wagtail_textract
1.0.0
Ce package n’est pas maintenu et nous n’avons pas l’intention de le maintenir.
Nous vous conseillons de l'utiliser comme exemple, peut-être de copier le code dans votre propre projet, mais de ne pas installer le package.
Ce package sert à remplacer la classe Document de Wagtail par une classe qui permet de rechercher dans le contenu d'un fichier document à l'aide d'un extrait.
Texttract peut extraire du texte à partir (entre autres) de fichiers PDF, Excel et Word.
Le package a été inspiré par le problème « Recherche : extraire le texte des documents » dans Wagtail.
Les documents fonctionneront comme avant, sauf que la recherche de documents dans l'interface d'administration de Wagtail trouvera également les termes de recherche dans le contenu des fichiers.
Quelques captures d'écran pour illustrer.
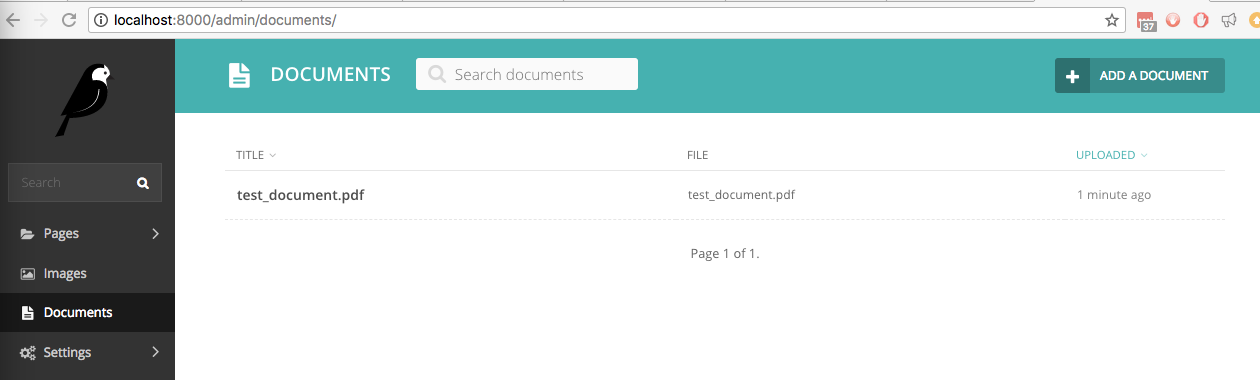
Dans notre nouveau site Wagtail avec wagtail_textract installé, nous avons téléchargé un fichier appelé test_document.pdf contenant du texte manuscrit. Il est répertorié dans l'interface d'administration sous Documents :
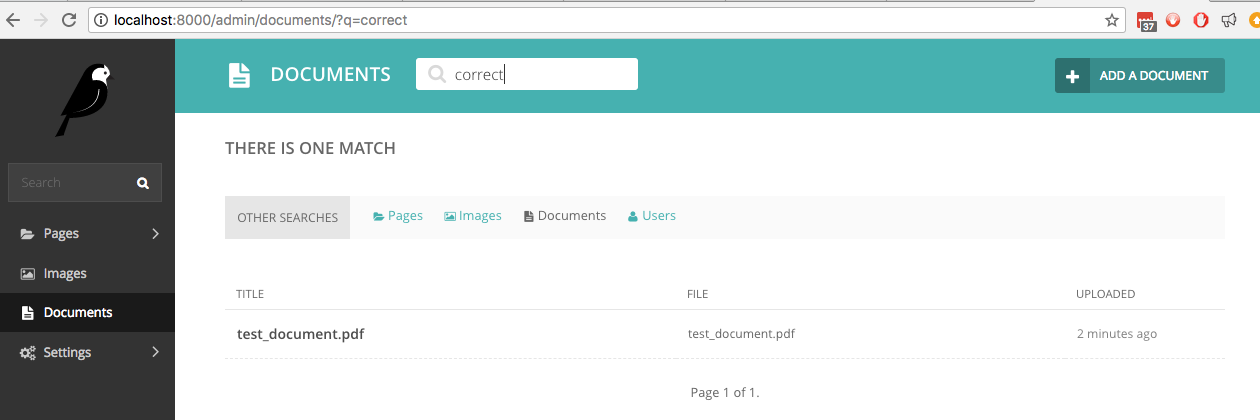
Si nous recherchons maintenant dans Documents le mot correct , qui est l'un des mots manuscrits, la recherche en direct le trouve :
L'hypothèse est que cette recherche devrait non seulement être disponible dans l'interface d'administration de Wagtail, mais également dans une vue de recherche publique, pour laquelle nous fournissons un exemple de code.
Nous utilisons ce package en production depuis août 2018 sur https://nuffic.nl.
wagtail_textract à vos besoins et/ou pip install wagtail_textractINSTALLED_APPS .WAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document" dans vos paramètres Django.Remarque : Vous recevrez un avertissement d'incompatibilité lors de l'installation de wagtail_texttract (Wagtail 2.0.1 installé) :
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
Nous n’avons pas vu cela entraîner de problèmes, mais c’est quelque chose à garder à l’esprit.
Afin que textract utilise Tesseract, ce qui se produit si textract normal ne trouve aucun texte, vous devez ajouter les fichiers de données sur lesquels Tesseract peut baser sa correspondance de mots.
Créez un répertoire tessdata dans le répertoire de votre projet et téléchargez les langues souhaitées.
La transcription se fait automatiquement après la sauvegarde du document, dans un exécuteur asyncio pour éviter de bloquer la réponse pendant le traitement.
Pour transcrire tous les documents existants, exécutez la commande de gestion : :
./manage.py transcribe_documents
Cela peut évidemment prendre beaucoup de temps.
Voici un exemple de code pour une vue de recherche (en dehors de l'interface d'administration de Wagtail) qui affiche à la fois les résultats de la page et du document.
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
}) Votre modèle doit permettre de gérer les documents différemment des pages, car vous ne pouvez pas créer pageurl result sur un document :
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} Pour utiliser wagtail_texttract, votre modèle CustomizedDocument doit faire la même chose que le document de wagtail_texttract :
TranscriptionMixinsearch_fields from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
] Notez que la première classe à sous-classer doit être TranscriptionMixin , donc sa save() a priorité sur celle des autres classes parentes.
Pour exécuter des tests, consultez ce référentiel et :
make test
Un rapport de couverture sera généré dans ./coverage_html_report/ .


