ai vinyl specialist
1.0.0
David est un spécialiste des disques vinyles. Vous pouvez lui demander une recommandation ou des informations supplémentaires sur l'un des disques de votre collection Discogs. David se fera un plaisir de vous aider.
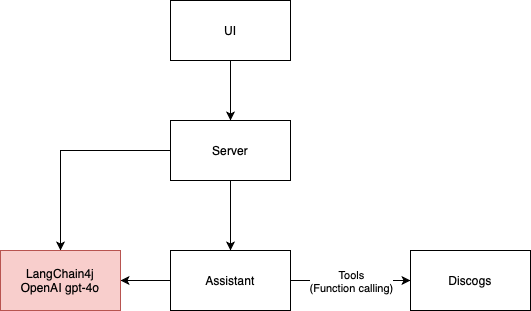
Cette application LLM est un exemple simple d'agent conversationnel qui utilise l'API Discogs pour fournir des informations sur les disques vinyles. Il se compose de 4 éléments de base principaux :
Il utilise actuellement LangChain4j comme framework avec GPT-4o comme moteur d'assistant d'IA, mais il peut être facilement adapté pour utiliser d'autres moteurs.
L'architecture d'application du diagramme ci-dessous est appliquée par le framework ArchUnit via des tests dans la classe ArchitectureTest.
L'interface utilisateur de ce projet a été développée à l'aide de l'invite suivante :
I need the code for an HTML 5 page that contains an input field for a Discogs username
and a text area for inserting prompts for the application to send to AI agents.
Above the text area there should be the space in which the AI responses are displayed, in the ChatGPT style
Le code HTML5 généré par GitHub Copilot a donné les visuels initiaux de l'interface utilisateur que j'ai ensuite modifié pour ajouter la connexion websocket et la logique pour envoyer et recevoir des messages de l'assistant IA. J'ai trouvé que c'était une approche très rapide du prototypage. Ensuite, je suis passé à des composants plus robustes d'ant-design, notamment pro-chat.
Je voulais au départ utiliser lama3. Le modèle llama3 ne prend actuellement pas en charge les outils (juin 2024). Cela signifie que l'assistant IA ne peut pas collecter le nom d'utilisateur Discogs et récupérer lui-même la collection de disques. Nous sommes passés à GPT-4o afin que David puisse demander des informations Discogs et supprimer le besoin de formulaires.
Certains LLM ne sont pas aussi intelligents que d’autres. Même si le modèle Mistral 7b prend en charge les outils, je n'ai pas pu en obtenir de bonnes réponses. Il ne passerait même pas mes tests d'intégration. Avec cela, je n'ai pas pu réaliser un LLM avec des outils gratuitement.
Les hallucinations sont pénibles. Je commence mon voyage dans RAG pour le minimiser. Puisque David opère dans le domaine de la musique, Wikipédia est la première base de connaissances qui vient à l’esprit de RAG. Peut-être que je peux exploiter l'API MediaWiki pour rechercher des pages musicales pertinentes pour la conversation. Pour l'instant, j'utilise uniquement la recherche Google et cela aide parfois mais certainement pas assez pour le coût que cela ajoute avec les jetons.
Tester l'application LLM était un défi. J'ai fait plus de tests d'intégration que d'habitude. Cela a conduit à un cycle de développement plus lent. De plus, la nature probabiliste de l’assistant IA rend difficile le test de l’application de manière déterministe.
Dans le monde LLM, les tests unitaires impliquent d'inviter un modèle d'IA au lieu de simplement appeler une unité de code. Lorsque vous utilisez un modèle basé sur le cloud, l'exécution de tests unitaires a un coût. J'ai également expérimenté l'utilisation d'un deuxième agent d'IA pour m'aider à affirmer les résultats de l'IA principale. C'est une approche prometteuse puisque nous pouvons faire des assertions sémantiques, et pas seulement du traitement de chaînes. Le compromis ici est que cela génère également des coûts et augmente le risque d'erreurs de probabilité introduites par les LLM.
Vous devez disposer d'une clé API OpenAI valide pour exécuter cette application.
./gradlew bootRun pour démarrer l'application.http://localhost:8080 dans votre navigateur pour interagir avec l'assistant IA.

