full stack on prem cv mlops
1.0.0
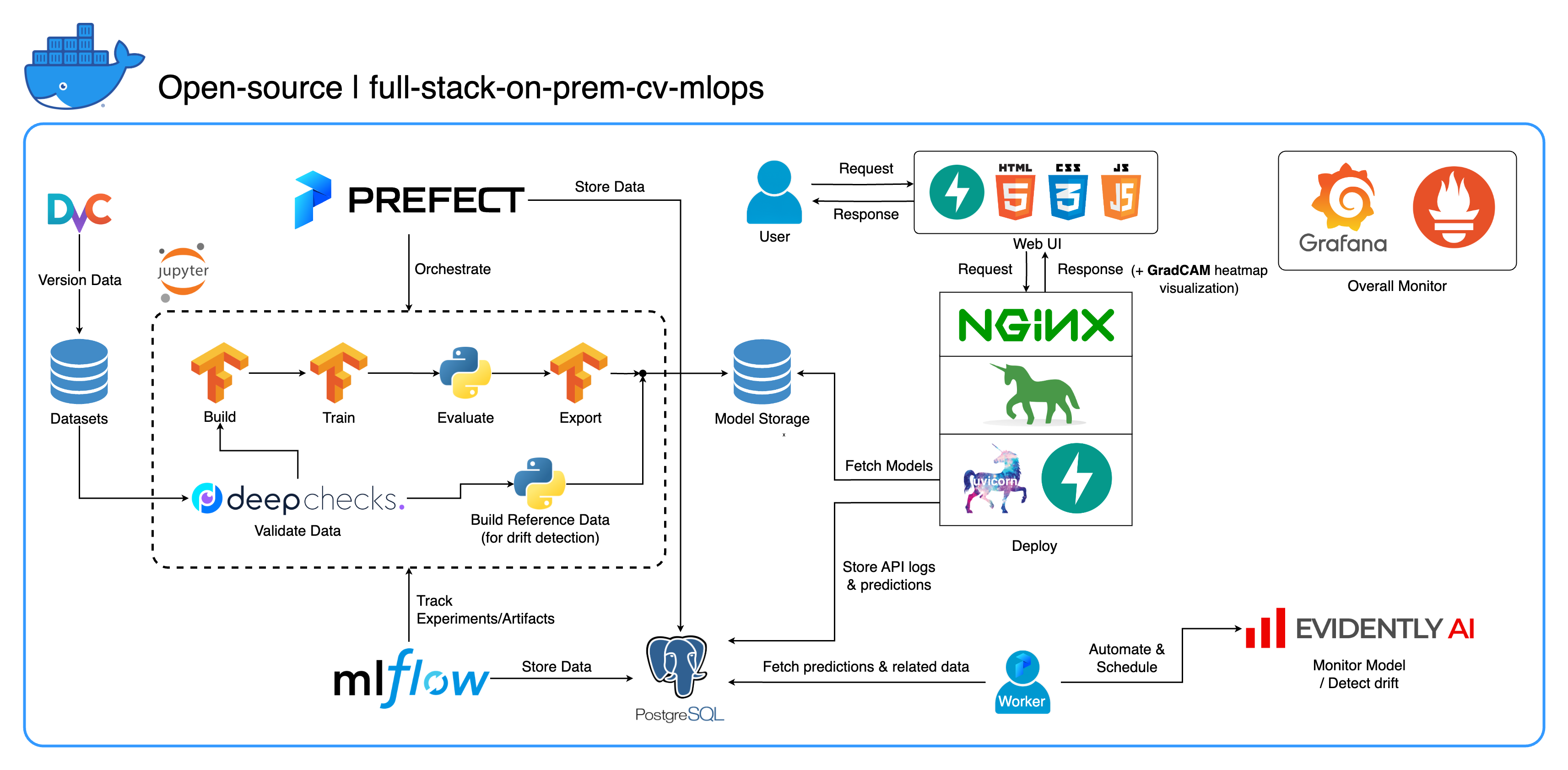
Bienvenue dans notre écosystème MLOps sur site complet conçu spécifiquement pour les tâches de vision par ordinateur, avec un accent principal sur la classification des images. Ce référentiel vous offre tout ce dont vous avez besoin, d'un espace de travail de développement dans Jupyter Lab/Notebook aux services de niveau production. La meilleure partie ? Il suffit de « 1 configuration et 1 commande » pour exécuter l’ensemble du système, de la construction du modèle au déploiement ! Nous avons intégré de nombreuses bonnes pratiques pour garantir l'évolutivité et la fiabilité tout en conservant la flexibilité. Alors que notre principal cas d'utilisation tourne autour de la classification d'images, la structure de notre projet peut facilement s'adapter à un large éventail de développements ML/DL, même en passant du sur site au cloud !
Un autre objectif est de montrer comment intégrer tous ces outils et les faire fonctionner ensemble dans un système complet. Si vous êtes intéressé par des composants ou des outils spécifiques, n'hésitez pas à sélectionner ce qui correspond aux besoins de votre projet.
L'ensemble du système est conteneurisé dans un seul fichier Docker Compose. Pour le configurer, il vous suffit de lancer docker-compose up ! Il s'agit d'un système entièrement sur site, ce qui signifie qu'il n'est pas nécessaire d'avoir un compte cloud, et cela ne vous coûtera pas un centime pour utiliser l'intégralité du système !
Nous vous recommandons fortement de regarder les vidéos de démonstration dans la section Vidéos de démonstration pour obtenir un aperçu complet et comprendre comment appliquer ce système à vos projets. Ces vidéos contiennent des détails importants qui peuvent être trop longs et pas assez clairs pour être abordés ici.
Démo : https://youtu.be/NKil4uzmmQc
Présentation technique approfondie : https://youtu.be/l1S5tHuGBA8
Ressources dans la vidéo :
Pour utiliser ce référentiel, vous n'avez besoin que de Docker. Pour référence, nous utilisons Docker version 24.0.6, build ed223bc et Docker Compose version v2.21.0-desktop.1 sur Mac M1.
Nous avons mis en œuvre plusieurs bonnes pratiques dans ce projet :
tf.data pour TensorFlowimgaug lib pour une plus grande flexibilité dans les options d'augmentation que les fonctions principales de TensorFlowos.env pour les configurations importantes ou au niveau du servicelogging au lieu d' print.env pour les variables dans docker-compose.ymldefault.conf.template pour Nginx pour appliquer avec élégance les variables d'environnement dans la configuration Nginx (nouvelle fonctionnalité dans Nginx 1.19)La plupart des ports peuvent être personnalisés dans le fichier .env à la racine de ce référentiel. Voici les valeurs par défaut :
123456789 )[email protected] , mot de passe : SuperSecurePwdHere )admin , mot de passe : admin ) Vous devez envisager de commenter ces lignes platform: linux/arm64 dans docker-compose.yml si vous n'utilisez pas d'ordinateur ARM (nous utilisons Mac M1 pour le développement). Sinon, ce système ne fonctionnera pas.
--recurse-submodules dans votre commande : git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdeploy sous le service jupyter dans docker-compose.yml et modifier l'image de base dans services/jupyter/Dockerfile de ubuntu:18.04 à nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (le texte est là dans le fichier, il vous suffit de commenter et décommenter) pour exploiter votre (vos) GPU. Vous devrez peut-être également installer nvidia-container-toolkit sur la machine hôte pour le faire fonctionner. Pour les utilisateurs Windows/WSL2, nous avons trouvé cet article très utile.docker-compose up ou docker-compose up -d pour détacher le terminal.datasets/animals10-dvc et suivez les étapes de la section Comment utiliser . http://localhost:8888/labcd ~/workspace/docker-compose.yml ) conda activate computer-viz-dlpython run_flow.py --config configs/full_flow_config.yamltasksflowsrun_flow.py à la racine du dépôt.start(config) dans votre fichier de flux. Cette fonction accepte la configuration en tant que dict Python, puis appelle essentiellement le flux spécifique dans ce fichier.datasets et ils doivent tous avoir la même structure de répertoires que celle de ce référentiel.central_storage sur ~/ariya/ doit contenir au moins 2 sous-répertoires nommés models et ref_data . Ce central_storage sert à stocker des objets en stockant tous les fichiers préparés à utiliser dans les environnements de développement et de déploiement. (C'est l'une des choses que vous pourriez envisager de passer à un service de stockage cloud au cas où vous souhaiteriez déployer sur le cloud et le rendre plus évolutif)Conventions IMPORTANTES à laquelle il faut être SUPER EXTRA ATTENTION si vous souhaitez changer (car ces éléments sont liés et utilisés dans différentes parties du système) :
central_storage -> À l'intérieur, il devrait y avoir models/ ref_data/ sous-répertoires<model_name>.yaml , <model_name>_uae , <model_name>_bbsd , <model_name>_ref_data.parquetcurrent_model_metadata_file et monitor_pool_namecomputer-viz-dl (valeur par défaut), avec tous les packages requis pour ce référentiel. Toutes les commandes/codes Python sont censés être exécutés dans ce Jupyter.central_storage fait office de stockage de fichiers central utilisé tout au long du développement et du déploiement. Il contient principalement des fichiers modèles (dont des détecteurs de dérives) et des données de référence au format Parquet. À la fin de l'étape de formation du modèle, les nouveaux modèles sont enregistrés ici et le service de déploiement extrait les modèles de cet emplacement. ( Remarque : il s'agit d'un endroit idéal pour remplacer les services de stockage cloud pour l'évolutivité.)model dans la configuration pour créer un modèle de classificateur. Le modèle est construit avec TensorFlow et son architecture est codée en dur dans tasks/model.py:build_model .dataset dans la configuration pour préparer un ensemble de données pour la formation. DvC est utilisé dans cette étape pour vérifier la cohérence des données sur le disque par rapport à la version spécifiée dans la configuration. S'il y a des modifications, il le reconvertit par programme vers la version spécifiée. Si vous souhaitez conserver les modifications, au cas où vous expérimenteriez l'ensemble de données, vous pouvez définir le champ dvc_checkout dans la configuration sur false afin que DvC ne fasse pas son travail.train dans la configuration pour créer un chargeur de données et démarrer le processus de formation. Les informations sur les expériences et les artefacts sont suivis et enregistrés avec MLflow . Remarque : le rapport de résultats (dans un fichier .html ) de DeepChecks est également téléchargé vers l'expérience de formation sur MLflow pour la convention.model dans le fichier config.central_storage (dans ce cas, il s'agit simplement de faire une copie vers l'emplacement central_storage . C'est l'étape que vous pouvez modifier pour télécharger des fichiers vers le stockage cloud)model/drift_detection dans la configuration.central_storage .central_storage .central_storage . (c'est une préoccupation abordée dans la vidéo de démonstration du didacticiel, regardez-la pour plus de détails)current_model_metadata_file stockant le nom du fichier de métadonnées du modèle terminé par .yaml et monitor_pool_name stockant le nom du pool de travail pour le déploiement du travailleur et des flux Prefect.cd par programme dans deployments/prefect-deployments et exécutez prefect --no-prompt deploy --name {deploy_name} en utilisant les entrées de la section deploy/prefect dans la configuration. Étant donné que tout est déjà dockerisé et conteneurisé dans ce référentiel, la conversion du service sur site vers le cloud est assez simple. Lorsque vous avez terminé de développer et de tester votre API de service, vous pouvez simplement créer services/dl_service en créant le conteneur à partir de son Dockerfile et en le transférant vers un service de registre de conteneurs cloud (AWS ECR, par exemple). C'est ça!
Remarque : Il existe un problème potentiel dans le code de service si vous souhaitez l'utiliser dans un environnement de production réel. J'en ai parlé dans la vidéo détaillée et je vous recommande de passer du temps à regarder la vidéo en entier. 
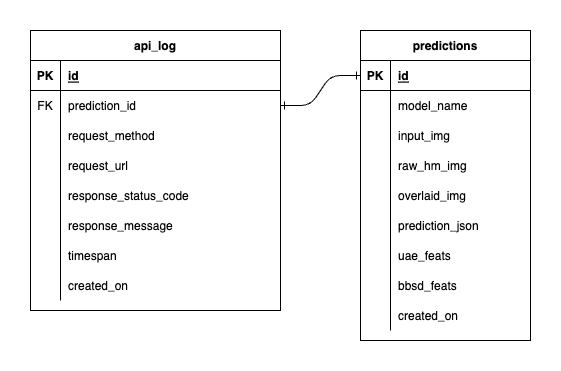
Nous avons trois bases de données dans PostgreSQL : une pour MLflow, une pour Prefect et une que nous avons créée pour notre service de modèle ML. Nous n'entrerons pas dans les deux premiers, car ils sont autogérés par ces outils. La base de données de notre service de modèle ML est celle que nous avons conçue nous-mêmes.
Pour éviter une complexité excessive, nous avons gardé les choses simples avec seulement deux tableaux. Les relations et les attributs sont présentés dans l'ERD ci-dessous. Essentiellement, notre objectif est de stocker des détails essentiels sur les demandes entrantes et les réponses de notre service. Tous ces tableaux sont créés et manipulés automatiquement, vous n'avez donc pas à vous soucier de la configuration manuelle.
À noter : input_img , raw_hm_img et overlaid_img sont des images codées en base64 stockées sous forme de chaînes. uae_feats et bbsd_feats sont des tableaux de fonctionnalités d'intégration pour nos algorithmes de détection de dérive.
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block , essayez export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0 puis réexécutez votre scénario.

