cassandra lucene index
2.1.20.0
Cassandra Lucene Index de Stratio, dérivé de Stratio Cassandra, est un plugin pour Apache Cassandra qui étend sa fonctionnalité d'index pour fournir une recherche en temps quasi réel telle qu'ElasticSearch ou Solr, y compris des capacités de recherche en texte intégral et une recherche multivariable, géospatiale et bitemporelle gratuite. Ceci est réalisé grâce à une implémentation basée sur Apache Lucene des index secondaires Cassandra, où chaque nœud du cluster indexe ses propres données. Les index Cassandra de Stratio sont l'un des modules de base sur lesquels est basée la plateforme BigData de Stratio.
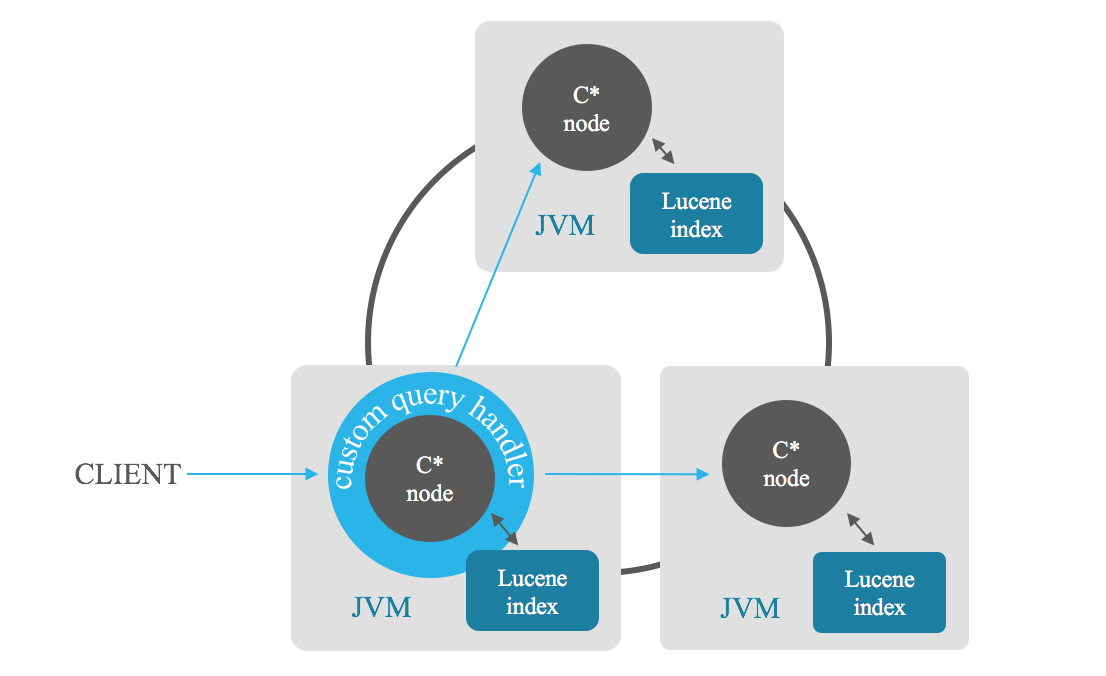
Les recherches par pertinence d'index vous permettent de récupérer les n résultats les plus pertinents satisfaisant une recherche. Le nœud coordinateur envoie la recherche à chaque nœud du cluster, chaque nœud renvoie ses n meilleurs résultats, puis le coordinateur combine ces résultats partiels et vous donne les n meilleurs d'entre eux, évitant ainsi une analyse complète. Vous pouvez également baser le tri sur une combinaison de champs.
N'importe quelle cellule des tableaux peut être indexée, y compris celles de la clé primaire ainsi que les collections. Les lignes larges sont également prises en charge. Vous pouvez analyser les plages de jetons/clés, appliquer des clauses CQL3 supplémentaires et consulter les résultats filtrés.
Les recherches filtrées par index sont d'une aide puissante lors de l'analyse des données stockées dans Cassandra avec les frameworks MapReduce comme Apache Hadoop ou, mieux encore, Apache Spark. L'ajout de filtres Lucene dans l'entrée des tâches peut réduire considérablement la quantité de données à traiter, évitant ainsi une analyse complète.
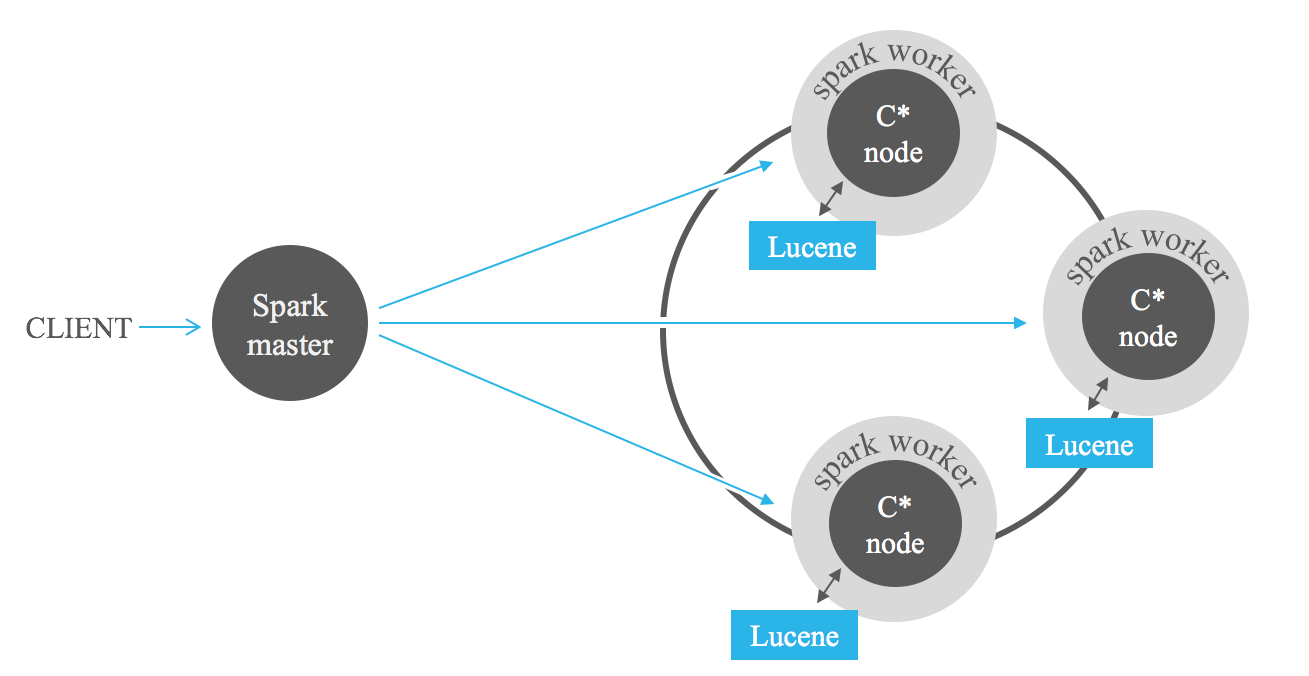
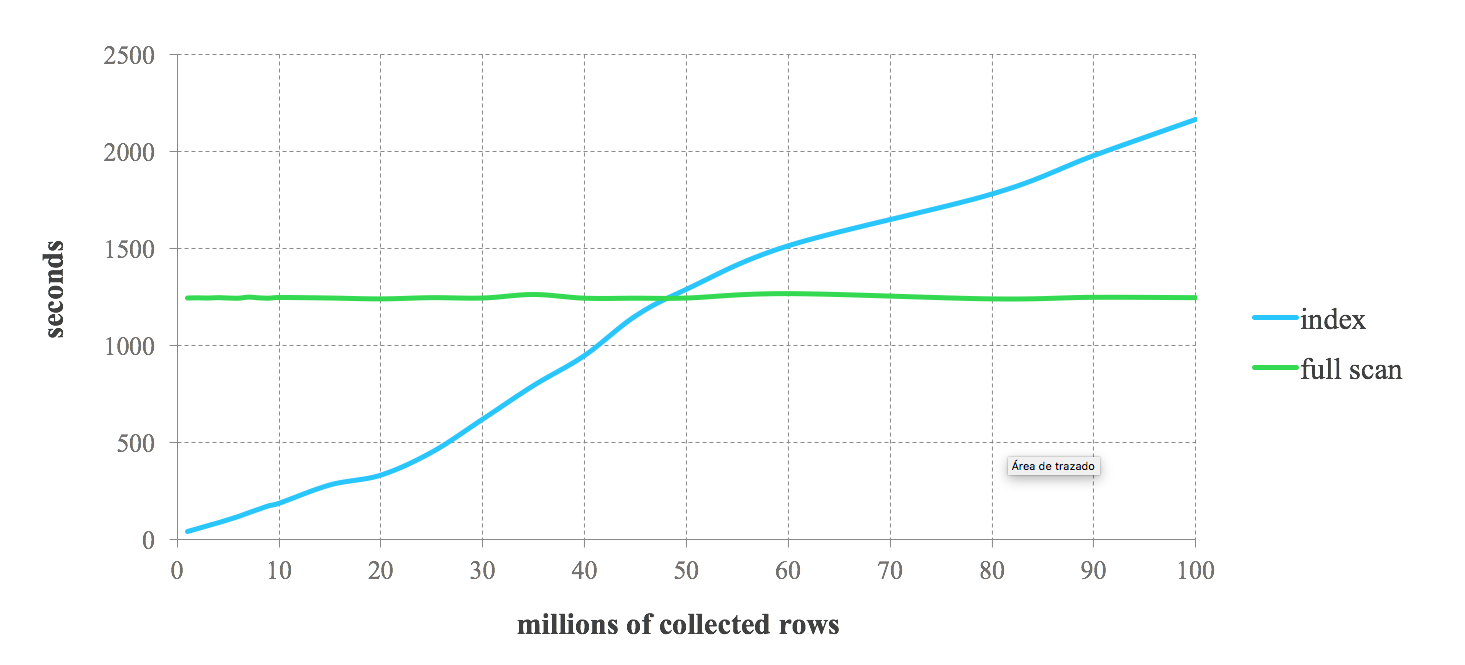
Le résultat de référence suivant peut vous donner une idée des performances attendues lors de la combinaison des index Lucene avec Spark. Nous effectuons des requêtes successives demandant de 1% à 100% des données stockées. On constate une haute performance de l'index pour les requêtes demandant des données fortement filtrées. Cependant, les performances diminuent dans les requêtes moins restrictives. À mesure que le nombre d'enregistrements renvoyés par la requête augmente, nous atteignons un point où l'index devient plus lent que l'analyse complète. Ainsi, la décision d'utiliser des index dans vos tâches Spark dépend de la sélectivité des requêtes. Le compromis entre les deux approches dépend du cas d'utilisation particulier. Généralement, la combinaison des index Lucene avec Spark est recommandée pour les tâches ne récupérant pas plus de 25 % des données stockées.
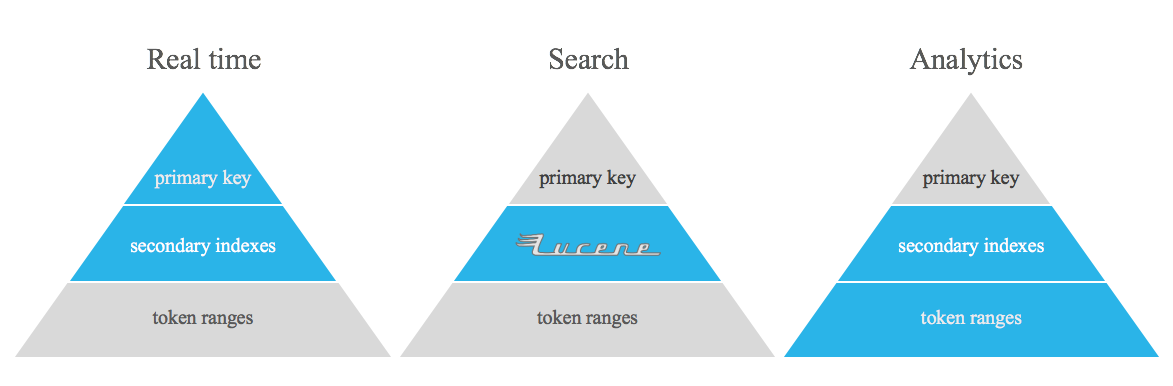
Ce projet n'est pas destiné à remplacer les tables dénormalisées Apache Cassandra, les index inversés et/ou les index secondaires. Il s'agit simplement d'un outil permettant d'effectuer certains types de requêtes qui sont vraiment difficiles à traiter à l'aide des fonctionnalités prêtes à l'emploi d'Apache Cassandra, comblant le fossé entre le temps réel et l'analyse.
Des informations plus détaillées sont disponibles dans la documentation de l'indice Cassandra Lucene de Stratio.
L'intégration de la technologie de recherche Lucene dans Cassandra fournit :
L'index Cassandra Lucene de Stratio et son intégration avec la technologie de recherche Lucene fournissent :
Pas encore pris en charge :
counter d'indexationL'index Cassandra Lucene de Stratio est distribué sous forme de plugin pour Apache Cassandra. Ainsi, il vous suffit de construire un JAR contenant le plugin et de l'ajouter au classpath de Cassandra :
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/Les versions d'index spécifiques de Cassandra Lucene sont destinées à des versions spécifiques d'Apache Cassandra. Ainsi, cassandra-lucene-index ABCX est destiné à être utilisé avec Apache Cassandra ABC, par exemple cassandra-lucene-index:3.0.7.1 pour cassandra:3.0.7. Veuillez noter que les versions prêtes pour la production sont des balises de version (par exemple 3.0.6.3), n'utilisez pas de branche-X ni de branches principales en production.
Alternativement, l'application de correctifs peut également être effectuée avec ce profil Maven, en spécifiant le chemin de votre installation Cassandra, cette tâche supprime également les versions JAR du plugin précédent dans le répertoire CASSANDRA_HOME/lib/ :
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >Si vous n'avez pas de version installée de Cassandra, il existe également un profil alternatif pour permettre à Maven de télécharger et de patcher la version appropriée d'Apache Cassandra :
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >Vous pouvez désormais exécuter Cassandra et effectuer des tests à l'aide du langage de requête Cassandra :
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh Les fichiers d'index de Lucene seront stockés dans les mêmes répertoires que ceux de Cassandra. Le répertoire de données par défaut est /var/lib/cassandra/data , et chaque index est placé à côté des SSTables de sa famille de colonnes indexées.
N'oubliez pas que si vous utilisez la recherche de formes géographiques, vous devez inclure le pot JTS.
Pour plus de détails sur Apache Cassandra, veuillez consulter sa documentation.
Nous allons créer le tableau suivant pour stocker les tweets :
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);Vous pouvez maintenant créer un index Lucene personnalisé avec l'instruction suivante :
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
}; Cela indexera toutes les colonnes de la table avec les types spécifiés et sera actualisée une fois par seconde. Alternativement, vous pouvez actualiser explicitement tous les fragments d'index avec une recherche vide avec cohérence ALL :
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUMMaintenant, pour rechercher des tweets dans une certaine plage de dates :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );La même recherche peut être effectuée en forçant une actualisation explicite des fragments d'index impliqués :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;Maintenant, pour rechercher les 100 tweets les plus pertinents dont le champ du corps contient l'expression « le big data donne aux organisations » dans la plage de dates susmentionnée :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Pour affiner la recherche afin d'obtenir uniquement les tweets rédigés par des utilisateurs dont le nom commence par "a" :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;Pour obtenir les 100 résultats filtrés les plus récents, vous pouvez utiliser l'option de tri :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;La recherche précédente peut être restreinte aux tweets créés à proximité d'une position géographique :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;Il est également possible de trier les résultats par distance à une position géographique :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;Enfin et surtout, vous pouvez acheminer n'importe quelle recherche vers une certaine plage de jetons ou partition, de telle sorte que seul un sous-ensemble des nœuds du cluster soit touché, économisant ainsi de précieuses ressources :
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;Ce dernier constitue la base du support de Hadoop, Spark et d’autres frameworks MapReduce.
Veuillez vous référer à la documentation complète de l'indice Cassandra Lucene de Stratio.


