content dicovery platform gcp
1.0.0
Ce référentiel contient le code et l'automatisation nécessaires pour créer une plate-forme simple de découverte de contenu optimisée par les modèles fondamentaux de VertexAI. Cette plate-forme devrait être capable de capturer le contenu des documents (initialement Google Docs) et, avec ce contenu, de générer des vecteurs d'intégration à stocker dans une base de données vectorielles alimentée par VertexAI Matching Engine. Plus tard, ces intégrations peuvent être utilisées pour contextualiser une question générale d'un consommateur externe et avec ce contexte demande une réponse à un modèle fondamental VertexAI pour obtenir une réponse.
La plate-forme peut être séparée en 4 composants principaux : la couche de service d'accès, le pipeline de capture de contenu, le stockage de contenu et les LLM. La couche de services permet aux consommateurs externes d'envoyer des demandes d'ingestion de documents, puis d'envoyer des demandes sur le contenu inclus dans les documents précédemment ingérés. Le pipeline de capture de contenu est chargé de capturer le contenu du document dans NRT, d'extraire les intégrations et de mapper ces intégrations avec du contenu réel qui peut ensuite être utilisé pour contextualiser les questions des utilisateurs externes dans un LLM. Le stockage du contenu est séparé en 3 objectifs différents, le réglage fin du LLM, la correspondance des intégrations en ligne et le contenu fragmenté, chacun d'eux étant géré par un système de stockage spécialisé et dans le but général de stocker les informations nécessaires aux composants de la plateforme pour mettre en œuvre l'ingestion et la requête. utilise des cas. Enfin, la plateforme utilise 2 LLM spécialisés pour créer des intégrations en temps réel à partir du contenu du document ingéré et un autre chargé de générer les réponses demandées par les utilisateurs de la plateforme.
Tous les composants décrits précédemment sont implémentés à l'aide des services GCP accessibles au public. Pour les énumérer : Cloud Build, Cloud Run, Cloud Dataflow, Cloud Pubsub, Cloud Storage, Cloud Bigtable, Vertex AI Matching Engine, Vertex AI Fundational models (intégrations et text-bison), ainsi que Google Docs et Google Drive comme informations de contenu. sources.
L'image suivante montre comment les différents composants de l'architecture et des technologies interagissent entre eux.
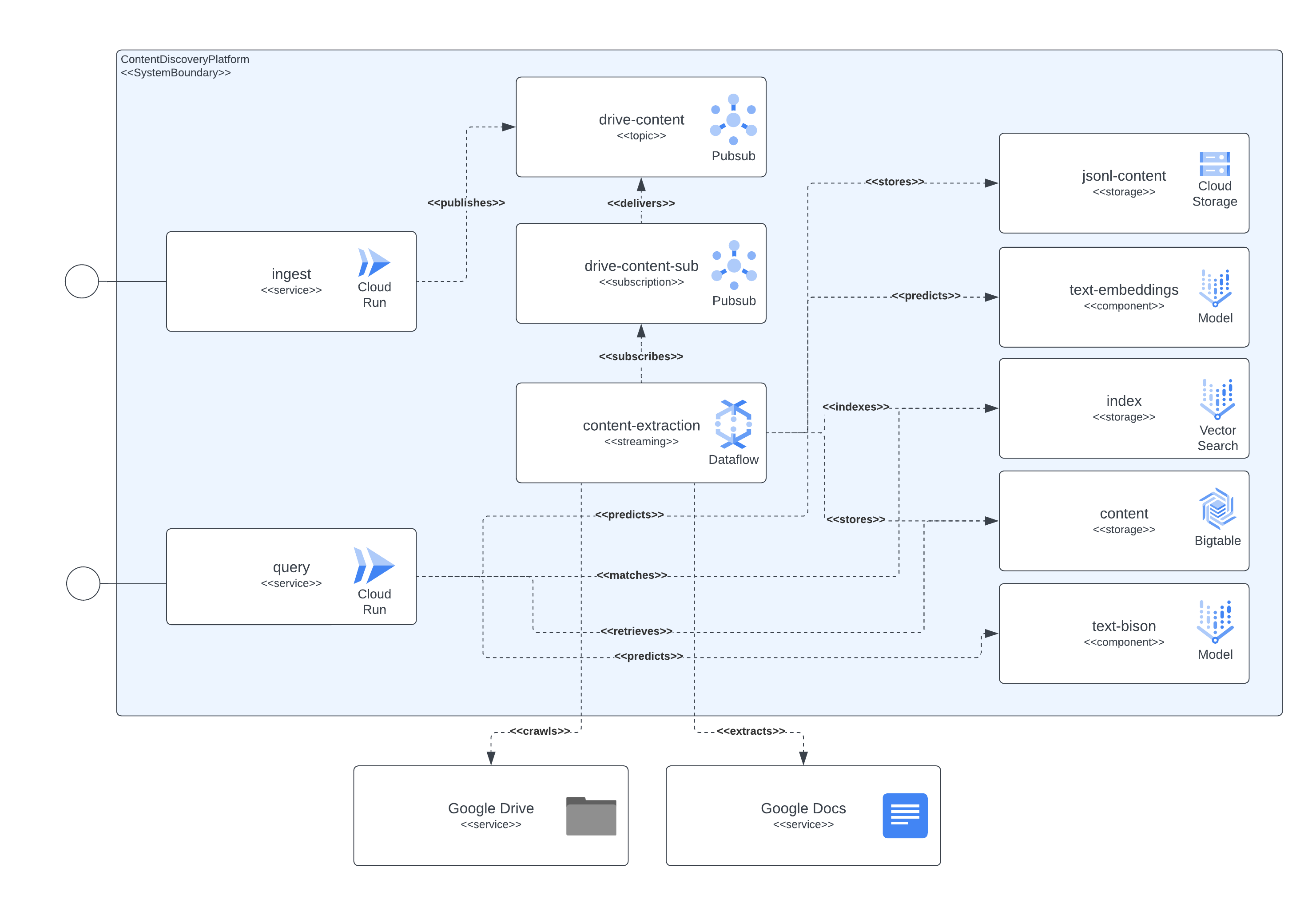
Cette plateforme utilise Terraform pour la configuration de tous ses composants. Pour ceux qui ne disposent actuellement pas de support natif, nous avons créé des wrappers null_resource. Ce sont de bonnes solutions de contournement, mais ils ont tendance à avoir des bords très rugueux, alors soyez conscient des erreurs potentielles.
Le déploiement complet à ce jour (juin 2023) peut prendre jusqu'à 90 minutes, le principal responsable étant les composants liés au Matching Engine qui prennent la majorité de ce temps pour être créés et facilement disponibles. Avec le temps, ces durées d’exécution prolongées ne feront que s’améliorer.
L'installation doit être exécutable à partir des scripts inclus dans le référentiel.
Quelques conditions doivent être remplies pour déployer cette plateforme :
Afin de déployer tous les composants dans GCP, nous devons construire, créer une infrastructure et plus tard déployer les services et les pipelines.
Pour y parvenir, nous avons inclus le script start.sh qui orchestre essentiellement les autres scripts inclus pour atteindre l'objectif de déploiement complet.
Nous avons également inclus un script cleanup.sh chargé de détruire l'infrastructure et de nettoyer les données collectées.
Dans des cas normaux, les documents Google Workspace seront créés sur la même organisation qui héberge le projet où s'exécute le pipeline d'ingestion de contenu. Ainsi, afin d'accorder des autorisations à ces documents, en ajoutant le compte de service qui exécute le pipeline aux documents ou au dossier de documents. , devrait suffire.
En cas de besoin d'accéder à des documents ou des dossiers existant en dehors de l'organisation du projet, une étape supplémentaire doit être complétée. Une fois l'infrastructure configurée, le processus de déploiement imprimera des instructions pour accorder au compte de service qui exécute le pipeline d'extraction de contenu les autorisations pour usurper l'identité de l'accès aux documents Google Workspace via une délégation à l'échelle du domaine. Les informations pour suivre les étapes peuvent être consultées ici : https://developers.google.com/workspace/guides/create-credentials#optional_set_up_domain-wide_delegation_for_a_service_account
La solution expose quelques ressources via GCP CloudRun et API Gateway, qui peuvent être utilisées pour interagir pour les requêtes d'ingestion de contenu et de découverte de contenu. Dans tous les exemples, nous utilisons la chaîne symbolique <service-address> , qui doit être remplacée par l'URL fournie par CloudRun ( backend_service_url de la sortie Terraform) ou API Gateway ( sevice_url de la sortie Terraform) une fois le déploiement du service terminé.
Lorsque vous avez besoin d'interactions CORS, les points de terminaison API Gateway peuvent être utilisés lorsque vous cherchez à compléter un protocole de contrôle en amont. CloudRun ne prend actuellement pas en charge les commandes OPTIONS non authentifiées, mais les chemins exposés via API Gateway les prennent en charge.
Ce service est capable d'ingérer des données provenant de documents hébergés dans Google Drive ou de requêtes autonomes en plusieurs parties contenant un identifiant de document et le contenu du document codé en binaire.
L'ingestion de Google Drive se fait en envoyant une requête HTTP similaire à l'exemple suivant
$ > curl -X POST -H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /ingest/content/gdrive
-d $' {"url":"https://docs.google.com/document/d/somevalid-googledocid"} ' Cette demande indiquera la plate-forme pour récupérer le document à partir de l' url fournie et si le compte de service qui exécute l'ingestion dispose d'autorisations d'accès au document, il en extraira le contenu et stockera les informations pour l'indexation, la découverte et la récupération ultérieures.
La requête peut contenir l'url d'un document Google ou d'un dossier Google Drive, dans ce dernier cas l'ingestion explorera le dossier pour les documents à traiter. Il est également possible d'utiliser les urls de propriété qui attendent un JSONArray de valeurs string , chacune d'entre elles étant une URL de document Google valide.
Dans le cas où vous souhaitez inclure le contenu d'un article, d'un document ou d'une page accessible localement par le client d'ingestion, l'utilisation du point de terminaison multipart devrait être suffisante pour ingérer le document. Voir la commande curl suivante à titre d'exemple, le service s'attend à ce que le champ du formulaire documentId soit défini pour identifier et indexer de manière univoque le contenu :
$ > curl -H " Authorization: Bearer $( gcloud auth print-identity-token ) "
-F documentId= < somedocid >
-F documentContent=@ < /some/local/directory/file/to/upload >
https:// < service-address > /ingest/content/multipartCe service expose la capacité de requête aux utilisateurs de la plateforme, en envoyant des requêtes de texte naturel aux services et étant donné qu'il existe déjà des index de contenu après ingestion dans la plateforme, le service reviendra avec des informations résumées par le modèle LLM.
L'interaction avec le service peut se faire via un échange REST, similaire à ceux pour la partie ingestion, comme le montre l'exemple suivant.
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": ""} '
| jq .
# response from service
{
"content": "VertexAI foundational models are a set of pre-trained models that can be used to build and deploy machine learning applications. They are available in a variety of languages and frameworks, and can be used for a variety of tasks, including natural language processing, computer vision, and recommendation systems.nnVertexAI foundational models are a good choice for Generative AI applications because they provide a starting point for building these types of applications. They can be used to quickly and easily create models that can generate text, images, and other types of content.nnIn addition, VertexAI foundational models are scalable and can be used to process large amounts of data. They are also reliable and can be used to create applications that are available 24/7.nnOverall, VertexAI foundational models are a powerful tool for building Generative AI applications. They provide a starting point for building these types of applications, and they can be used to quickly and easily create models that can generate text, images, and other types of content.",
" sourceLinks " : [
]
}Il existe un cas particulier ici, où aucune information n'est encore stockée pour un sujet particulier, si ce sujet tombe dans le paysage GCP, le modèle agira en tant qu'expert puisque nous configurons une invite qui l'indique à la demande de modèle.
Si vous souhaitez avoir un type d'échange plus contextuel avec le service, un identifiant de session (propriété sessionId dans la requête JSON) doit être fourni pour que le service l'utilise comme clé d'échange de conversation. Cette clé de conversation servira à configurer le bon contexte pour le modèle (en résumant les échanges précédents) et à garder une trace des 5 derniers échanges (au moins). Il convient également de noter que l'historique des échanges sera conservé pendant 24 heures, cela peut être modifié dans le cadre des politiques gc du stockage BigTable dans la plateforme.
Ensuite, un exemple de conversation contextuelle :
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.nnUsing VertexAI Foundational Models can help you to:nn* Reduce the time and effort required to develop Generative AI applicationsn* Improve the accuracy and quality of your modelsn* Access the latest research and development in Generative AInnVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"describe the available LLM models?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models suite includes a variety of LLM models, including:nn* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.nnThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits). " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"care to share the price?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models). " ,
" sourceLinks " : [
]
}

