telegram archive server
v0.4.1 - 蔚蓝更新
Un robot de recherche et d'archivage de discussions de groupe Telegram adapté à l'environnement CJK.

Cliquez sur le bouton [Rechercher] pour vous authentifier automatiquement et ouvrir l'interface de recherche.
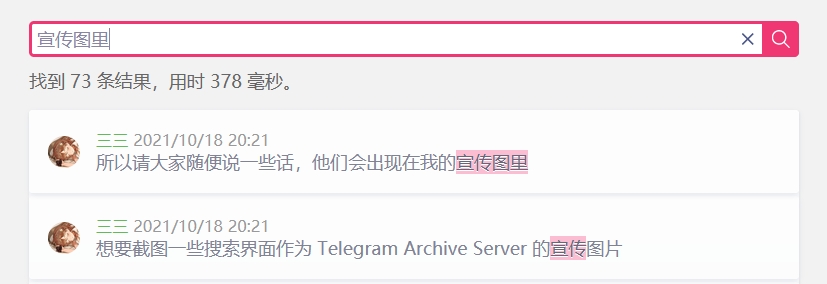
Cliquez sur le lien horaire pour accéder à l'interface de discussion.
vous devez:
Téléchargez le fichier .env.example , reportez-vous aux commentaires internes et configurez en conséquence.
Vous pouvez l'enregistrer au format .env ou le configurer en tant que variable d'environnement.
TAS ne fournit pas de service https intégré. Il est recommandé d'utiliser Caddy ou un logiciel similaire pour inverser le proxy TAS.
docker run -d --restart=always --env-file=.env quay.io/oott123/telegram-archive-serverBien sûr, vous pouvez également l'exécuter à l'aide de Kubernetes ou de docker-compose.
Si vous n'avez pas Docker ou ne souhaitez pas utiliser Docker, vous pouvez également compiler et déployer à partir du code source. À ce stade, vous avez également besoin de :
git clone https://github.com/oott123/telegram-archive-server.git
cd telegram-archive-server
# git checkout vX.X.X
cp .env.example .env
vim .env
yarn
yarn build
yarn start Envoyer /search dans le groupe. Le Bot peut vous inviter à définir le domaine, suivez simplement les invites.
Les utilisateurs doivent répondre aux critères suivants pour que leur avatar apparaisse dans les résultats de recherche :
Étant donné que MeiliSearch a une faible efficacité d'indexation pour les nouveaux messages, les messages n'entreront dans l'index que lorsque l'une des conditions suivantes est remplie :
Si redis n'est pas utilisé pour conserver la file d'attente des messages, les messages qui ne sont pas entrés dans la file d'attente peuvent être perdus lorsque le programme présente une anomalie ou que le serveur est redémarré.
Actuellement, seule l'importation de supergroupes est prise en charge.
Cliquez sur le bouton à trois points sur le client de bureau - Exporter l'historique des discussions, attendez la fin de l'exportation et obtenez result.json .
mettre en œuvre:
curl
-H " Content-Type: application/json "
-H " Authorization: Bearer $AUTH_IMPORT_TOKEN "
-XPOST -T result.json
http://localhost:3100/api/v1/import/fromTelegramGroupExportLes enregistrements peuvent être importés. Notez que seuls les enregistrements d'un seul groupe peuvent être importés à la fois.
Si vous activez la file d'attente OCR, Redis est requis (peut partager une instance avec le cache) et configurer un service de reconnaissance tiers. Le processus d'identification est le suivant :
La reconnaissance et le stockage peuvent être effectués sur différentes instances de rôle : le téléchargement d'images et le stockage de texte seront effectués sur l'instance du Bot, et l'instance OCR n'a besoin que d'accéder au service OCR.
Cette conception permet aux responsables de concevoir une identification centralisée hors ligne (par exemple, utiliser une instance préemptive pour exécuter le service d'identification et l'arrêter une fois la file d'attente effacée) afin de réduire les coûts d'identification.
Si vous utilisez un service cloud tiers, vous pouvez directement désactiver la file d'attente OCR ou activer les rôles Bot et OCR dans la même instance.
Reportez-vous à la documentation sur la reconnaissance de texte Google Cloud Vision et aux règles de facturation de Google Cloud Vision. La configuration est la suivante :
OCR_DRIVER=google
OCR_ENDPOINT=eu-vision.googleapis.com # 或者 us-vision.googleapis.com ,决定 Google 在何处存储处理数据
GOOGLE_APPLICATION_CREDENTIALS=/path/to/google/credentials.json # 从 GCP 后台下载的 json 鉴权文件Vous avez besoin d'une instance de paddleocr-web. La configuration est la suivante :
OCR_DRIVER=paddle-ocr-web
OCR_ENDPOINT=http://127.0.0.1:8980/apiCréez une ressource Azure Vision et configurez les informations sur la ressource comme suit :
OCR_DRIVER=azure
OCR_ENDPOINT=https://tas.cognitiveservices.azure.com
OCR_CREDENTIALS=000000000000000000000000000000000docker run [...] dist/main ocr,bot
# or
node dist/main ocr,botDEBUG=app: * ,grammy * yarn start:debug Une fois le service de recherche authentifié, le serveur accédera à : $HTTP_UI_URL/index.html avec les paramètres d'URL suivants :
tas_server - URL de base du serveur, sous la forme http://localhost:3100/api/v1tas_indexName - numéro de groupe, sous la forme de supergroup1234567890tas_authKey - JWT émis par le serveur, qui peut être utilisé comme clé API de MeiliSearch. /api/v1/search/compilable/meili peut être recherché comme une instance MeiliSearch normale.
Le nom de l'index doit utiliser un numéro de groupe sous la forme supergroup1234567890 ; la clé API est le JWT émis par le serveur.
Veuillez noter que le filtre est temporairement indisponible pour des raisons de sécurité.


