action" : " WAIT_UNTIL " , "task_fulfilled" : " Please place the book on the robot vacuum so that the robot can transport it to the chair. " },
{ "action" : " MOVE " , "location" : [ 532.5 , 210.0 ]},
{ "action" : " END " }
] À l'aide de l' executor , le système exécute le plan étape par étape. Pour réduire le temps de configuration requis, le contrôle du robot suit un algorithme simple, imprécis mais efficace :
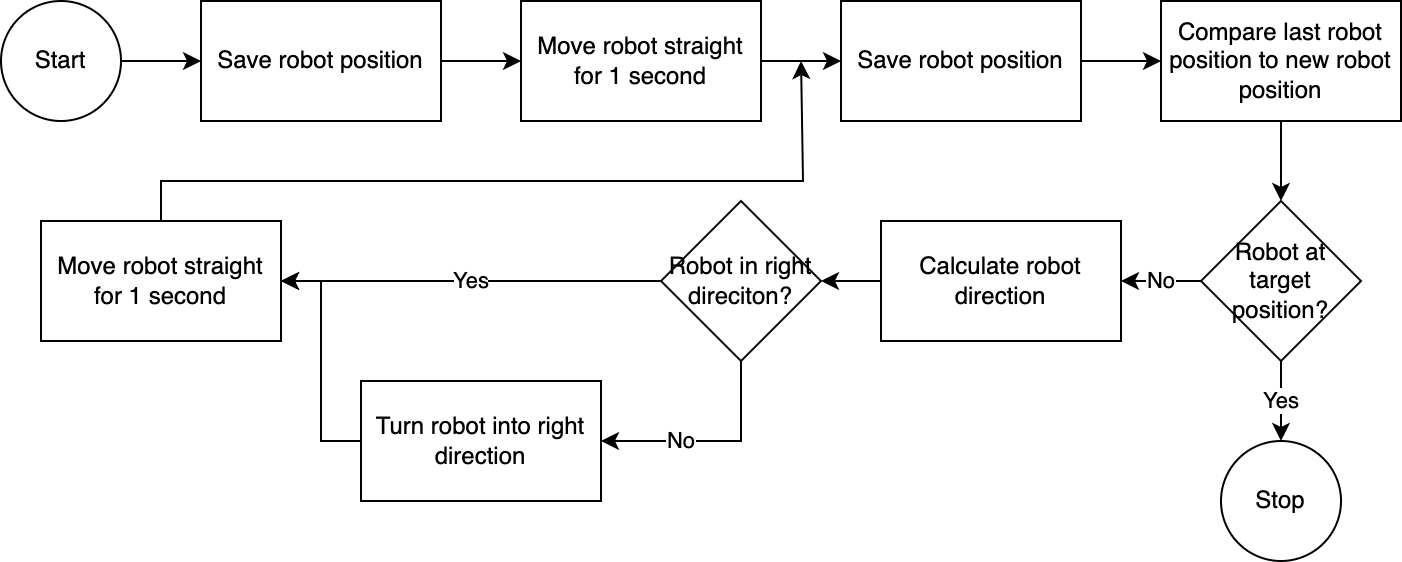
Le système de vision par ordinateur évalue la position du robot. Grâce au code du module navigator , la position du robot par rapport à sa position cible et par rapport à sa dernière position connue est analysée et comparée. Cette approche est imparfaite car la position et la distorsion de l'objectif de la caméra ne sont pas prises en compte. Les angles mesurés grâce à cette approche sont inexacts. Cependant, le système étant itératif, les erreurs sont fréquemment compensées. Cependant, il convient de noter que cela se fait au détriment de la vitesse. Le système est lent, car il faut du temps pour analyser l'image, calculer un chemin et informer le robot des prochaines étapes à suivre.
Une fois que le robot a atteint sa position cible, l'exécuteur passe à l'étape suivante du plan. Pour les actions impliquant une saisie de l'utilisateur, l'exécuteur utilisera la fonctionnalité de synthèse vocale et de synthèse vocale pour interagir avec l'utilisateur.
Dans ce système, nous utilisons principalement des services qui s'exécutent sur une machine ou un réseau local. L'exception est GPT-4o. Nous envoyons des données textuelles au modèle OpenAI via Internet. Les données textuelles comprennent les entrées utilisateur transcrites et un tableau des objets reconnus. La seule raison pour laquelle nous utilisons GPT-4o ici est qu'il s'agit de l'un des meilleurs modèles disponibles au moment du hackathon : nous pourrions également organiser un LLM local, puis travailler entièrement sans connexion à Internet, préservant ainsi la confidentialité de l'ensemble du flux de données. opérations.
Le modèle de vision par ordinateur inclus dans ce référentiel a été produit par le modèle YOLO-World dans un espace HuggingFace avec l'invite suivante : chair, book, candle, blanket, vase, bulb, robot vacuum, mug, glass, human . Si vous souhaitez reconnaître des objets supplémentaires, veuillez ajuster l'invite et télécharger un modèle ONNX via cet espace. Vous pouvez ensuite remplacer le modèle dans le répertoire src/yoloworld/models/rev0 .
Notez que pour extraire correctement le modèle, vous devez modifier manuellement les paramètres Nombre maximum de cases et seuil de score dans l'espace HuggingFace avant d'exporter le modèle.
Vous pouvez en savoir plus sur le modèle passionnant YOLO-World, construit sur les avancées récentes en matière de modélisation vision-langage, sur le site Web de YOLO-World.
Ce projet est publié sous licence MIT.
Ce référentiel n’est pas activement surveillé et il n’y a aucune intention de le développer – il s’agit avant tout d’un exercice d’apprentissage. Cependant, si vous vous sentez inspiré, n'hésitez pas à contribuer au projet en ouvrant un ticket GitHub ou une pull request.


