elastic_transformers
1.0.0
Recherche élastique sémantique avec transformateurs de phrases. Nous utiliserons la puissance d'Elastic et la magie de BERT pour indexer un million d'articles et effectuer des recherches lexicales et sémantiques sur ceux-ci.
L'objectif est de fournir un moyen simple d'utilisation de configurer votre propre Elasticsearch avec des capacités de pointe en matière d'intégration contextuelle/de recherche sémantique à l'aide de transformateurs NLP.
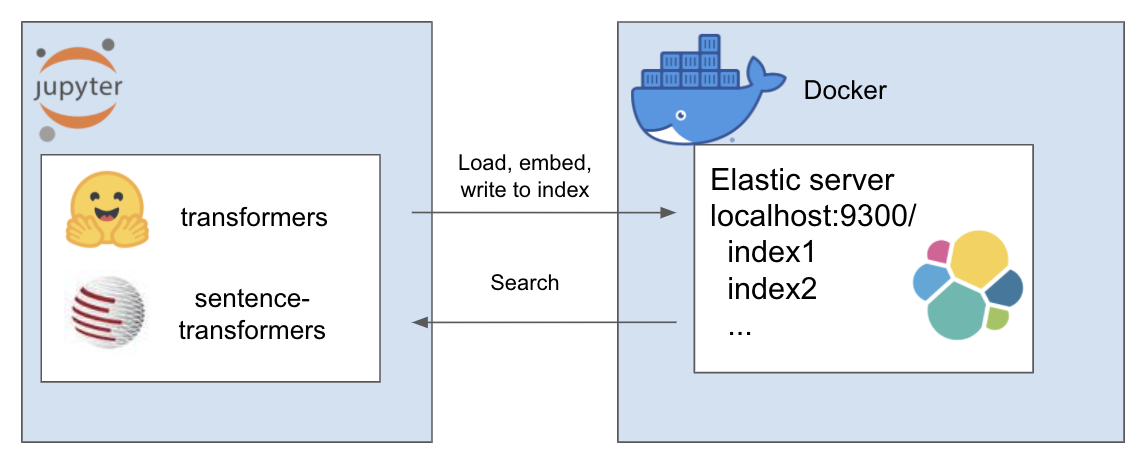
La configuration ci-dessus fonctionne comme suit
Mon environnement s'appelle et et j'utilise conda pour cela. Naviguez dans le répertoire du projet
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txtPour ce tutoriel, j'utilise A Million News Headlines de Rohk et je le place dans le dossier de données dans le répertoire du projet.
elastic_transformers/
├── data/
Vous constaterez que les étapes sont par ailleurs assez abstraites, vous pouvez donc également le faire avec l'ensemble de données de votre choix.
Suivez les instructions de configuration d'Elastic avec Docker sur la page d'Elastic ici. Pour ce didacticiel, il vous suffit d'exécuter les deux étapes :
Le dépôt introduit la classe ElasiticTransformers. Utilitaires permettant de créer, d'indexer et d'interroger des index Elasticsearch incluant des intégrations
Initier les liens de connexion ainsi que (éventuellement) le nom de l'index avec lequel travailler
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec définit le mappage pour l'index. Des listes de champs pertinents peuvent être fournies pour une recherche par mot-clé ou une recherche sémantique (vecteur dense). Il comporte également des paramètres pour la taille du vecteur dense, car ceux-ci peuvent varier. create_index - utilise la spécification créée précédemment pour créer un index prêt pour la recherche
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv - divise un gros fichier csv en morceaux et utilise de manière itérative un utilitaire d'intégration prédéfini pour créer la liste d'intégrations pour chaque morceau et ensuite transmettre les résultats à l'index
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )recherche - permet de sélectionner soit une recherche par mot-clé (« correspondance » dans Elastic) soit une recherche sémantique (dense dans Elastic). Il nécessite notamment la même fonction d'intégration utilisée dans write_large_csv
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )Une fois la configuration réussie, utilisez les cahiers suivants pour que tout cela fonctionne
Ce dépôt combine les œuvres étonnantes suivantes réalisées par des personnes brillantes. N'hésitez pas à consulter leur travail si vous ne l'avez pas encore fait...


