elassandra
v6.2.3.38

Elassandra est une distribution Apache Cassandra incluant un moteur de recherche Elasticsearch. Elassandra est une base de données multi-maîtres et un moteur de recherche multi-cloud prenant en charge la réplication sur plusieurs centres de données en mode actif/actif.
Le code Elasticsearch est intégré aux nœuds Cassanda offrant des fonctionnalités de recherche avancées sur les tables Cassandra et Cassandra sert de magasin de données et de configuration Elasticsearch.
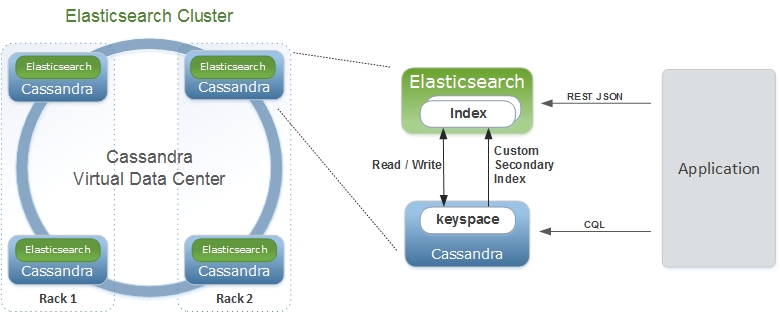
Elassandra prend en charge les nœuds virtuels Cassandra et évolue horizontalement en ajoutant plus de nœuds sans avoir besoin de repartir les index.
La documentation du projet est disponible sur doc.elassandra.io.
Pour les utilisateurs de Cassandra, elassandra fournit les fonctionnalités Elasticsearch :
Pour les utilisateurs d'Elasticsearch, elassandra fournit des fonctionnalités utiles :
Guide de démarrage rapide pour exécuter un cluster Elassandra à nœud unique dans Docker.
Déployez Elassandra en lançant un Google Kubernetes Engine :
<<<<<<< HEAD Depuis la version 6.8.4.2, l'état de l'application gossip X1 peut être compressé à l'aide d'une propriété système. L'activation de ces paramètres permet la création de nombreux index virtuels. Avant d'activer ce paramètre, mettez à niveau tous les nœuds 6.8.4.x vers la version 6.8.4.2 (ou supérieure). Une fois que tous les nœuds sont en 6.8.4.2, ils sont capables de décompresser l'état de l'application même si les paramètres ne sont pas encore configurés localement.
Elassandra utilise le protocole Cassandra GOSSIP pour gérer la table de routage Elasticsearch et Elassandra 6.8.4.2+ ajoute la prise en charge de la compression de l'état de l'application X1 pour augmenter le nombre maximum d'index Elasticsearch. Pour des raisons de compatibilité descendante, la compression est désactivée par défaut, mais une fois que tous vos nœuds sont mis à niveau vers la version 6.8.4.2+, vous devez activer la compression X1 en ajoutant -Des.compress_x1=true dans votre conf/jvm.options et en redémarrant tout. nœuds. Les nœuds exécutant la version 6.8.4.2+ sont capables de lire X1 compressé et non compressé.
Avant la version 6.2.3.21, le facteur de réplication Cassandra pour l'espace de clés elasic_admin (et elastic_admin_[datacenter.group]) était automatiquement ajusté au nombre de nœuds du centre de données. Depuis la version 6.2.3.21 et parce que cela a un impact sur les performances sur les gros clusters, c'est désormais à votre administrateur Elassandra de bien ajuster le facteur de réplication pour cet espace de clés. Gardez à l'esprit que les mises à jour de mappage Elasticsearch reposent sur une transaction PAXOS qui nécessite la réussite des nœuds QUORUM. Le facteur de réplication doit donc être d'au moins 3 sur chaque centre de données.
La version de métadonnées Elassandra 6.2.3.19 s'appuie désormais sur la table Cassandra elastic_admin.metadata_log (qui était elastic_admin.metadata de 6.2.3.8 à 6.2.3.18) pour conserver l'historique de mise à jour du mappage elasticsearch et récupérer automatiquement d'un éventuel problème de délai d'expiration d'écriture PAXOS.
Lors de la mise à niveau du premier nœud d'un cluster, Elassandra copie automatiquement le fichier metadata.version actuel dans la nouvelle table elastic_admin.metadata_log . Pour éviter toute incohérence de mappage Elasticsearch, vous devez éviter la mise à jour du mappage pendant que la mise à niveau propagée est en cours. Une fois tous les nœuds mis à niveau, elastic_admin.metadata n'est plus utilisé et peut être supprimé. Ensuite, vous pouvez obtenir l'historique des mises à jour du mappage à partir du nouveau elastic_admin.metadata_log et savoir quel nœud a mis à jour le mappage, quand et pour quelle raison.
Elassandra 6.2.3.8+ gère désormais entièrement le mappage elasticsearch dans le schéma CQL grâce à l'utilisation d'extensions de schéma CQL (voir system_schema.tables , extensions de colonnes ). Ces extensions de table et les mises à jour du schéma CQL résultant de la création/modification de l'index elasticsearch sont mises à jour dans des mises à jour de schéma atomiques par lots pour garantir la cohérence lorsque des mises à jour simultanées se produisent. De plus, ces extensions sont stockées en binaire et prennent en charge les mises à jour partielles pour être plus efficaces. Par conséquent, le mappage elasticsearch n'est plus stocké dans la table elastic_admin.metadata .
AVERTISSEMENT : lors de la mise à niveau propagée, les modifications du mappage elasticserach ne sont pas propagées entre les nœuds exécutant la nouvelle et l'ancienne version. Ne modifiez donc pas votre mappage pendant la mise à niveau. Une fois que tous vos nœuds ont été mis à niveau vers 6.2.3.8+ et validés, appliquez les instructions CQL suivantes pour supprimer les métadonnées elasticsearch inutiles :
ALTER TABLE elastic_admin.metadata DROP metadata ;
ALTER TABLE elastic_admin.metadata WITH comment = ' ' ;AVERTISSEMENT : en raison des extensions de table CQL utilisées par Elassandra, certaines anciennes versions de cqlsh peuvent entraîner le message d'erreur suivant : "L'objet 'module' n'a pas d'attribut 'viewkeys'." . Cela provient de l'ancien pilote Python Cassandra intégré à Cassandra et a été signalé dans CASSANDRA-14942. Solutions de contournement possibles :
docker run -it --rm strapdata/cqlsh:0.1 node.example.com Assurez-vous que Java 8 est installé et que JAVA_HOME pointe vers le bon emplacement.
export CASSANDRA_HOME=<extracted_directory>bin/cassandra -ebin/nodetool statuscurl -XGET localhost:9200/_cluster/state Essayez d'indexer un document sur un index inexistant :
curl -XPUT ' http://localhost:9200/twitter/_doc/1?pretty ' -H ' Content-Type: application/json ' -d ' {
"user": "Poulpy",
"post_date": "2017-10-04T13:12:00Z",
"message": "Elassandra adds dynamic mapping to Cassandra"
} 'Recherchez ensuite dans Cassandra :
bin/cqlsh -e " SELECT * from twitter. " _doc " " En coulisses, Elassandra a créé un nouveau Keyspace twitter et table _doc .
admin@cqlsh > DESC KEYSPACE twitter;
CREATE KEYSPACE twitter WITH replication = { ' class ' : ' NetworkTopologyStrategy ' , ' DC1 ' : ' 1 ' } AND durable_writes = true;
CREATE TABLE twitter . " _doc " (
" _id " text PRIMARY KEY ,
message list < text > ,
post_date list < timestamp > ,
user list < text >
) WITH bloom_filter_fp_chance = 0 . 01
AND caching = { ' keys ' : ' ALL ' , ' rows_per_partition ' : ' NONE ' }
AND comment = ' '
AND compaction = { ' class ' : ' org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy ' , ' max_threshold ' : ' 32 ' , ' min_threshold ' : ' 4 ' }
AND compression = { ' chunk_length_in_kb ' : ' 64 ' , ' class ' : ' org.apache.cassandra.io.compress.LZ4Compressor ' }
AND crc_check_chance = 1 . 0
AND dclocal_read_repair_chance = 0 . 1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0 . 0
AND speculative_retry = ' 99PERCENTILE ' ;
CREATE CUSTOM INDEX elastic__doc_idx ON twitter. " _doc " () USING ' org.elassandra.index.ExtendedElasticSecondaryIndex ' ;Par défaut, les champs Elasticsearch à valeurs multiples sont mappés à la liste Cassandra. Maintenant, insérez une ligne avec CQL :
INSERT INTO twitter. " _doc " ( " _id " , user, post_date, message)
VALUES ( ' 2 ' , [ ' Jimmy ' ], [dateof(now())], [ ' New data is indexed automatically ' ]);
SELECT * FROM twitter. " _doc " ;
_id | message | post_date | user
-- ---+--------------------------------------------------+-------------------------------------+------------
2 | [ ' New data is indexed automatically ' ] | [ ' 2019-07-04 06:00:21.893000+0000 ' ] | [ ' Jimmy ' ]
1 | [ ' Elassandra adds dynamic mapping to Cassandra ' ] | [ ' 2017-10-04 13:12:00.000000+0000 ' ] | [ ' Poulpy ' ]
( 2 rows)Recherchez-le ensuite avec l'API Elasticsearch :
curl " localhost:9200/twitter/_search?q=user:Jimmy&pretty "Et voici un exemple de réponse :
{
"took" : 3 ,
"timed_out" : false ,
"_shards" : {
"total" : 1 ,
"successful" : 1 ,
"skipped" : 0 ,
"failed" : 0
},
"hits" : {
"total" : 1 ,
"max_score" : 0.6931472 ,
"hits" : [
{
"_index" : " twitter " ,
"_type" : " _doc " ,
"_id" : " 2 " ,
"_score" : 0.6931472 ,
"_source" : {
"post_date" : " 2019-07-04T06:00:21.893Z " ,
"message" : " New data is indexed automatically " ,
"user" : " Jimmy "
}
}
]
}
} This software is licensed under the Apache License, version 2 ("ALv2"), quoted below.
Copyright 2015-2018, Strapdata ([email protected]).
Licensed under the Apache License, Version 2.0 (the "License"); you may not
use this file except in compliance with the License. You may obtain a copy of
the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
License for the specific language governing permissions and limitations under
the License.


