opensquare
1.0.0

Intelligence des médias sociaux open source et OSINT
Explorer les documents »
Voir la démo · Signaler un bug · Demander une fonctionnalité
Il y a eu 150 millions de nouveaux utilisateurs de médias sociaux entre avril 2022 et avril 2023, soit une augmentation de 3,2 % d'une année sur l'autre par rapport aux 4,8 milliards d'utilisateurs de médias sociaux actuels dans le monde, ce qui représente 59,9 % de la population mondiale et 92,7 % de tous les utilisateurs d'Internet. Les entreprises utilisent les médias sociaux pour obtenir des informations sur divers sujets : le sentiment des utilisateurs à l'égard des produits, les produits forts et les produits faibles, les événements, tout ce qui s'adresse à leurs clients. Pour les analystes du renseignement et les chercheurs en sciences sociales, qui sont leurs clients ? Les décideurs politiques, le citoyen ordinaire, tous les acteurs de la société. L'utilisateur de ce projet, son client, sont les analystes et chercheurs en intelligence et en sciences sociales. À mesure que la technologie progresse sur la courbe de l'innovation et que la société continue d'utiliser de plus en plus les médias sociaux comme place publique, les chercheurs peuvent utiliser ces données disponibles à des fins utiles, pour en tirer des enseignements, ralentir ou arrêter des incidents nuisibles, pour aider la société, pour élaborer des plans. sur la base d’un consensus public, mieux informer les décideurs politiques de ce dont leurs électeurs ont besoin et veulent (et mieux planifier des solutions qui augmentent la satisfaction de leurs clients). Alors qu’il devient de plus en plus difficile pour les gouvernements de comprendre et d’exécuter des solutions qui servent mieux leurs citoyens, l’idée d’une gouvernance adaptative, axée sur des structures décisionnelles décentralisées, devient inévitable. Non seulement les informations tirées des médias sociaux peuvent aider les décideurs politiques, mais elles peuvent également aider les entités et les groupes de gouvernance adaptative à mieux servir leurs populations. Ce produit est destiné à l'analyste du renseignement, au spécialiste des sciences sociales, au spécialiste des données et à ceux qui souhaitent améliorer la qualité de notre existence humaine grâce à une analyse publique approfondie et à des solutions basées sur les données.
(retour en haut)
(retour en haut)
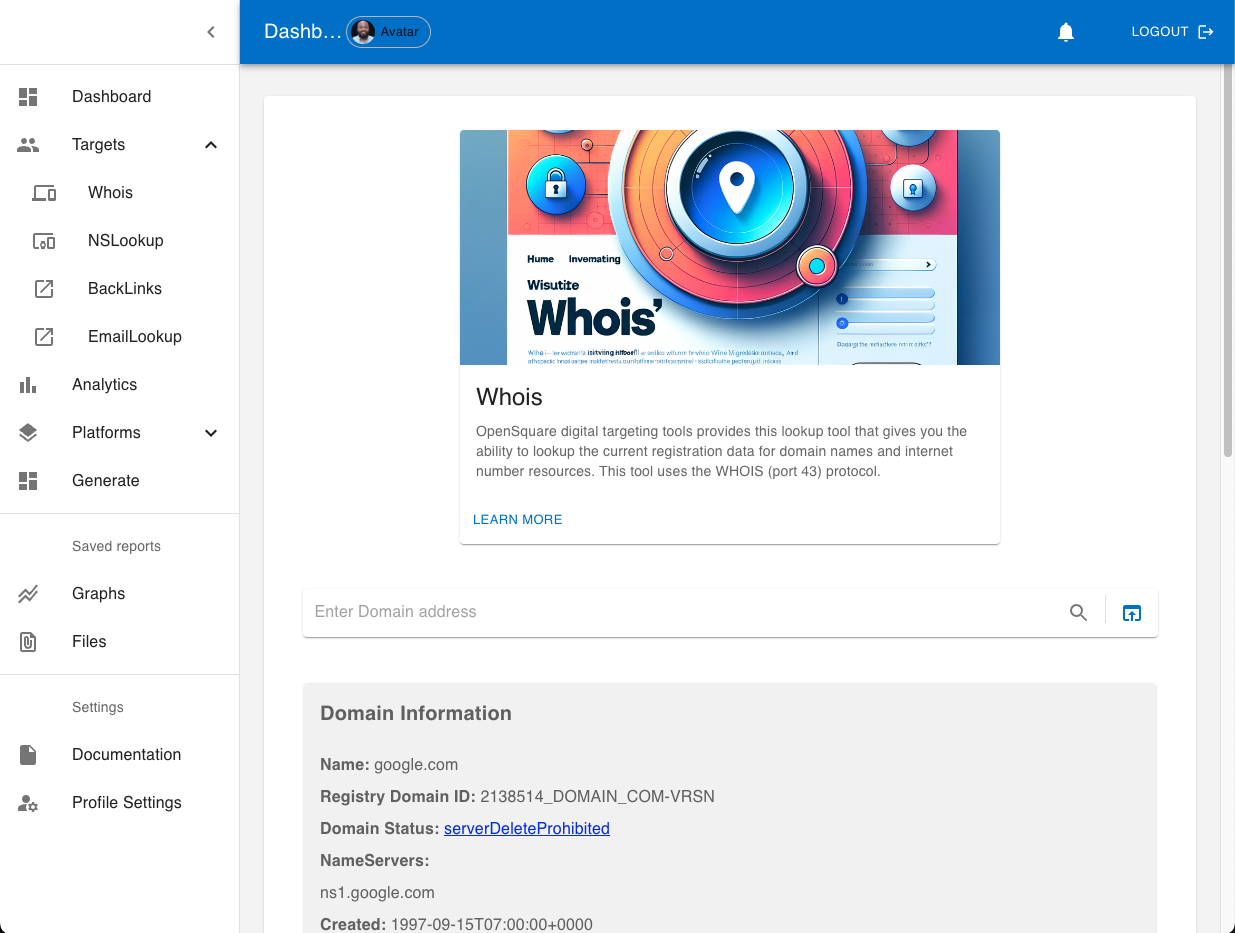
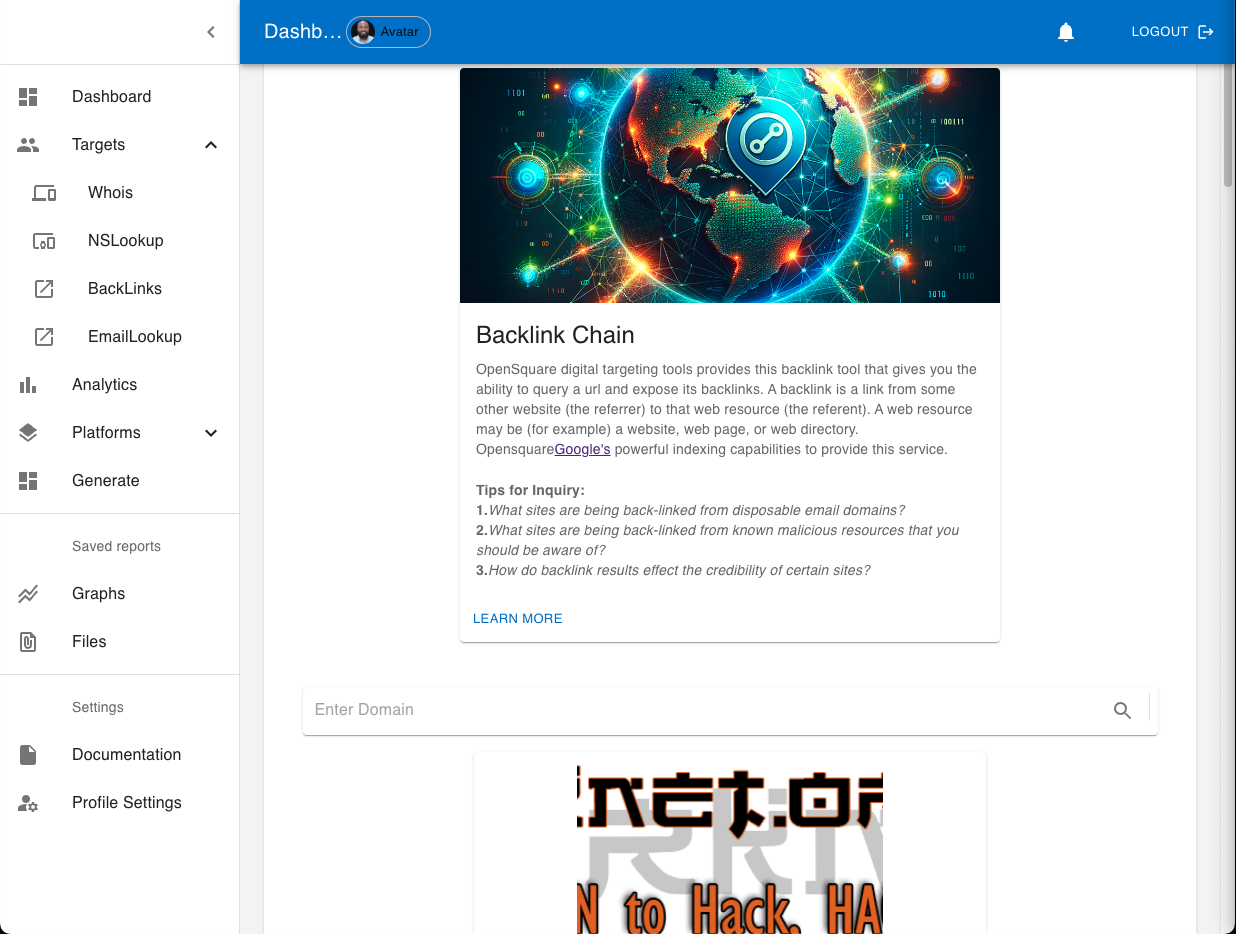
Outre d'autres fonctionnalités, OpenSquare fournit des outils de ciblage Digit Footprint, certains utilisant des méthodes OSINT bien connues telles que Backlinks, NSLookup et Whois. Disposer d’une suite générale d’outils en un seul endroit peut augmenter la productivité des utilisateurs. Naviguez facilement entre les espaces de travail du tableau de bord et utilisez la sortie d’un outil comme entrée pour un autre.
Expérimentez la génération de rapports et de documents avec GenAI. Utilisez les informations et les images que vous avez collectées pour générer des rapports qui aboutissent à un avantage décisionnel. Demandez à notre système d'IA de générer pour vous des images en fonction du contexte de l'information et de résumer les détails clés. Augmentez la productivité et réduisez considérablement la vitesse de fourniture d'informations clés aux décideurs à l'aide d'interfaces cliquables et déplaçables.
Opensquare utilise Whisper : un modèle de reconnaissance vocale à usage général. Il est formé sur un vaste ensemble de données audio diverses et constitue également un modèle multitâche capable d'effectuer une reconnaissance vocale multilingue, une traduction vocale et une identification de la langue.
À l'aide des API disponibles d'Opensquare, vous pouvez interroger et transcrire des vidéos YouTube. Les transcriptions indiqueront l’heure et les propriétés du texte. Cette API est utilisée pour créer des fonctionnalités sur Opensquare, mais sera également disponible au public sous forme d'API facile à utiliser.
opensquare/api/youtube/en/transcribe?videoId=l9AzO1FMgM8
produit :
[ { "time": "0.0", "text": "Java, a high-level multi-paradigm programming language famous for its ability to compile" }, { "time": "5.2", "text": "to platform independent bytecode." }, { "time": "7.44", "text": "It was designed by James Gosling in 1990 at Sun Microsystems." }, { "time": "11.700000000000001", "text": "One of its first demonstrations was the Star 7 PDA, which gave birth to the Java mascot" },... ]
Pour obtenir une copie locale opérationnelle, suivez ces exemples d’étapes simples.
Linux
Java17
java --versionMaven 3.9 ou supérieur
mvn --versionCloner le dépôt
git git clone https://[email protected]/intelligence-opensent/opensentop.gitInstaller le profil par défaut des dépendances (y compris NPM)
mvn clean installExécuter Webpack en mode développement
npm run watch
Vous aurez besoin de certains fichiers de configuration - n'hésitez pas à m'envoyer une requête ping pour ceux-ci.
(retour en haut)
Ce projet utilise le Frontend-Maven-Plugin d'Eirik Sletteberg qui permet à notre équipe d'utiliser un seul plugin pour les versions frontend et backend dans un seul dépôt. Ce plugin est capable de diverses configurations, mais la configuration utilisée dans ce projet est minimale en utilisant uniquement Webpack et quelques configurations pour installer Node et NPM. L'essentiel de cette utilisation provient de la création du bundle du projet qui est intégré à l'aide d'un <script> à la racine de l'application React (mode React typique) exposé dans le fichier index.html du dossier de ressources Springboot.
<body>
<div id='root'>
</div>
<script src="built/bundle.js"></script>
</body>
Webpack créera un bundle de construction contenant la source de l'entrée de l'application React dans app.js sous le package js de ce projet.
entry: path.resolve(__dirname, "/src/main/js/app.js"),
devtool: 'inline-source-map',
cache: true,
mode: 'development',
output: {
path: __dirname,
filename: 'src/main/resources/static/built/bundle.js'
},
(retour en haut)
Si vous utilisez Kafka, vous devriez consulter la documentation. Assurez-vous d’abord que le serveur zoo-keeper est en cours d’exécution avant d’exécuter le serveur kafka. Parfois, le dossier zookeeper configs /config n'est pas configuré correctement. Si vous en avez besoin, assurez-vous que clientPort=2181 est défini dans zookeeper.properties et pour garantir que les ports ne sont pas en conflit, assurez-vous que admin.serverPort=8083 est défini dans le même fichier. Nous voulons également nous assurer que bootstrap.servers=9092 est configuré dans producer.properties : il s'agit d'une liste de courtiers utilisés pour amorcer les connaissances sur le reste du format de cluster, ce qui est important pour la configuration Springboot de ce projet ci-dessous :
@Bean
public ConsumerFactory<String, OpenSentTaskStatus> consumerFactory() {
Map<String, Object> configurationProperties = new HashMap<>();
configurationProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configurationProperties.put(ConsumerConfig.GROUP_ID_CONFIG, "group_id");
configurationProperties.put(JsonDeserializer.TRUSTED_PACKAGES, "*");
configurationProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configurationProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
configurationProperties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
return new DefaultKafkaConsumerFactory<>(configurationProperties);
}
@Bean
public ProducerFactory<String, OpenSentTaskStatus> producerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return new DefaultKafkaProducerFactory<>(props);
}
Consultez les problèmes ouverts pour une liste complète des fonctionnalités proposées (et des problèmes connus).
(retour en haut)
(retour en haut)
Wali Morris - @LinkedIn - [email protected]
Lien du projet : GitHub
(retour en haut)
(retour en haut)


