genkitx hnsw
1.0.0

Vous pouvez contribuer à ce plugin dans ce référentiel.
HNSW est Vector Database Hierarchical Navigable Small World (HNSW). Les graphiques HNSW comptent parmi les index les plus performants pour la recherche de similarité vectorielle. HNSW est une technologie extrêmement populaire qui produit à maintes reprises des performances de pointe avec des vitesses de recherche ultra rapides et un rappel fantastique. en savoir plus sur HNSW.
Vous pouvez préférer cette base de données vectorielles si vous préférez
Avec cela, vous pouvez obtenir une génération d'augmentation de récupération (RAG) très performante dans l'IA générative, de sorte que vous n'avez pas besoin de créer votre propre modèle d'IA ou de recycler le modèle d'IA pour obtenir plus de contexte ou de connaissances, vous pouvez plutôt ajouter une couche supplémentaire de contexte afin que votre modèle d'IA peut comprendre plus de connaissances que ce que le modèle d'IA de base connaît. ceci est utile si vous souhaitez obtenir plus de contexte ou plus de connaissances basées sur des informations ou des connaissances spécifiques que vous définissez.
Vous disposez d'une application ou d'un site Web de restaurant, vous pouvez ajouter des informations spécifiques sur vos restaurants, votre adresse, la liste des menus avec son prix et d'autres éléments spécifiques, de sorte que lorsque votre client demande quelque chose à l'IA à propos de votre restaurant, votre IA puisse y répondre avec précision. . cela peut supprimer vos efforts pour créer un chatbot, mais vous pouvez utiliser une IA générative enrichie de connaissances spécifiques.
Exemple de conversation :
You : Quelle est la liste de prix de mon restaurant dans la ville de Surabaya ?
AI : Tarifs :
Avant d'installer le plugin, assurez-vous que les conditions préalables suivantes sont installées :
npm install -g typescript )Pour installer ce plugin, vous pouvez exécuter cette commande ou avec votre gestionnaire de packages préféré
npm install genkitx-hnswCe plugin a plusieurs fonctionnalités comme ci-dessous :
HNSW Indexer Utilisé pour créer un index vectoriel basé sur toutes les données et informations que vous avez fournies. cet index vectoriel sera utilisé comme référence de connaissances du HNSW Retriever.HNSW Retriever Utilisé pour obtenir une réponse générative de l'IA avec le modèle Gemini comme base enrichie de connaissances et de contexte supplémentaires basés sur votre index vectoriel. Il s'agit d'une utilisation du flux de plug-in Genkit pour enregistrer des données dans un magasin de vecteurs avec HNSW Vector Store, Gemini Embedder et Gemini LLM.
Préparez vos données ou documents dans un dossier 
Importez le plugin dans votre projet Genkit
import { hnswIndexer } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
hnswIndexer({ apiKey: " GOOGLE_API_KEY " })
]
}) ; Ouvrez Genkit UI et choisissez le plugin enregistré HNSW Indexer
Exécuter le flux avec les paramètres requis d'entrée et de sortie
dataPath : Le chemin de vos données et autres documents à apprendre par l'IAindexOutputPath : votre chemin de sortie attendu pour votre index Vector Store qui est traité en fonction des données et des documents que vous avez fournis 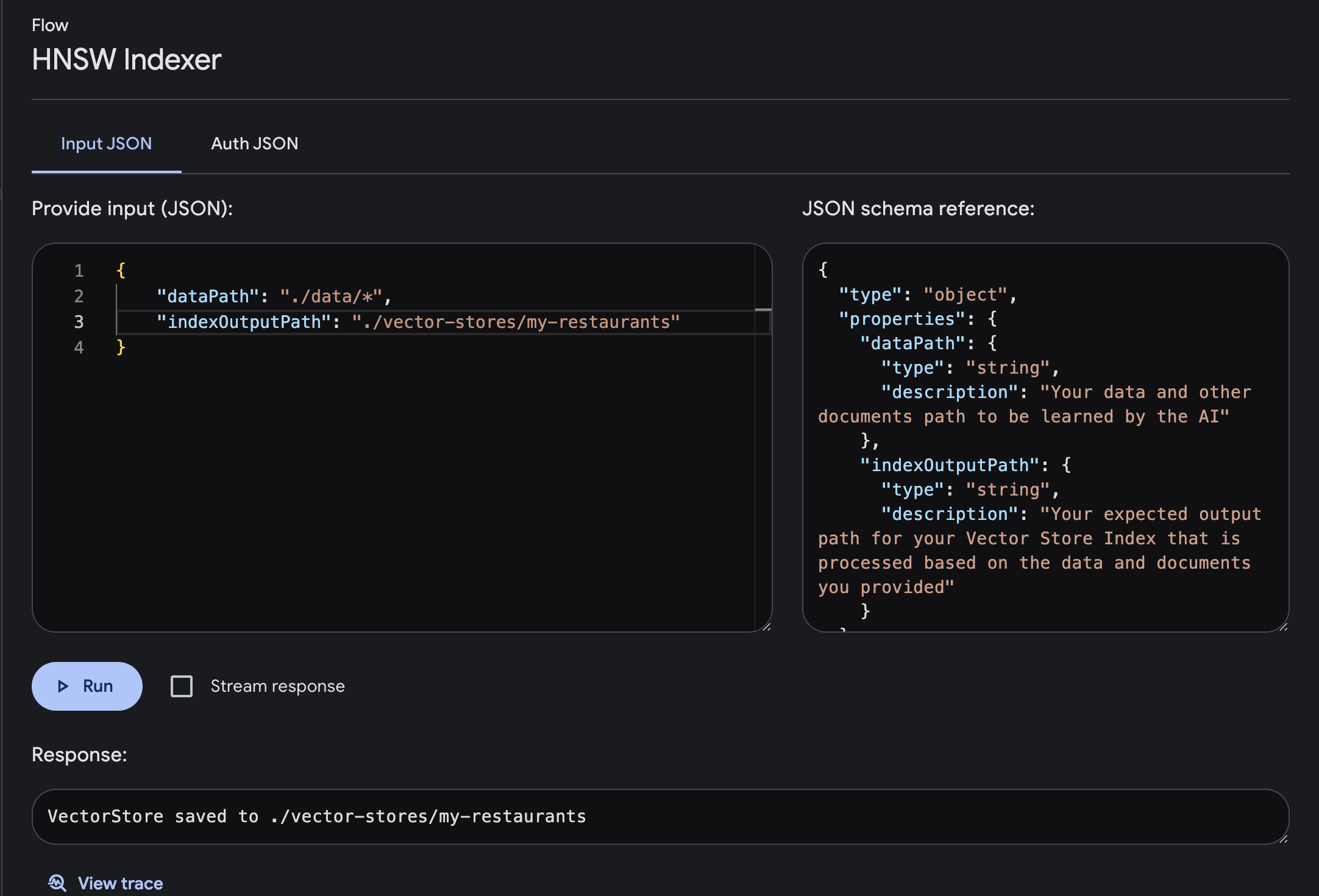
 Le magasin de vecteurs sera enregistré dans le chemin de sortie défini. cet index sera utilisé pour le processus de génération d'invite avec le plugin HNSW Retriever. vous pouvez continuer l'implémentation en utilisant le plugin HNSW Retriever
Le magasin de vecteurs sera enregistré dans le chemin de sortie défini. cet index sera utilisé pour le processus de génération d'invite avec le plugin HNSW Retriever. vous pouvez continuer l'implémentation en utilisant le plugin HNSW Retriever
chunkSize: number Quantité de données traitées à la fois. C'est comme diviser une grande tâche en morceaux plus petits pour la rendre plus gérable. En définissant la taille du fragment, nous décidons de la quantité d'informations que l'IA gère en une seule fois, ce qui peut affecter à la fois la vitesse et la précision du processus d'apprentissage de l'IA.
default value : 12720
separator: string Lors de la création d'un index vectoriel, il s'agit d'un symbole ou d'un caractère utilisé pour séparer différentes informations dans les données d'entrée. Il aide l’IA à comprendre où se termine une unité de données et où commence une autre, lui permettant ainsi de traiter et d’apprendre plus efficacement des données.
default value : "n"
Il s'agit d'une utilisation du flux de plug-in Genkit pour traiter votre invite avec le modèle Gemini LLM enrichi d'informations ou de connaissances supplémentaires et spécifiques au sein de la base de données vectorielles HNSW que vous avez fournie. avec ce plugin, vous obtiendrez une réponse LLM avec un contexte spécifique supplémentaire.
Importez le plugin dans votre projet Genkit
import { googleAI } from " @genkit-ai/googleai " ;
import { hnswRetriever } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
googleAI (),
hnswRetriever({ apiKey: " GOOGLE_API_KEY " })
]
}) ;Assurez-vous d'importer le plugin GoogleAI pour le fournisseur de modèles Gemini LLM, actuellement ce plugin ne prend en charge que Gemini, fournira bientôt plus de modèles !
Ouvrez Genkit UI et choisissez le plugin enregistré HNSW Retriever Exécutez le flux avec le paramètre requis
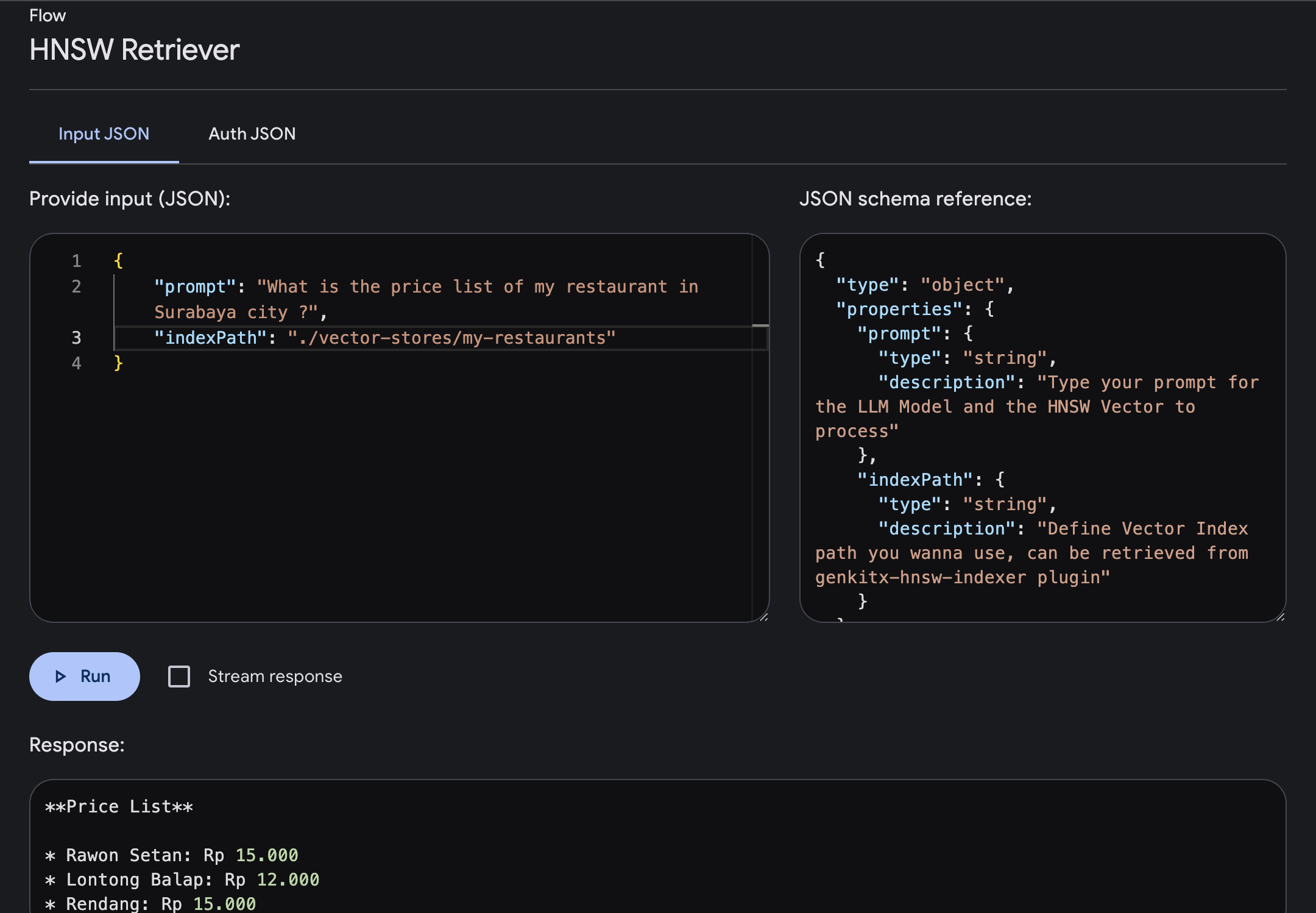
prompt : Tapez votre invite où vous obtiendrez des réponses avec un contexte plus enrichi en fonction du vecteur que vous avez fourni.indexPath : définissez le chemin de l'index vectoriel du dossier que vous souhaitez utiliser comme référence de connaissances, où vous obtenez ce chemin de fichiers à partir du plugin HNSW Indexer.Dans cet exemple, essayons de poser des questions sur les informations de la liste de prix d'un restaurant de la ville de Surabaya, où elles ont été fournies dans l'index vectoriel.
Nous pouvons taper l'invite et l'exécuter. Une fois le flux terminé, vous obtiendrez une réponse enrichie de connaissances spécifiques basées sur votre index vectoriel.
temperature: number de température contrôle le caractère aléatoire de la sortie générée. Des températures plus basses aboutissent à une sortie plus déterministe, le modèle sélectionnant le jeton le plus probable à chaque étape. Des températures plus élevées augmentent le caractère aléatoire, permettant au modèle d'explorer des jetons moins probables, générant potentiellement un texte plus créatif mais moins cohérent.
default value : 0.1
maxOutputTokens: number Ce paramètre spécifie le nombre maximum de jetons (mots ou sous-mots) que le modèle doit générer en une seule étape d'inférence. Cela permet de contrôler la longueur du texte généré.
default value : 500
topK: number restreint les choix du modèle aux K jetons les plus probables à chaque étape. Cela permet d'éviter que le modèle prenne en compte des jetons trop rares ou improbables, améliorant ainsi la cohérence du texte généré.
default value : 1
topP: number L'échantillonnage Top-P, également connu sous le nom d'échantillonnage nucléaire, prend en compte la distribution de probabilité cumulée des jetons et sélectionne le plus petit ensemble de jetons dont la probabilité cumulée dépasse un seuil prédéfini (souvent noté P). Cela permet une sélection dynamique du nombre de jetons considérés à chaque étape, en fonction de la probabilité des jetons.
default value : 0
stopSequences: string[] Ce sont des séquences de jetons qui, une fois générées, signalent au modèle d'arrêter de générer du texte. Cela peut être utile pour contrôler la longueur ou le contenu de la sortie générée, par exemple pour garantir que le modèle arrête de générer après avoir atteint la fin d'une phrase ou d'un paragraphe.
default value : []
Licence : Apache 2.0


