pianola
1.0.0
 pianola en action" style="max-width: 100%;">
pianola en action" style="max-width: 100%;">
pianola est une application qui joue de la musique pour piano générée par l'IA. Les utilisateurs amorcent (c'est-à-dire « invitent ») le modèle d'IA en jouant des notes sur le clavier ou en choisissant des exemples d'extraits de morceaux classiques.
Dans ce fichier Lisez-moi, nous expliquons le fonctionnement de l'IA et entrons dans les détails de l'architecture du modèle.
La musique peut être représentée de nombreuses manières, allant des formes d'onde audio brutes aux normes MIDI semi-structurées. Au pianola , nous divisons les rythmes musicaux en intervalles réguliers et uniformes (par exemple doubles croches/demi-croches). Les notes jouées dans un intervalle sont considérées comme appartenant au même pas de temps, et une série de pas de temps forme une séquence. En utilisant la séquence basée sur une grille comme entrée, le modèle d'IA prédit les notes au pas de temps suivant, qui à son tour est utilisé comme entrée pour prédire le pas de temps suivant de manière autorégressive.
En plus des notes à jouer, le modèle prédit également la durée (durée pendant laquelle la note est maintenue enfoncée) et la vélocité (la force avec laquelle une touche est frappée) de chaque note.
Le modèle est composé de trois modules : un intégrateur, un transformateur et un décodeur. Ces modules empruntent à des architectures bien connues telles que les réseaux Inception, les transformateurs LLaMA et les chaînes de classificateurs multi-étiquettes, mais sont adaptés pour fonctionner avec des données musicales et combinés dans une approche nouvelle.
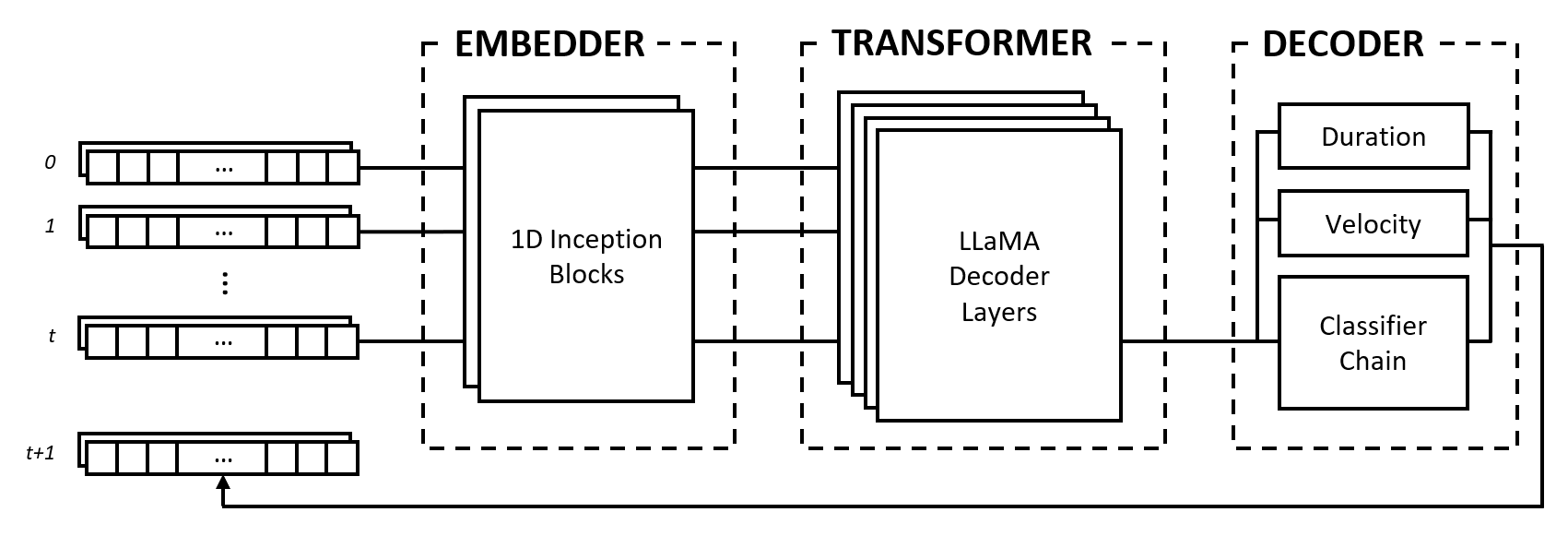
L'intégrateur convertit chaque pas de temps d'entrée de forme (num_notes, num_features) en un vecteur d'intégration qui peut être introduit dans le transformateur. Cependant, contrairement aux incorporations de texte qui mappent des vecteurs ponctuels sur un autre espace dimensionnel, nous fournissons un biais inductif en appliquant des couches convolutives et de regroupement sur l'entrée. Nous le faisons pour plusieurs raisons :
2^num_notes , où num_notes vaut 64 ou 88 pour les pianos courts à normaux), il n'est donc pas possible de les représenter comme des vecteurs uniques.Pour permettre à l'intégrateur d'apprendre quelles distances sont utiles, nous nous inspirons des réseaux Inception et empilons des convolutions de différentes tailles de noyau.
Le module de transformateur est composé de couches de transformateur LLaMA qui appliquent une auto-attention à la séquence de vecteurs d'intégration d'entrée.
Comme de nombreux modèles d'IA génératifs, ce module utilise uniquement la partie « décodeur » du modèle Transformers original de Vaswani et al. (2017). Nous utilisons ici le label « transformateur » pour différencier ce module du suivant, qui effectue le décodage proprement dit des états produits par les couches d'auto-attention.
Nous choisissons l'architecture LLaMA par rapport à d'autres types de transformateurs principalement parce qu'elle utilise des intégrations positionnelles rotatives (RoPE), qui codent les positions relatives avec une décroissance de la distance au fil du temps. Étant donné que nous représentons les données musicales sous forme d'intervalles fixes, les positions relatives ainsi que les distances entre les pas de temps sont des informations importantes que le transformateur peut explicitement utiliser pour comprendre et générer de la musique avec un rythme cohérent.
Le décodeur prend en compte les états surveillés et prédit les notes à jouer ainsi que leurs durées et vitesses. Le module est composé de plusieurs sous-composants, à savoir une chaîne de classificateurs pour la prédiction de notes et des perceptrons multicouches (MLP) pour les prédictions de caractéristiques.
La chaîne de classificateurs est constituée de classificateurs binaires num_notes , c'est-à-dire un pour chaque touche d'un piano, afin de créer un classificateur multi-étiquettes. Afin d'exploiter les corrélations entre les notes, les classificateurs binaires sont enchaînés de telle sorte que le résultat des notes précédentes affecte les prédictions des notes suivantes. Par exemple, s'il existe une corrélation positive entre les notes d'octave, une note inférieure active (par exemple C3 ) entraîne une probabilité plus élevée que la note la plus haute (par exemple C4 ) soit prédite. Ceci est également bénéfique dans les cas de corrélations négatives, où l'on peut choisir entre deux notes adjacentes qui aboutissent à une gamme majeure ou mineure (par exemple CDE vs CD-Eb ), mais pas les deux.
Pour des raisons d'efficacité de calcul, nous limitons la longueur de la chaîne à 12 maillons, soit une octave. Enfin, une stratégie de décodage par échantillonnage est utilisée pour sélectionner les notes par rapport à leurs probabilités de prédiction.
Les caractéristiques de durée et de vitesse sont traitées comme des problèmes de régression et sont prédites à l'aide de MLP vanille. Bien que les caractéristiques soient prédites pour chaque note, nous utilisons une fonction de perte personnalisée pendant la formation qui regroupe uniquement les pertes de caractéristiques des notes actives, similaire à la fonction de perte utilisée dans une classification d'images avec tâche de localisation.
Notre choix de représenter les données musicales sous forme de grille présente des avantages et des inconvénients. Nous discutons de ces points en le comparant au vocabulaire basé sur les événements proposé par Oore et al. (2018), une contribution très citée dans la génération musicale.
L’un des principaux avantages de notre approche est le découplage de la compréhension micro et macro de la musique, ce qui conduit à une séparation claire des tâches entre l’intégrateur et le transformateur. Le rôle du premier est d'interpréter l'interaction des notes à un niveau micro, par exemple la façon dont les distances relatives entre les notes forment des relations musicales comme des accords, et la tâche du second est de synthétiser ces informations dans la dimension du temps pour comprendre le style musical à un niveau macro. niveau.
En revanche, une représentation basée sur les événements place toute la charge sur un modèle de séquence pour interpréter les jetons uniques qui pourraient représenter la hauteur, le timing ou la vitesse, trois concepts distincts. Huang et coll. (2018) trouvent qu'il est nécessaire d'ajouter un mécanisme d'attention relative à leur modèle Transformer afin de générer des continuations cohérentes, ce qui suggère que le modèle nécessite un biais inductif pour bien fonctionner avec cette représentation.
Dans une représentation en grille, le choix de la longueur de l'intervalle est un compromis entre la fidélité des données et la rareté. Un intervalle plus long réduit la granularité des timings des notes, réduisant ainsi l'expressivité musicale et potentiellement compressant les éléments rapides comme les trilles et les notes répétées. D'un autre côté, un intervalle plus court augmente de manière exponentielle la parcimonie en introduisant de nombreux pas de temps vides, ce qui constitue un problème important pour les modèles Transformer car ils sont limités en longueur de séquence.
De plus, les données musicales peuvent être mappées sur une grille soit via le passage du temps ( 1 timestep == X milliseconds ) soit telles qu'elles sont écrites dans une partition ( 1 timestep == 1 sixteenth note/semiquaver ), chacune avec ses propres compromis. . Une représentation basée sur les événements évite complètement ces problèmes en spécifiant le passage du temps comme un événement.
Malgré ses inconvénients, la représentation en grille présente un avantage pratique dans la mesure où elle est beaucoup plus facile à utiliser lors du développement de pianola . La sortie du modèle est lisible par l'homme et le nombre de pas de temps correspond à une durée fixe, ce qui rend le développement de nouvelles fonctionnalités beaucoup plus rapide.
De plus, la recherche sur l'extension de la longueur des séquences des modèles Transformer et l'amélioration continue du matériel réduiront progressivement les problèmes causés par la rareté des données, et depuis fin 2023, nous voyons de grands modèles de langage capables de gérer des dizaines de milliers de jetons. À mesure que les techniques s’optimisent et que le matériel puissant devient plus accessible, nous pensons que la fidélité continuera de s’améliorer, tout comme elle l’a fait pour la génération d’images, conduisant à une plus grande expressivité et nuance dans la musique générée par l’IA.
Le code source de ce projet est visible publiquement à des fins de recherche universitaire et de partage des connaissances. Tous les droits sont conservés par le(s) créateur(s), sauf autorisation explicite accordée.
Icône du site modifiée à partir de Freepik - Flaticon.
Prenez contact sur Outlook.com à l'adresse bruce <dot> ckc .


