qevals
1.0.0
Evals est un cadre de génération et d'évaluation de données synthétiques pour les applications LLM et RAG.
Il comporte 2 modules principaux :
Un schéma d'architecture de haut niveau des évaluations est le suivant :
Schéma d'architecture
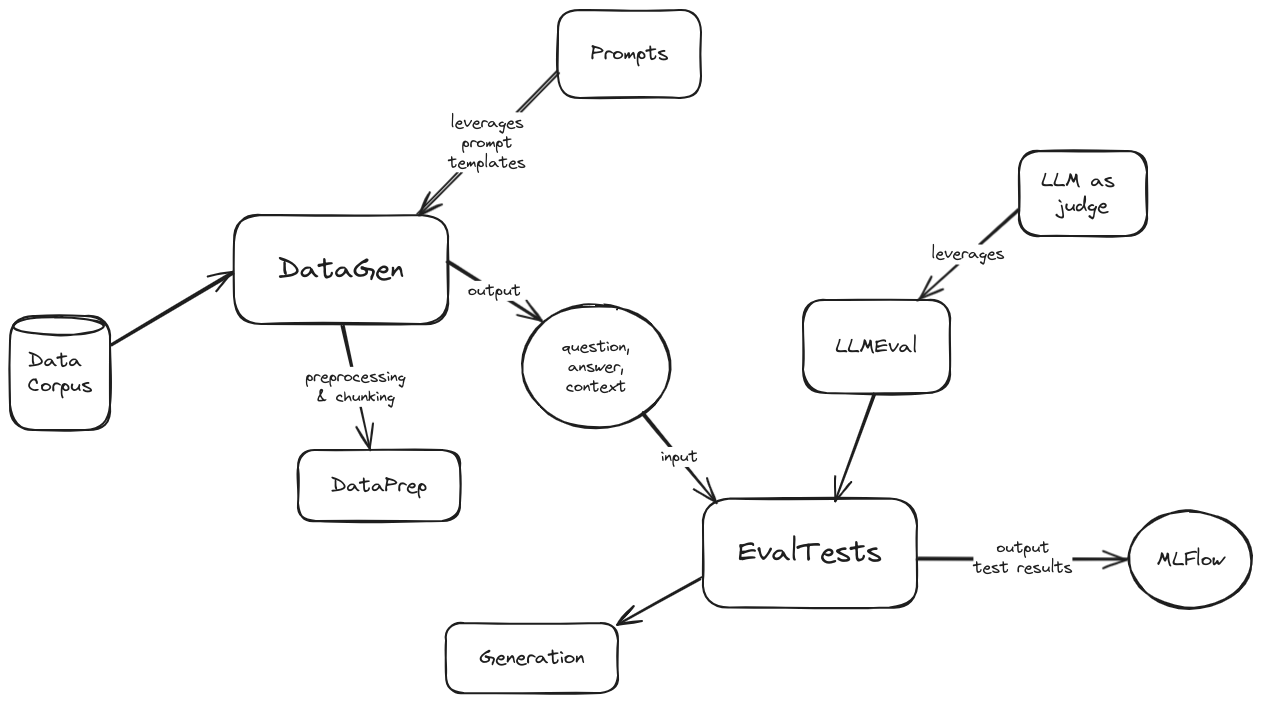
Pour commencer avec les évaluations, procédez comme suit :
pip install -r requirements.txt dans le répertoire du projet.config/config.toml.template et nommez- config/config.toml .config.toml :MISCDATAGENDATA_DIR contrôle l'emplacement du corpus de données à partir duquel générer des données synthétiques, il est relatif au répertoire datagen/data/ . En d’autres termes, ajoutez-y vos répertoires de données et précisez leur nom dans la variable.GEN_PROVIDER permet de choisir entre azure ou vertex .DATAEVALEVAL_TESTS propose une liste de tests d'évaluation pris en charge par le framework. Les options possibles sont AnswerRelevancy , Hallucination , Faithfulness , Bias , Toxicity , Correctness , Coherence , PromptInjection , PromptBreaking , PromptLeakage .EVAL_RPVODER permet de choisir entre azure ou vertex .Pour exécuter le module de génération de données synthétiques :
Modifier/adapter l'exemple de client fourni ( datagen/client.py )
Exécutez python -m datagen.client
Les données générées synthétiquement seront stockées dans le répertoire datagen/qa_out/ sous forme de fichier CSV au format :
```csv
question,context,ground_truth
```
Pour exécuter le module d'évaluation :
eval/client.py )question , context , ground_truth ).ground_truth peut ou non être utilisé en fonction du paramètre use_answers_from_dataset . Lorsqu'il est défini sur False il ignorera cette colonne de données et générera de nouvelles sorties à l'aide du modèle génératif configuré.mlflow ui --port 5000python -m eval.client

