BigBertha
skeletal-integrations

BigBertha est une conception d'architecture qui démontre comment des LLMOps (Large Language Models Operations) automatisés peuvent être réalisés sur n'importe quel cluster Kubernetes à l'aide de technologies open source natives de conteneurs ?
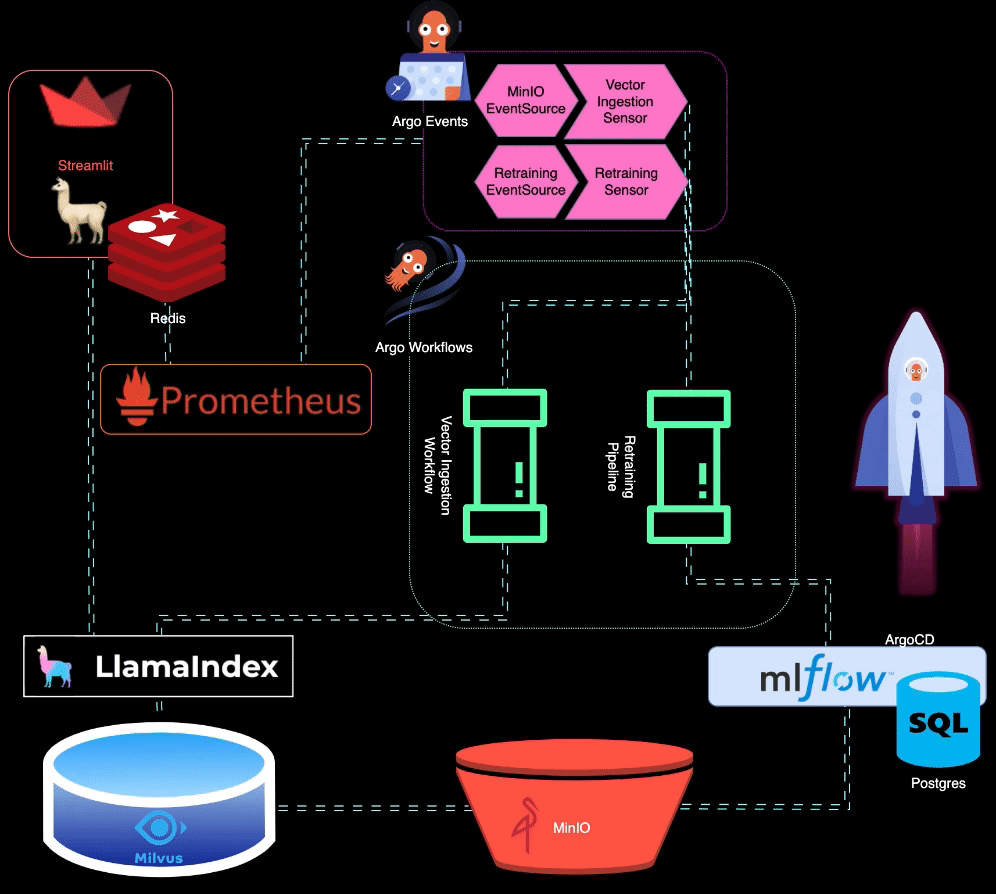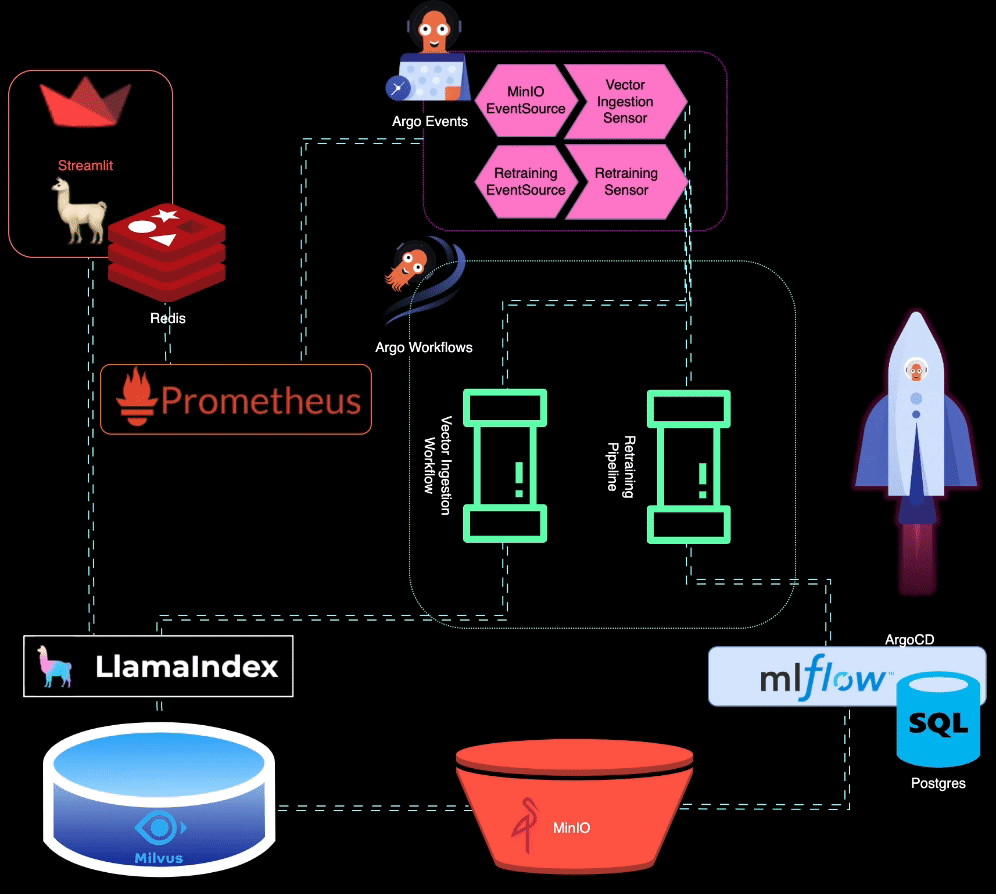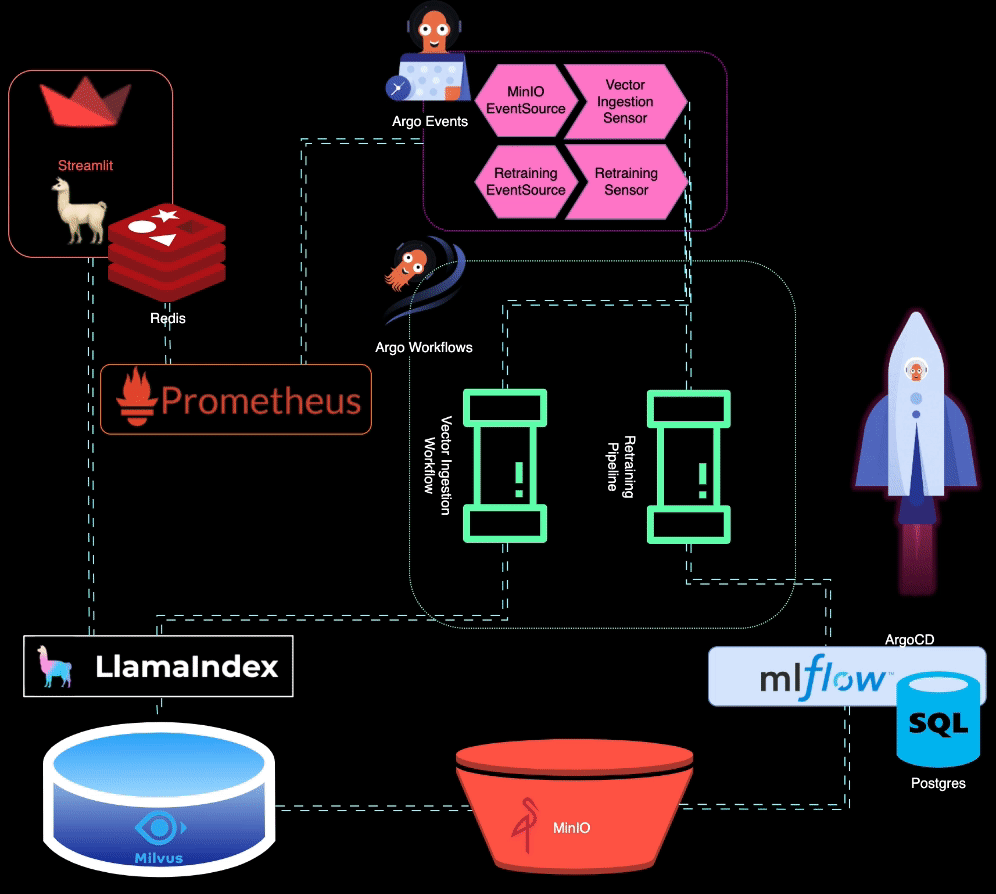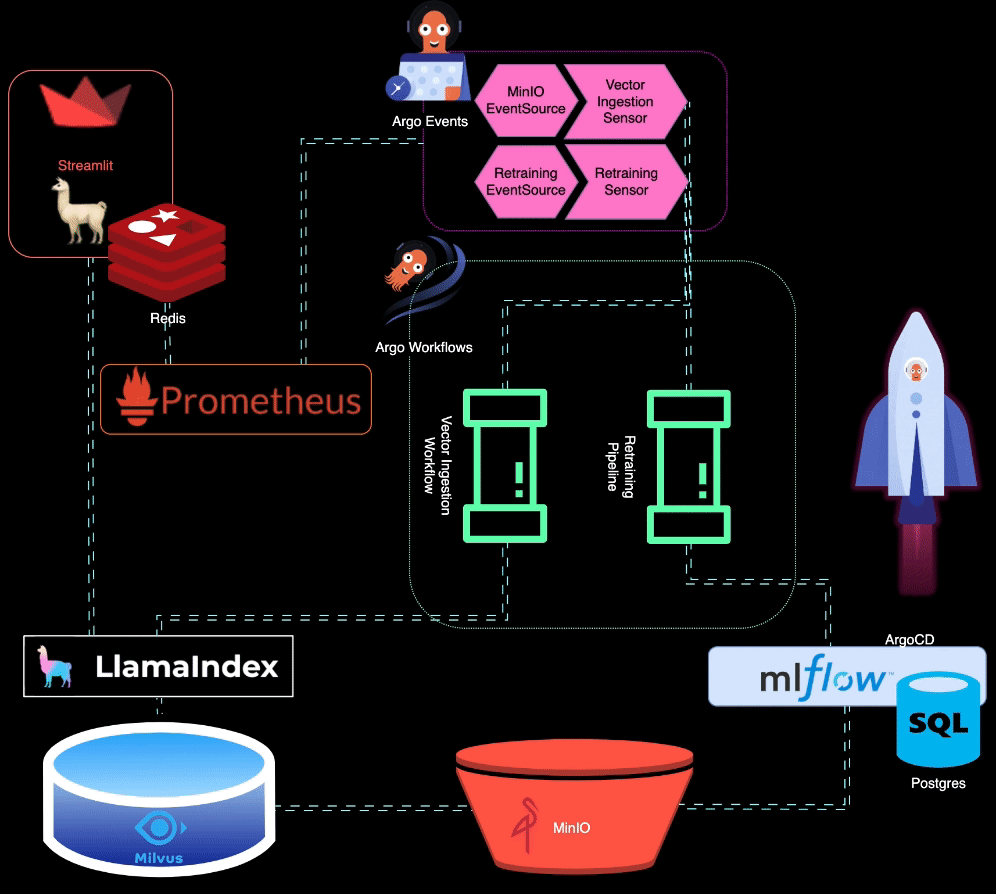
? BigBertha utilise Prometheus pour surveiller les modules de service LLM (Large Language Model). À des fins de démonstration, une application Streamlit est utilisée pour servir le LLM, et Prometheus en récupère les métriques. Des alertes sont configurées pour détecter la dégradation des performances.
Prometheus déclenche des alertes lorsque les performances du modèle se dégradent. Ces alertes sont gérées par AlertManager, qui utilise Argo Events pour déclencher un pipeline de recyclage afin d'affiner le modèle.
?️ Le pipeline de reconversion est orchestré à l'aide d'Argo Workflows. Ce pipeline peut être personnalisé pour effectuer un recyclage, un réglage fin et un suivi des métriques spécifiques au LLM. MLflow est utilisé pour enregistrer le LLM recyclé.
MinIO est utilisé pour le stockage de données non structurées. Argo Events est configuré pour écouter les événements de téléchargement sur MinIO, déclenchant un workflow d'ingestion de vecteurs lorsque de nouvelles données sont téléchargées.
? Argo Workflows est utilisé pour exécuter un pipeline d'ingestion de vecteurs qui utilise LlamaIndex pour générer et ingérer des vecteurs. Ces vecteurs sont stockés dans Milvus, qui sert de base de connaissances pour la génération augmentée par récupération.
BigBertha s'appuie sur plusieurs composants clés :
ArgoCD : un outil de livraison continue natif de Kubernetes qui gère tous les composants de la pile BigBertha.
Argo Workflows : un moteur de workflow natif de Kubernetes utilisé pour exécuter des pipelines d'ingestion de vecteurs et de recyclage de modèles.
Argo Events : un gestionnaire de dépendances basé sur les événements natif de Kubernetes qui connecte diverses applications et composants, déclenchant des flux de travail basés sur des événements.
Prometheus + AlertManager : utilisé pour la surveillance et les alertes liées aux performances du modèle.
LlamaIndex : un framework pour connecter les LLM et les sources de données, utilisé pour l'ingestion et l'indexation des données.
Milvus : une base de données vectorielles native de Kubernetes pour stocker et interroger des vecteurs.
MinIO : un système de stockage d'objets open source utilisé pour stocker des données non structurées.
MLflow : une plate-forme open source pour gérer le cycle de vie de l'apprentissage automatique, y compris le suivi des expériences et la gestion des modèles.
Kubernetes : la plate-forme d'orchestration de conteneurs qui automatise le déploiement, la mise à l'échelle et la gestion des applications conteneurisées.
Conteneurs Docker : les conteneurs Docker sont utilisés pour empaqueter et exécuter des applications de manière cohérente et reproductible.
À titre de démonstration, BigBertha inclut un chatbot basé sur Streamlit qui sert un modèle de chatbot quantifié Llama2 7B. Une simple application Flask est utilisée pour exposer les métriques, et Redis agit comme intermédiaire entre les processus Streamlit et Flask.
Ce projet est open source et est régi par les termes et conditions décrits dans le fichier LICENSE inclus dans ce référentiel.


