sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
Responsable : jcudit et lsgos
Projet maintenu jusqu'au (AAAA-MM-JJ) au moins : 2023-03-14
Ceci est un exemple d'utilisation de l'API Cohere pour créer un moteur de recherche sémantique simple. Il n'est pas censé être prêt pour la production ou mis à l'échelle efficacement (bien qu'il puisse être adapté à ces fins), mais sert plutôt à démontrer la facilité de production d'un moteur de recherche alimenté par des représentations produites par les grands modèles linguistiques (LLM) de Cohere.
L'algorithme de recherche utilisé ici est assez simple : il trouve simplement le paragraphe qui correspond le plus à la représentation de la question, en utilisant le point final co.embed . Ceci est expliqué plus en détail ci-dessous, mais voici un schéma simple de ce qui se passe. Tout d'abord, nous décomposons le texte saisi en une série de paragraphes, en stockant leurs adresses dans l'entrée dans une liste et en générant une intégration vectorielle pour chaque paragraphe en utilisant co.embed :
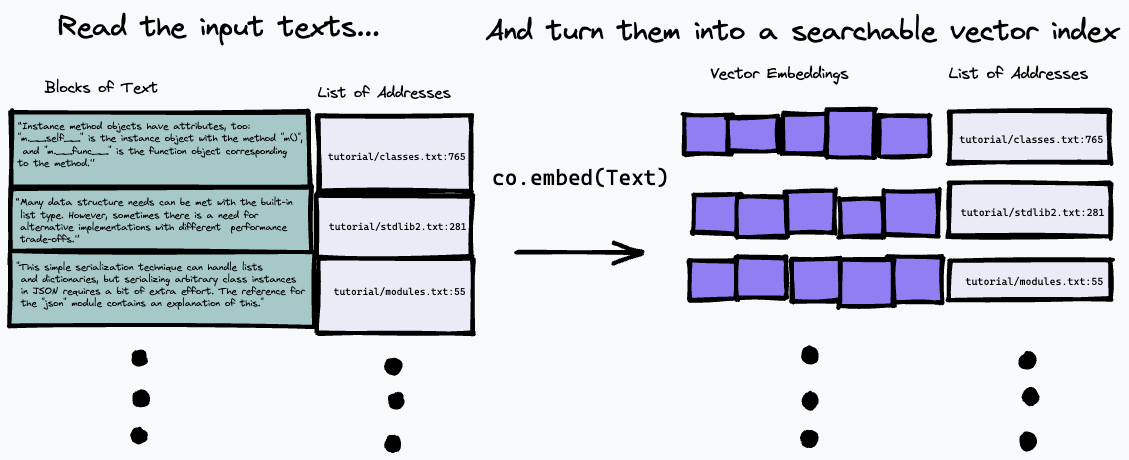
Ensuite, nous pouvons interroger notre index en intégrant la requête de texte et en recherchant les paragraphes du texte source qui correspondent le plus à l'aide d'une certaine mesure de similarité vectorielle (nous avons utilisé la similarité cosinus) : 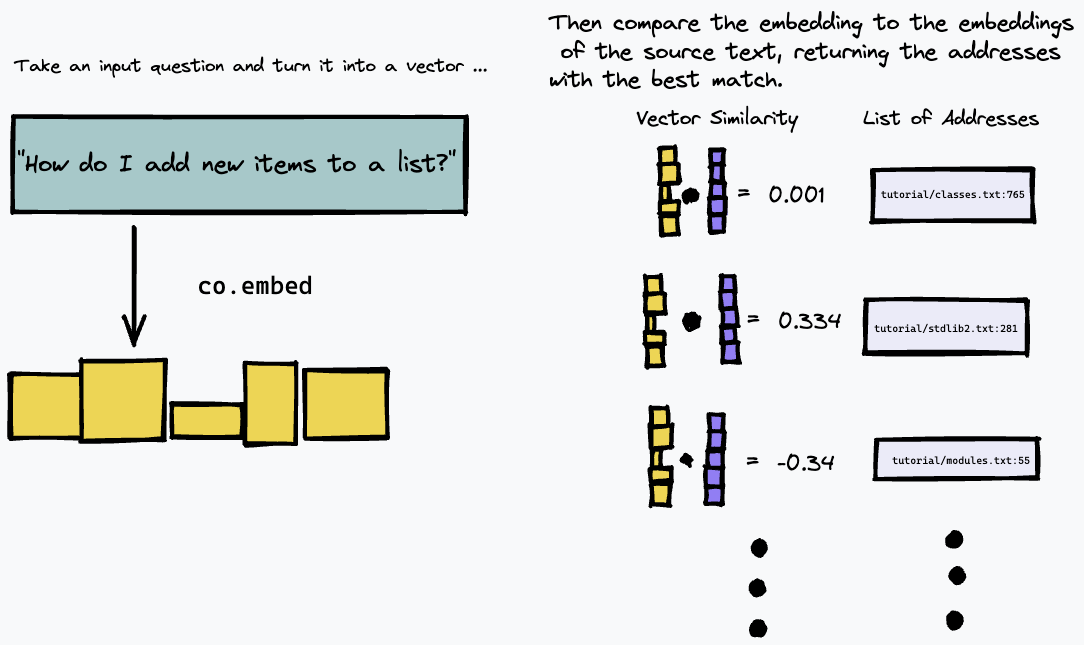
En conséquence, cela fonctionne mieux sur les sources textuelles où la réponse à une question donnée est susceptible d'être donnée par un paragraphe concret dans le texte, comme la documentation technique ou les wikis internes qui sont structurés comme une liste d'instructions ou de faits concrets. Cela ne fonctionne pas aussi bien, par exemple, pour répondre à des questions sur un texte de forme libre comme des romans où l'information peut être répartie sur plusieurs paragraphes ; vous devrez utiliser une méthode différente d'indexation du texte pour cela.
À titre d'exemple, ce référentiel construit un moteur de recherche sémantique simple sur la version texte de la dernière documentation Python.
Pour installer les exigences de Python, assurez-vous que la poésie est installée et exécutez :
# install python deps
poetry installVous devriez également avoir installé Docker. Sous OS X, si vous utilisez homebrew, nous vous recommandons d'exécuter
brew install --cask dockerAvant d'exécuter Docker (par exemple pour exécuter notre serveur) pour la première fois sous OS X, ouvrez l'application Docker et accordez-lui les privilèges dont elle a besoin pour s'exécuter sur votre système.
Vous devrez également disposer d'une clé API Cohere dans le COHERE_TOKEN . Obtenez-en un sur la plateforme Cohere (créez un compte si nécessaire) et écrivez-le dans votre environnement
export COHERE_TOKEN= < MY_API_KEY > (où <MY_API_KEY> est la clé que vous avez obtenue, sans les crochets <...> ).
Alternativement, vous pouvez transmettre COHERE_TOKEN=<MY_API_KEY> comme argument supplémentaire à n'importe quelle commande make ci-dessous.
Suivez ces étapes pour d’abord créer un index sémantique de votre collection de documents. Ces étapes produisent un index sémantique pour la documentation officielle de Python, mais pourraient être adaptées pour des collectes de données arbitraires.
Tout d’abord, téléchargez la documentation Python en exécutant l’une des commandes suivantes.
Si vous souhaitez démarrer rapidement, exécutez
make download-python-docs-smallpour limiter l'ensemble de documents au didacticiel Python. Nous vous recommandons de procéder ainsi uniquement pour un test rapide, car les résultats seront très limités .
Si vous souhaitez tester le moteur de recherche sur l'ensemble de la documentation Python, exécutez
make download-python-docsmais sachez que la production des intégrations prendra des heures (même si cela ne doit être fait qu'une seule fois).
Alternativement, si vous souhaitez expérimenter votre propre texte, téléchargez-le simplement sous forme de fichiers .txt dans un répertoire appelé txt/ dans ce référentiel.
Une fois que vous avez du texte, nous devons le traiter dans un index de recherche d'intégrations et d'adresses.
Cela peut être fait en utilisant la commande
make embeddings en supposant que votre texte cible se trouve dans le répertoire ./txt/ .
La commande recherchera récursivement dans le répertoire ./txt/ les fichiers avec une extension .txt et créera une base de données simple des intégrations, du nom de fichier et du numéro de ligne de chaque paragraphe.
Attention : si vous avez beaucoup de texte à rechercher, cela peut prendre un peu de temps !
Une fois que vous avez créé un fichier embeddings.npz , vous pouvez utiliser la commande suivante pour créer une image Docker qui servira à une simple application REST pour vous permettre d'interroger la base de données que vous avez créée :
make buildVous pouvez ensuite démarrer le serveur en utilisant
make runC'est un peu exagéré pour un exemple simple, mais cela est conçu pour refléter le fait que la construction d'un index d'un grand corps de texte est relativement lente et garantit que l'interrogation du moteur est rapide.
Si vous souhaitez utiliser ce projet comme élément de base d'une application réelle, il est probable que vous souhaitiez conserver votre base de données d'incorporations de texte dans une architecture de serveur et l'interroger avec un client léger. Conditionner le serveur en tant qu'application Docker signifie qu'il est très simple d'en faire une « vraie » application en la déployant sur un service cloud.
Si vous ouvrez une nouvelle fenêtre de terminal pour l'une des options ci-dessous, n'oubliez pas d'exécuter
export COHERE_TOKEN= < MY_API_KEY > L'option de loin la plus simple consiste à exécuter notre script d'assistance :
scripts/ask.sh " My query here "pour interroger la base de données. Le script prend un deuxième argument facultatif spécifiant le nombre de résultats souhaités.
Le script affiche une interface vim modifiée, avec les commandes suivantes :
q pour quitter.Le volet supérieur vous montrera la position dans le document où se trouve le résultat.
Une fois le serveur exécuté, vous pouvez l'interroger à l'aide d'une simple API REST. Vous pouvez explorer l'API directement en accédant à /docs#/default/search_search_post ici. Il s'agit d'une simple API JSON REST ; voici comment poser une requête en utilisant curl :
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
Cela renverra une liste JSON de longueur num_results , chacune avec le nom de fichier et le numéro de ligne ( doc_url et block_url ) des blocs qui correspondaient le plus sémantiquement à votre requête. Mais vous voudrez probablement simplement lire la partie des fichiers qui constitue la meilleure réponse.
Lorsque nous recherchons dans des fichiers texte locaux, il est en fait un peu plus facile d'analyser le résultat à l'aide d'outils de ligne de commande ; utilisez le script python fourni utils/query_server.py pour l'interroger sur la ligne de commande. query_server.py imprime les résultats au format standard file_name:line_number: afin que nous puissions parcourir les résultats réels de manière agréable en tirant parti du mode quickfix de vim .
En supposant que vous ayez vim sur votre machine, vous pouvez simplement
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
pour que vim ouvre les fichiers texte indexés aux emplacements renvoyés par l'algorithme de recherche. (utilisez :qall pour fermer à la fois la fenêtre et le navigateur quickfix). Vous pouvez parcourir les résultats renvoyés en utilisant :cn et :cp . Les résultats ne sont pas parfaits ; c'est une recherche sémantique, donc on peut s'attendre à ce que la correspondance soit un peu floue. Malgré cela, je constate souvent que vous pouvez obtenir la réponse à votre question dans les premiers résultats, et l'utilisation de l'API de Cohere vous permet d'exprimer votre question en langage naturel et de créer un moteur de recherche étonnamment efficace en seulement quelques lignes de code.
Certaines requêtes intéressantes dans le cas de la documentation Python qui montrent que la recherche fonctionne bien sur des questions génériques en langage naturel sont :
How do I put new items in a list? (Notez que cette question évite d'utiliser le mot-clé « append » et ne correspond pas exactement à la façon dont la documentation explique l'ajout (ils disent qu'il est utilisé pour ajouter de nouveaux éléments à la fin d'une liste). Mais la recherche sémantique montre correctement que le le paragraphe pertinent est toujours la meilleure correspondance.)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (notez pour cette question que le premier résultat pour moi est une FAQ sur ce sujet précis, mais avec une question formulée différemment. Cependant, comme il s'agit d'une recherche sémantique, notre algorithme sélectionne correctement un résultat qui correspond à la signification, pas seulement le formulation, de notre requête)How do I remove an item from a set?How do list comprehensions work? Ce dépôt utilise une stratégie très simple pour indexer un document et rechercher la meilleure correspondance. Premièrement, il divise chaque document en paragraphes, ou « blocs ». Ensuite, il appelle co.embed sur chaque paragraphe, afin de générer une intégration vectorielle en utilisant le modèle de langage de Cohere. Il stocke ensuite chaque vecteur d'intégration, ainsi que le document correspondant et le numéro de ligne du paragraphe, dans un simple tableau en tant que « base de données ».
Afin d'effectuer réellement la recherche, nous utilisons la bibliothèque de recherche de similarité FAISS. Lorsque nous recevons une requête, nous utilisons le même appel d'API Cohere pour intégrer la requête. Nous utilisons ensuite FAISS pour trouver le sommet
Si vous avez des questions ou des commentaires, veuillez signaler un problème ou nous contacter sur Discord.
Si vous souhaitez contribuer à ce projet, veuillez lire CONTRIBUTORS.md dans ce référentiel et signer le contrat de licence de contributeur avant de soumettre toute demande d'extraction. Un lien pour signer le Cohere CLA sera généré la première fois que vous effectuerez une pull request vers un référentiel Cohere.
Toy Semantic Search possède une licence MIT, comme indiqué dans le fichier LICENSE.


