GenAI GeoGuesser
Devinez le nom du pays à partir des résultats générés par l'IA
Ce projet est une version différente du jeu populaire GeoGuessr dans lequel vous êtes placé à un endroit aléatoire du monde sur Google Maps et devez deviner l'emplacement pendant un compte à rebours. Ici, vous devrez deviner le nom du pays sur la base d'indices multimodaux générés par des modèles d'IA, vous pouvez choisir parmi 3 modalités, un texte qui vous donne une description textuelle du pays, une image qui vous donne une image qui ressemble au pays et un audio qui donne vous un extrait audio lié au pays.
Vous pouvez consulter une démo en ligne de cette application sur ses espaces HuggingFace. Cette démo était limitée à générer uniquement des indices d'image pour des raisons de performances.
Si vous souhaitez en savoir un peu plus sur le fonctionnement de ce projet et comment il a été créé, consultez l'article "Créer un GeoGuesser génératif basé sur l'IA".
Flux de travail
- Choisissez les modalités d'indice souhaitées.
- Choisissez le nombre d'indices pour chaque modalité.
- Cliquez sur le bouton "Démarrer le jeu".
- Regardez tous les indices et saisissez votre estimation dans le champ « Devine le pays ».
- Cliquez sur le bouton « Faire une supposition ».
Démo
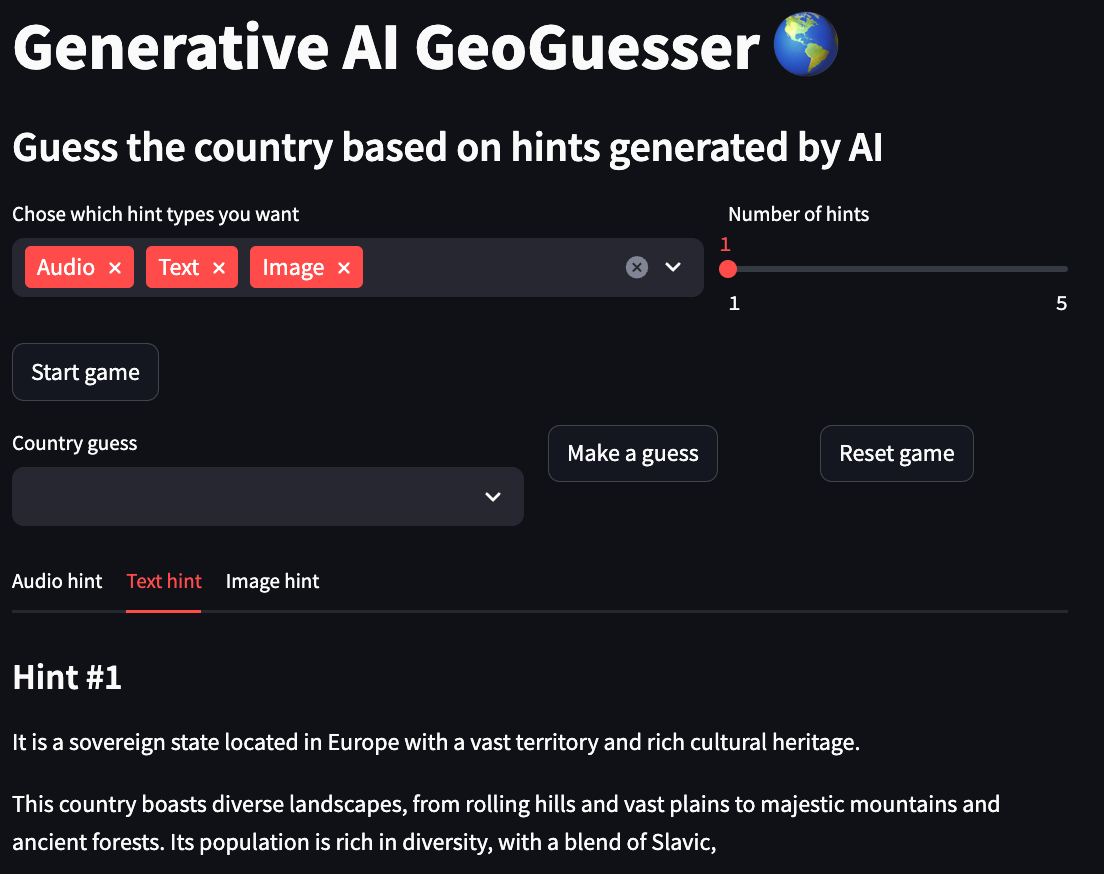
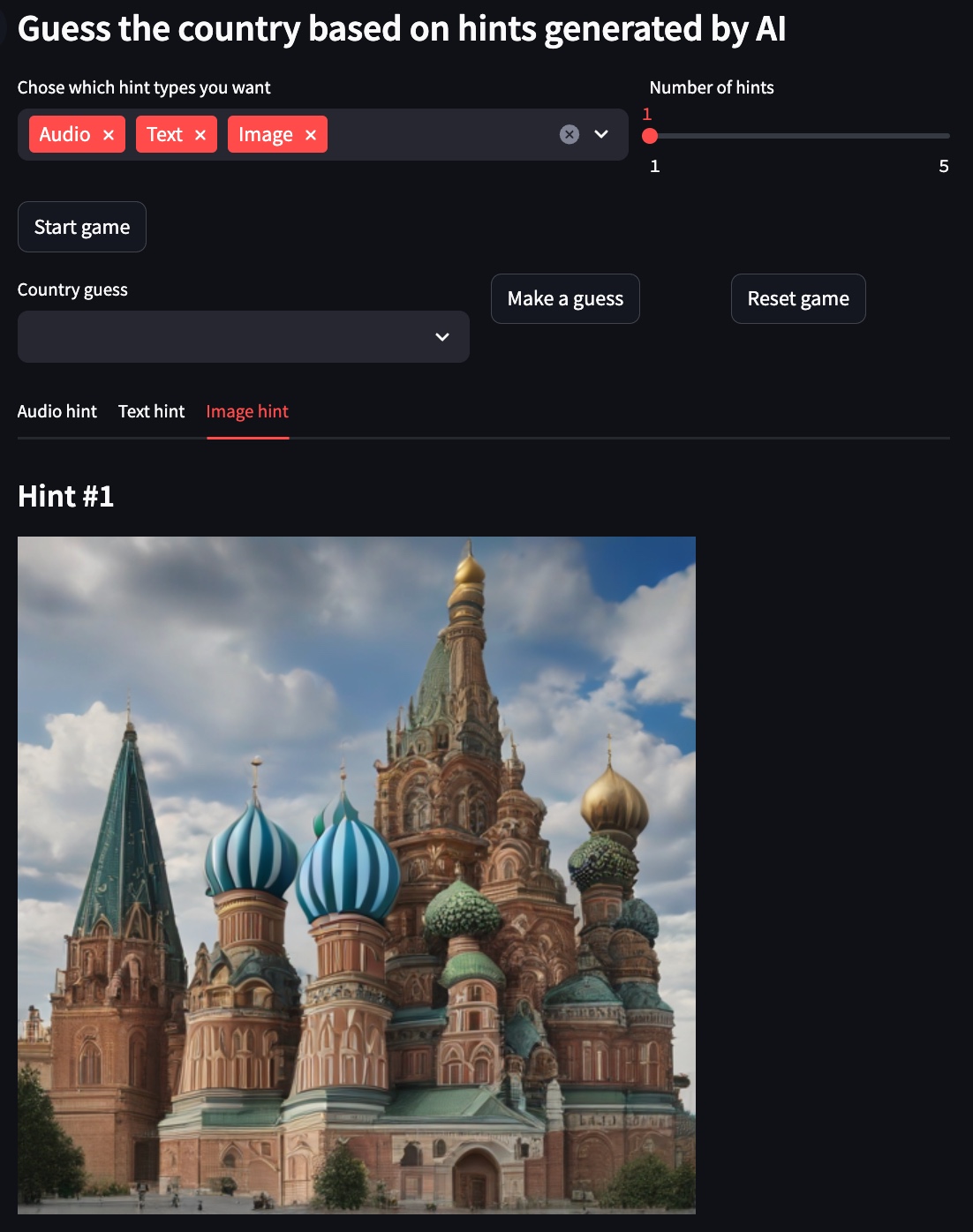
Pour les exemples ci-dessous, le pays choisi est la Russie .
Indice de texte
Indice d'image
Indice audio
Usage
L'approche recommandée pour utiliser ce référentiel est avec Docker, mais vous pouvez également utiliser un venv personnalisé, assurez-vous simplement d'installer toutes les dépendances.
Configurations
local:
to_use: true
text:
model_id: google/gemma-1.1-2b-it
device: cpu
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
image:
model_id: stabilityai/sdxl-turbo
device: mps
num_inference_steps: 1
guidance_scale: 0.0
audio:
model_id: cvssp/audioldm2-music
device: cpu
num_inference_steps: 200
audio_length_in_s: 10
vertex:
to_use: false
project: {VERTEX_AI_PROJECT}
location: {VERTEX_AI_LOCALTION}
text:
model_id: gemini-1.5-pro-preview-0409
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
- locale
- to_use : si le projet doit utiliser cette configuration d'installation
- texte
- model_id : modèle utilisé pour créer les astuces textuelles
- périphérique : périphérique utilisé par le modèle, généralement l'un des (cpu, cuda, mps)
- max_output_tokens : nombre maximum de jetons générés par le modèle
- température : la température contrôle le degré de caractère aléatoire dans la sélection des jetons. Des températures plus basses conviennent aux invites qui attendent une réponse vraie ou correcte, tandis que des températures plus élevées peuvent conduire à des résultats plus divers ou inattendus. Avec une température de 0, le jeton de probabilité la plus élevée est toujours sélectionné
- top_p : Top-p modifie la façon dont le modèle sélectionne les jetons pour la sortie. Les jetons sont sélectionnés du plus probable au moins jusqu'à ce que la somme de leurs probabilités soit égale à la valeur top-p. Par exemple, si les jetons A, B et C ont une probabilité de 0,3, 0,2 et 0,1 et que la valeur p supérieure est de 0,5, alors le modèle sélectionnera A ou B comme jeton suivant (en utilisant la température )
- top_k : Top-k modifie la façon dont le modèle sélectionne les jetons pour la sortie. Un top-k de 1 signifie que le jeton sélectionné est le plus probable parmi tous les jetons du vocabulaire du modèle (également appelé décodage glouton), tandis qu'un top-k de 3 signifie que le jeton suivant est sélectionné parmi les 3 jetons les plus probables ( en utilisant la température)
- image
- model_id : modèle utilisé pour créer les astuces d'image
- périphérique : périphérique utilisé par le modèle, généralement l'un des (cpu, cuda, mps)
- num_inference_steps : nombre d'étapes d'inférence pour le modèle
- guidance_scale : oblige la génération à mieux correspondre à l'invite, potentiellement au détriment de la qualité ou de la diversité de l'image
- audio
- model_id : modèle utilisé pour créer les astuces audio
- périphérique : périphérique utilisé par le modèle, généralement l'un des (cpu, cuda, mps)
- num_inference_steps : nombre d'étapes d'inférence pour le modèle
- audio_length_in_s : durée de l'indice audio
- sommet
- to_use : si le projet doit utiliser cette configuration d'installation
- projet : nom du projet utilisé par Vertex AI
- emplacement : emplacement du projet utilisé par Vertex AI
- texte
- model_id : modèle utilisé pour créer les astuces textuelles
- max_output_tokens : nombre maximum de jetons générés par le modèle
- température : la température contrôle le degré de caractère aléatoire dans la sélection des jetons. Des températures plus basses conviennent aux invites qui attendent une réponse vraie ou correcte, tandis que des températures plus élevées peuvent conduire à des résultats plus divers ou inattendus. Avec une température de 0, le jeton de probabilité la plus élevée est toujours sélectionné
- top_p : Top-p modifie la façon dont le modèle sélectionne les jetons pour la sortie. Les jetons sont sélectionnés du plus probable au moins jusqu'à ce que la somme de leurs probabilités soit égale à la valeur top-p. Par exemple, si les jetons A, B et C ont une probabilité de 0,3, 0,2 et 0,1 et que la valeur p supérieure est de 0,5, alors le modèle sélectionnera A ou B comme jeton suivant (en utilisant la température )
- top_k : Top-k modifie la façon dont le modèle sélectionne les jetons pour la sortie. Un top-k de 1 signifie que le jeton sélectionné est le plus probable parmi tous les jetons du vocabulaire du modèle (également appelé décodage glouton), tandis qu'un top-k de 3 signifie que le jeton suivant est sélectionné parmi les 3 jetons les plus probables ( en utilisant la température)
Commandes
Démarrez l'application de jeu.
Créez l'image Docker.
Appliquez des peluches et un formatage au code (nécessaire uniquement pour le développement).


