doc genius ai
v1.0

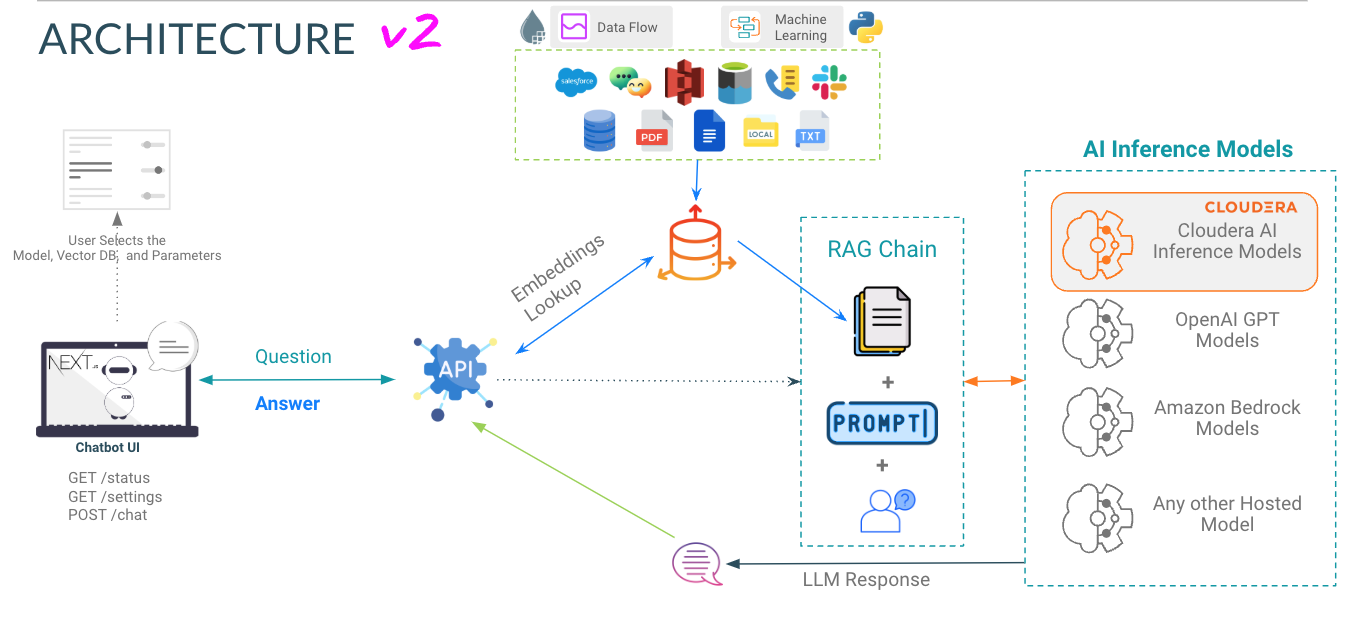
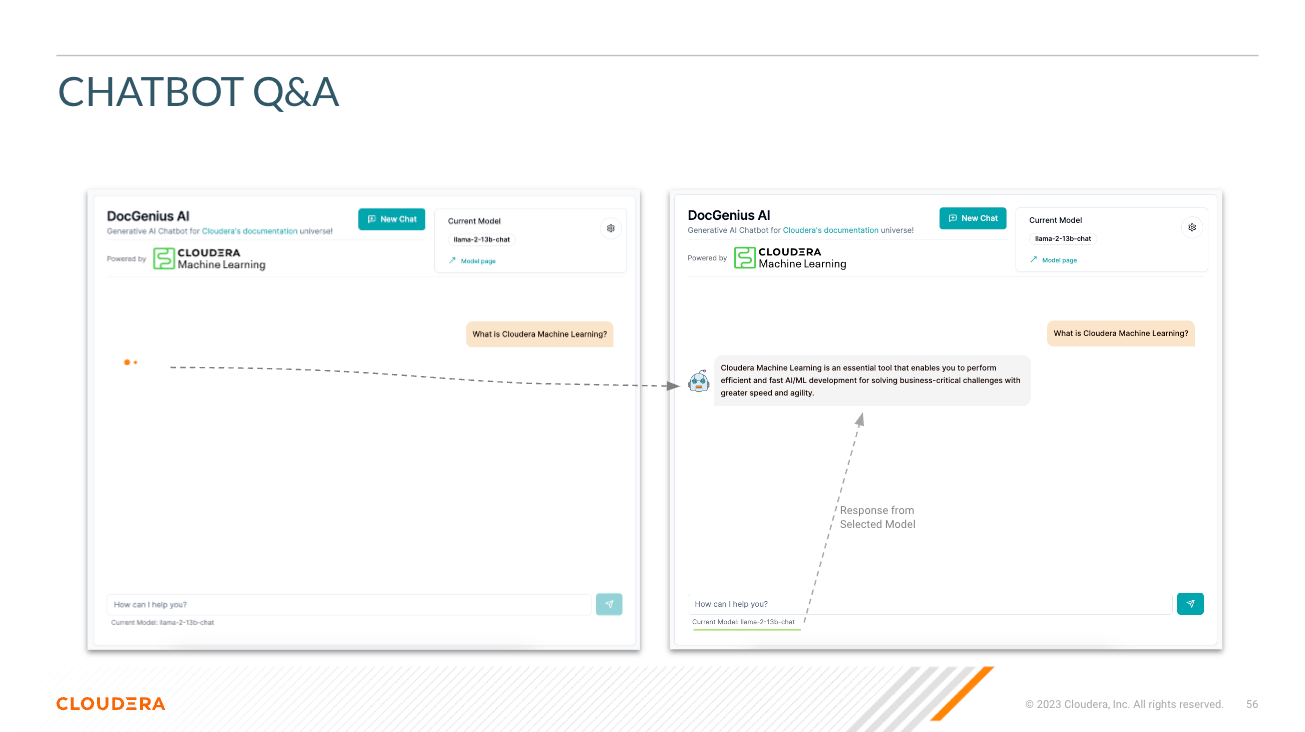
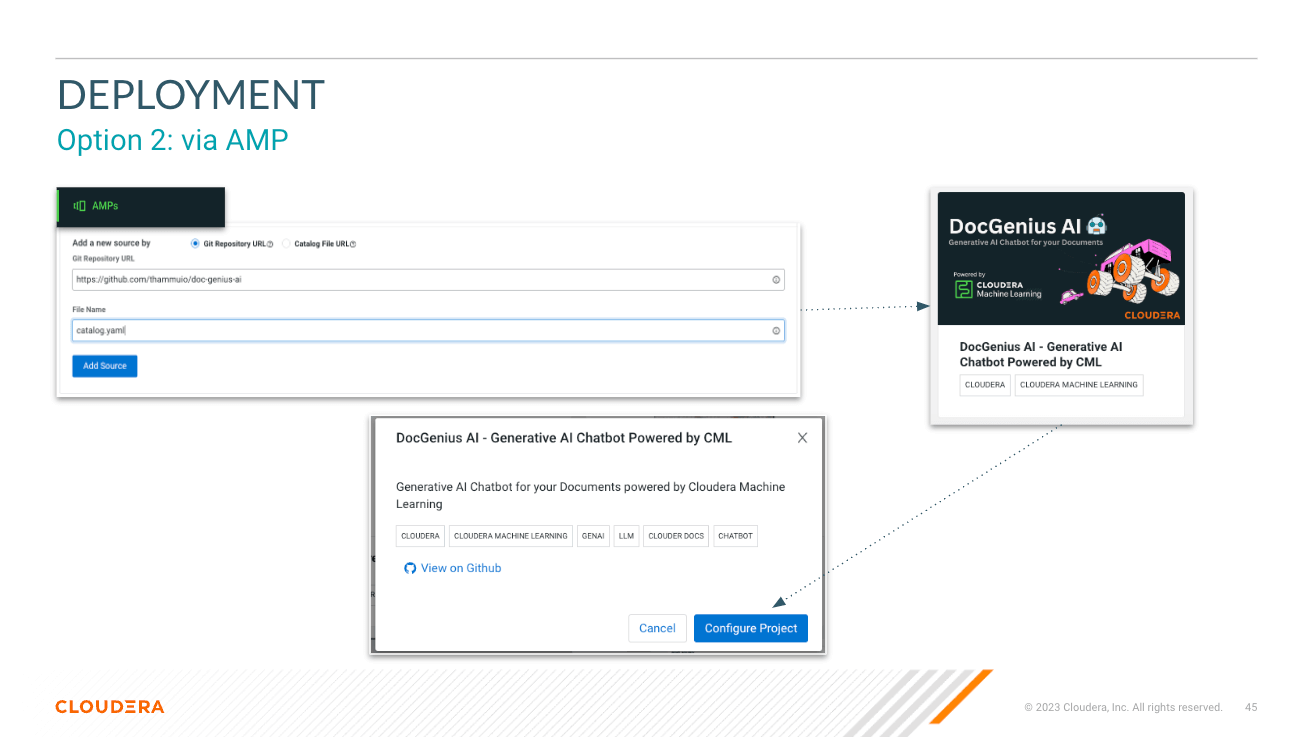
Sélectionner le modèle - Ici, l'utilisateur peut sélectionner le modèle de discussion de paramètre Llama3 70B ( llama-3-70b )
Sélectionnez la température (caractère aléatoire de la réponse) - Ici, l'utilisateur peut mettre à l'échelle le caractère aléatoire de la réponse du modèle. Des nombres inférieurs garantissent une réponse plus approximative et objective tandis que des nombres plus élevés encouragent la créativité du modèle.
Sélectionnez le nombre de jetons (durée de réponse) - Ici, plusieurs options ont été proposées. Le nombre de jetons utilisés par l'utilisateur est directement corrélé à la longueur de la réponse renvoyée par le modèle.
Question : Comme cela semble l'être ; c'est ici que l'utilisateur peut poser une question au modèle
Réponse - Il s'agit de la réponse générée par le modèle compte tenu du contexte dans votre base de données vectorielles. Notez que si la question ne peut pas correspondre au contenu de votre base de connaissances, vous risquez d'obtenir des réponses hallucinées.
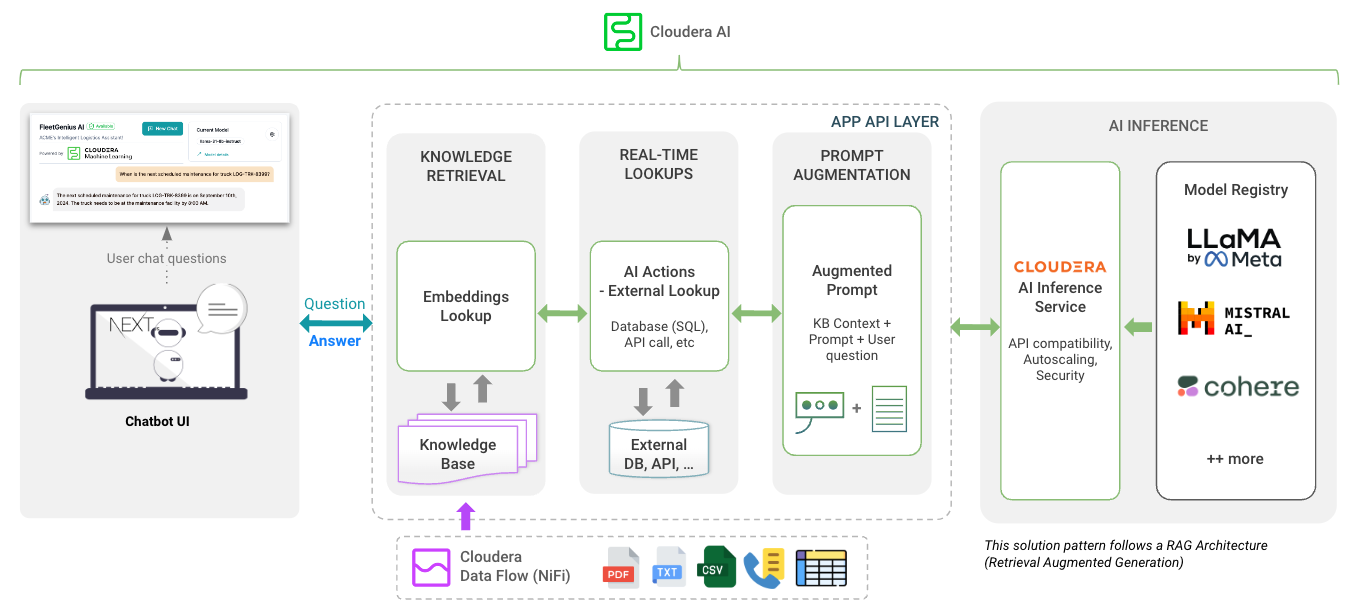
le répertoire app héberge la FastAPI pour vos LLM
Le répertoire chat-ui héberge le code de l'interface utilisateur de Chatbot.
Regardez les variables lors du déploiement de l'AMP. Reportez-vous à la documentation d'inférence Cloduera AI pour obtenir le point de terminaison et la clé d'inférence.
JupyterLab - Python 3.11 - GPU Nvidia
https://docs.cloudera.com/machine-learning/cloud/applied-ml-prototypes/topics/ml-amp-project-spec.html
Cela crée les charges de travail suivantes avec des besoins en ressources :
2 CPU, 16GB MEM2 CPU, 8GB MEM2 CPU, 1 GPU, 16GB MEM doc-genius-ai/
├── app/ # Application directory for API and Model Serving
│ └── [..subdirs..]
│ └── chatbot/ # has the model serving python files for RAG, Prompt, Fine-tuning models
│ └── main.py # main.py file to start the API
├── chat-ui/ # Directory for the chatbot UI in Next.js
│ └── [..subdirs..]
│ └── app.py # app.py file to serve build files in .next directory via Flask
├── pipeline/ # Pipeline directory for data processing or workflow pipelines and vector load
├── data/ # Data directory for storing datasets or data files or RAG KB
├── models/ # Models directory for LLMs / ML models
├── session/ # Scripts for CML Sessions and Validation Tasks
├── images/ # Directory for storing project related images
├── api.md # Documentation for the APIs
├── README.md # Detailed description of the project
├── .gitignore # Specifies intentionally untracked files to ignore
├── catalog.yaml # YAML file that contains descriptive information and metadata for the displaying the AMP projects in the CML Project Catalog.
├─ .project-metadata.yaml # Project metadata file that provides configuration and setup details
├── cdsw-build.sh # Script for building the Model dependencies
└── requirements.txt # Python dependencies for Model Serving
IMPORTANT : Veuillez lire ce qui suit avant de continuer. Cet AMP inclut ou dépend de certains progiciels tiers. Les informations sur ces progiciels tiers sont mises à disposition dans le fichier de notification associé à cette AMP. En configurant et en lançant cet AMP, vous provoquerez le téléchargement et l'installation de ces progiciels tiers dans votre environnement, dans certains cas, à partir de sites Web tiers. Pour chaque progiciel tiers, veuillez consulter le fichier de notification et les sites Web applicables pour plus d'informations, y compris les conditions de licence applicables.
Si vous ne souhaitez pas télécharger et installer des progiciels tiers, ne configurez pas, ne lancez pas et n'utilisez pas cet AMP. En configurant, en lançant ou en utilisant l'AMP, vous reconnaissez la déclaration précédente et acceptez que Cloudera n'est en aucun cas responsable des progiciels tiers.
Copyright (c) 2024 - Cloudera, Inc. Tous droits réservés.


