fine grained sentiment app streamlit
1.0.0
Ce dépôt contient l'équivalent Streamlit d'une application interactive existante, qui explique les résultats de la classification fine des sentiments, décrite en détail dans cette série moyenne.
Un certain nombre de classificateurs sont implémentés et leurs résultats expliqués à l'aide de l'explicateur LIME. Les classificateurs ont été formés sur l’ensemble de données Stanford Sentiment Treebank (SST-5). Les étiquettes de classe sont parmi [1, 2, 3, 4, 5] , où 1 est très négatif et 5 est très positif.
Streamlit est un framework léger et minimaliste pour créer des tableaux de bord en Python. L'objectif principal de Streamlit est de fournir aux développeurs la possibilité de prototyper rapidement leurs conceptions d'interface utilisateur en utilisant le moins de lignes de code possible. Toutes les tâches lourdes généralement nécessaires au déploiement d'une application Web, telles que la définition du serveur backend et de ses itinéraires, la gestion des requêtes HTTP, etc., sont soustraites à l'utilisateur. De ce fait, il devient très simple de mettre en œuvre rapidement une application web, quelle que soit l’expérience du développeur.
Tout d’abord, configurez l’environnement virtuel et installez à partir de requirements.txt :
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
Pour un développement ultérieur, activez simplement l’environnement virtuel existant.
source venv/bin/activate
Une fois l'environnement virtuel configuré et activé, exécutez l'application à l'aide de la commande ci-dessous.
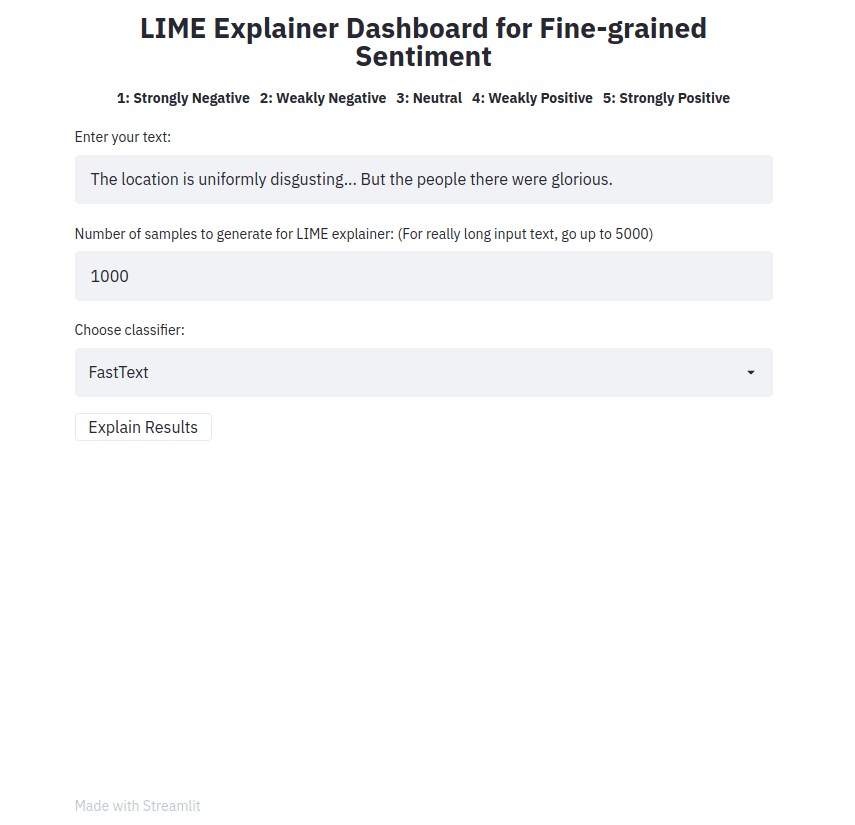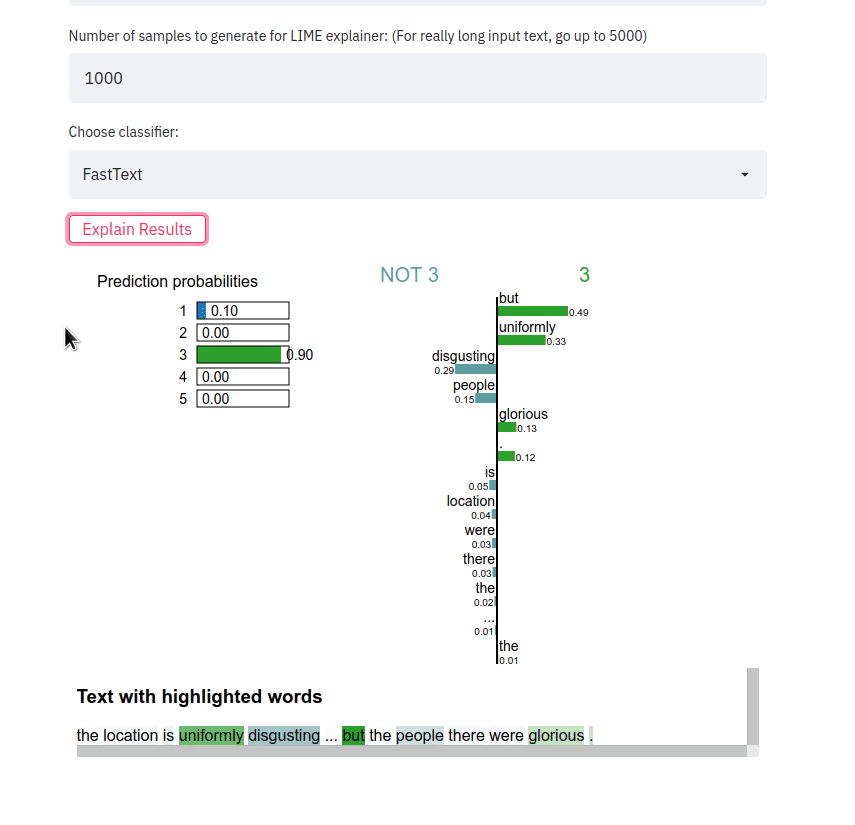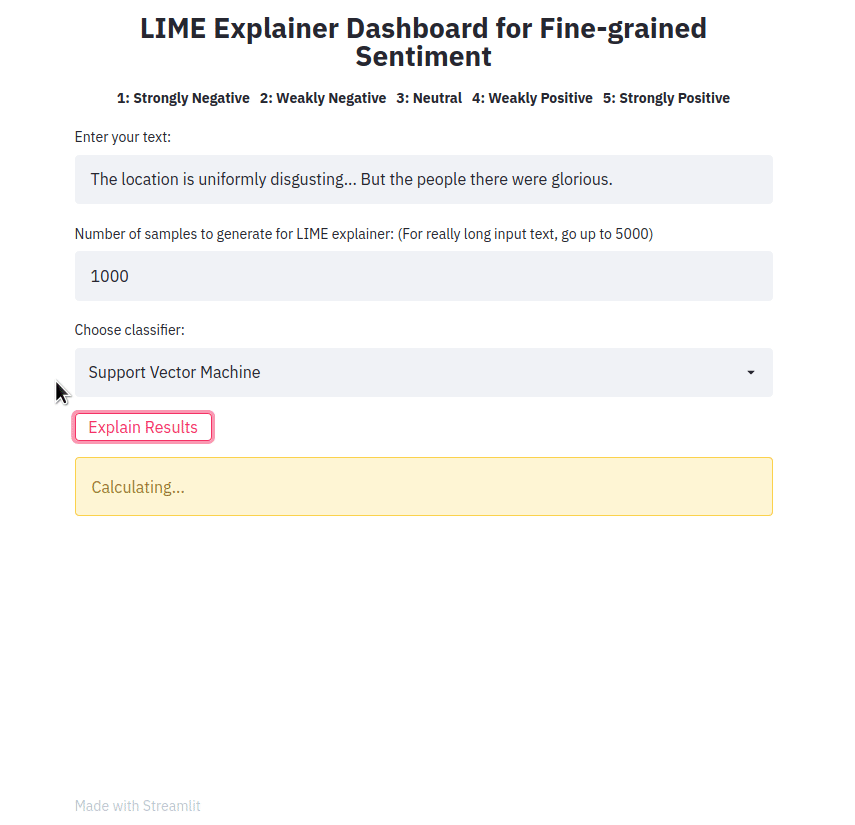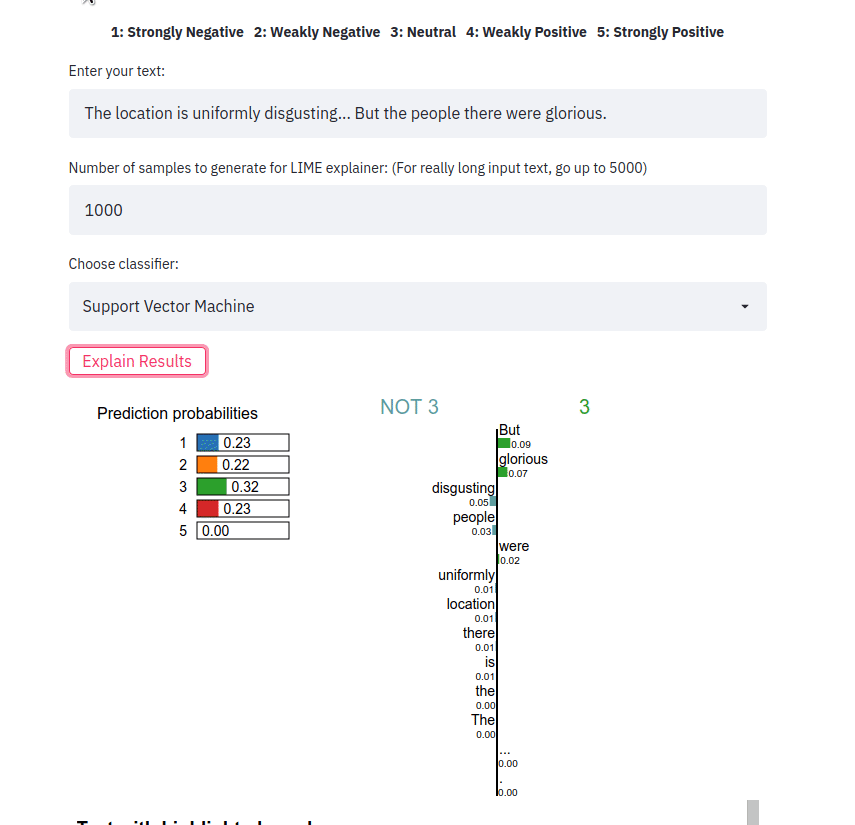
streamlit run app.py Saisissez une phrase, choisissez un type de classificateur et cliquez sur le bouton Explain results . Nous pouvons alors observer les caractéristiques (c'est-à-dire les mots ou les jetons) qui ont contribué à ce que le classificateur prédise une étiquette de classe particulière.
L'application frontale récupère un échantillon de texte et génère des explications LIME pour les différentes méthodes. L'application est déployée à l'aide de Heroku à cet emplacement : https://sst5-explainer-streamlit.herokuapp.com/
Jouez avec vos propres exemples de texte comme indiqué ci-dessous et voyez les résultats détaillés des sentiments expliqués !
REMARQUE : étant donné que les modèles basés sur PyTorch (Flair et le transformateur causal) sont assez coûteux à utiliser pour exécuter l'inférence (ils nécessitent un GPU), ces méthodes ne sont pas déployées. Cependant, ils peuvent être exécutés sur une instance locale de l'application.