loss_function_search
1.0.0
Xiaobo Wang*, Shuo Wang*, Cheng Chi, Shifeng Zhang, Tao Mei
Il s'agit de l'implémentation officielle de notre recherche de fonction de perte pour la reconnaissance faciale. Il est accepté par ICML 2020.
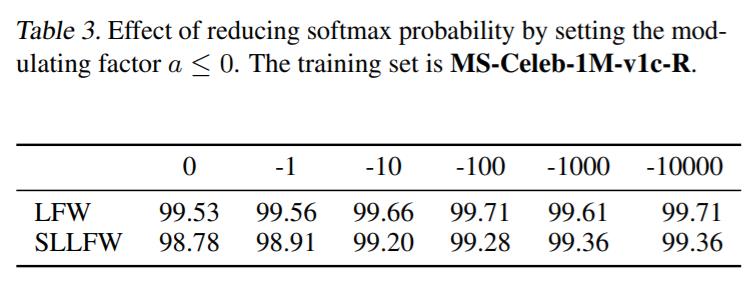
Dans la reconnaissance faciale, la conception de fonctions de perte softmax basées sur les marges (par exemple, marges angulaires, additives, additives) joue un rôle important dans l'apprentissage des caractéristiques discriminantes. Cependant, ces méthodes heuristiques artisanales ne sont pas optimales car elles nécessitent beaucoup d’efforts pour explorer le vaste espace de conception. Nous analysons d'abord que la clé pour améliorer la discrimination des caractéristiques est en fait de savoir comment réduire la probabilité softmax . Nous concevons ensuite une formulation unifiée pour les pertes softmax actuelles basées sur la marge. En conséquence, nous définissons un nouvel espace de recherche et développons une méthode de recherche guidée par récompense pour obtenir automatiquement le meilleur candidat. Les résultats expérimentaux sur une variété de tests de reconnaissance faciale ont démontré l'efficacité de notre méthode par rapport aux alternatives de pointe.
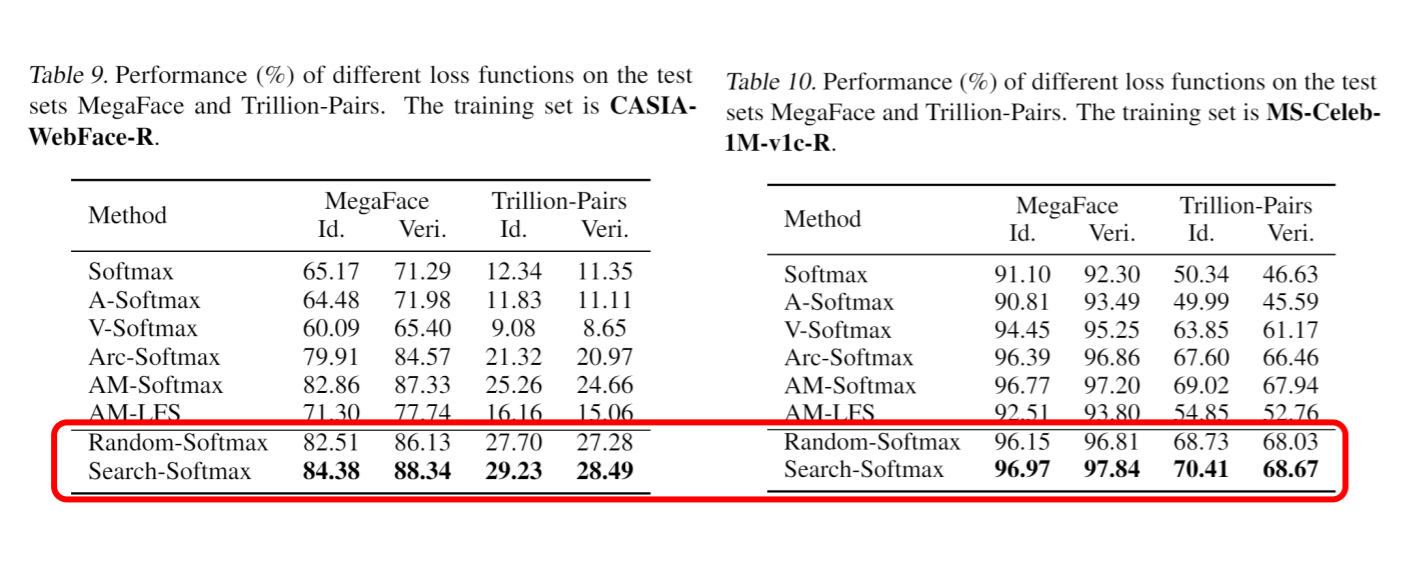

Pour valider l'efficacité de notre espace de recherche, on peut simplement choisir random-softmax. Dans train.sh, vous pouvez définir do_search=1. Si nous utilisons un softmax aléatoire pour entraîner notre réseau, nous obtenons le résultat ci-dessous.
Pytorch 1.1 ou supérieur est requis.
Dans la mise en œuvre actuelle, nous utilisons lmdb pour regrouper nos images de formation. Le format de notre lmdb provient principalement de Caffe. Et vous pouvez écrire votre propre fichier caffe.proto comme suit :
syntax = "proto2";
message Datum {
//the acutal image data, in bytes.
optional bytes data=1;
}
Outre le lmdb, il devrait exister un fichier texte décrivant le lmdb. Chaque ligne du fichier texte contient 2 champs séparés par un espace. La ligne dans le fichier texte est la suivante :
lmdb_key label
./train.shVous pouvez soit utiliser ./train.sh. REMARQUE qu'avant d'exécuter train.sh, vous devez fournir vos propres train_source_lmdb et train_source_file. Pour plus d'utilisation, s'il vous plaît
python main . py - h

