project omega
Le dernier modèle d'architecture Web d'entreprise dont vous aurez besoin. Jusqu'au prochain.
TL;DR
L’objectif est d’optimiser l’expérience développeur en étant capable de :
- Développer localement comme s'il s'agissait d'un monolithe
- Déployer en tant que microservices distincts
- Simuler l'environnement de production localement à l'aide de Docker
Démo
project omega Proof of Concept - Microservices Monolith Hybrid
Démo project omega - Microserves Kubernetes et déploiement de conteneurs autonomes
Pourquoi
Je veux prouver que nous n'avons pas à sacrifier l'efficacité des développeurs pour obtenir l'évolutivité. Plus de discussions sur les avantages et les inconvénients des microservices et des monolithes ici : Microservices et monolithes.
J’ai l’impression que de nombreux experts du secteur voudraient nous faire croire que ce sont nos 3 principales options :
- Monolithe
- Microservices
- "Hybride" (pas vraiment hybride, à la fois monolithique et aussi quelques microservices)
Je veux montrer que nous n’avons pas à choisir aucune de ces options. Avec un peu de créativité on peut avoir un véritable « hybride » qui est à la fois un monolithe et un ensemble de microservices. Avec ma stratégie actuelle, je ne pense pas que nous puissions éliminer tous les inconvénients du monolithe et des microservices, mais nous pouvons nous débarrasser de bon nombre des problèmes des deux.
Ce que ce n'est pas
- Je n'essaye pas de créer un framework (pas encore du moins...). Je suis juste en train de rassembler tous les legos que j'ai dans une configuration différente à titre expérimental.
- Il ne s’agit pas d’un projet communautaire. J'ai l'intention d'apporter fréquemment des changements spectaculaires sans préavis. Si ce concept vous semble intéressant et que vous souhaitez y contribuer, contactez-moi au préalable.
Objectifs du projet
- Créez un modèle qui fonctionnera pour des projets en tant que petits projets de loisir de développeur unique et qui s'adaptera également à des dizaines, voire des centaines de développeurs travaillant sur des applications Web d'entreprise vastes et complexes.
- Pouvoir se développer localement comme s'il s'agissait d'un monolithe :
- Un référentiel. Pour les mêmes raisons, les entreprises choisissent une approche monorepo.
- Maximum 3 processus à exécuter (interface utilisateur client, serveur, dépendances Docker avec base de données, file d'attente de messages, etc.). Nous ne voulons pas que les pages de documents d'installation soient opérationnelles.
- Être capable de déployer en tant que microservices.
- Être capable de simuler un environnement de production avec des microservices exécutés dans des conteneurs Docker.
- Temps de configuration extrêmement rapide. Toutes les dépendances autres que Node et .NET doivent être incluses en tant que dépendances Docker (base de données, file d'attente de messages, etc.). Les nouveaux utilisateurs devraient pouvoir installer .NET, Node, cloner le référentiel, puis exécuter les commandes d'installation et d'exécution.
- Rechargement à chaud extrêmement rapide pour le client et le serveur dans l'environnement de développement.
- Être capable de développer et d'exécuter l'application sur Windows, Linux et Mac.
- Être capable de lancer rapidement un nouveau service.
Pile technologique
La pile technologique n'est généralement pas pertinente pour le concept de haut niveau que j'essaie de prouver, mais pour ce projet, je vais utiliser :
- .NET 5 pour les services
- React front-end (create-react-app de base avec dactylographié)
- Docker
Concepts de haut niveau
Les entreprises ayant de grandes applications sont de plus en plus poussées vers les microservices afin de pouvoir évoluer horizontalement (entre autres raisons). Donc, pour y parvenir, nous envisageons quelque chose comme ce qui suit :
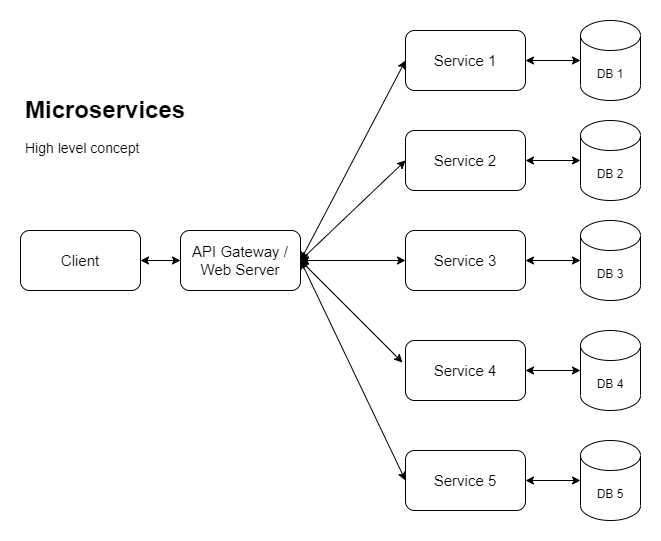
Voici une autre version montrant une façon dont la mise à l'échelle horizontale pourrait être implémentée :
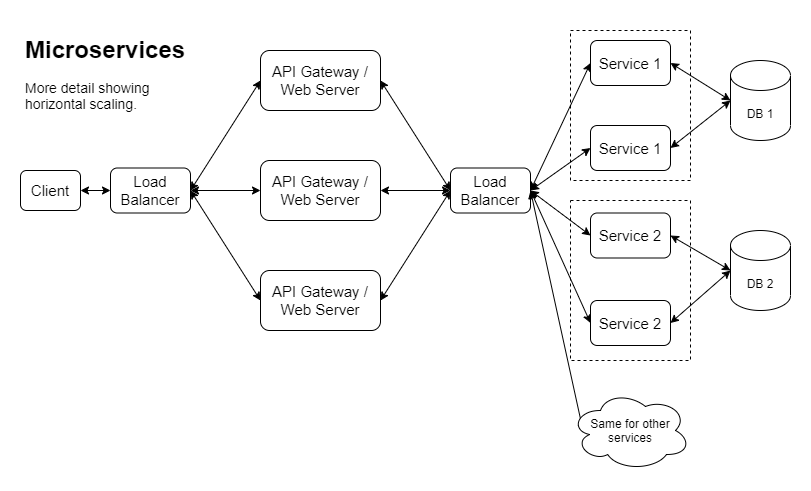
Une fois qu’on s’engage dans cette voie, on se retrouve avec un vrai problème de développement local. Cela dépend vraiment de la nature du produit, du nombre de développeurs, de qui travaille sur quoi et à quelle fréquence. Cela étant dit, une grande partie des entreprises qui choisissent les microservices se retrouveront dans une situation où les développeurs devront faire des choix difficiles sur la manière de réaliser leur développement quotidien. Avec project omega , l'objectif est de montrer que nous pouvons éliminer les frais liés à l'exécution d'un service localement en les combinant tous en une seule application tout en s'exécutant localement :
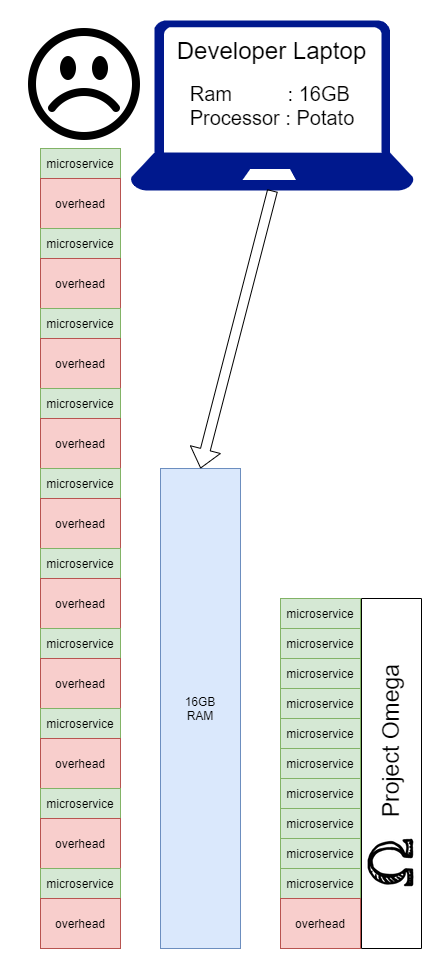
Voici la structure des dossiers :
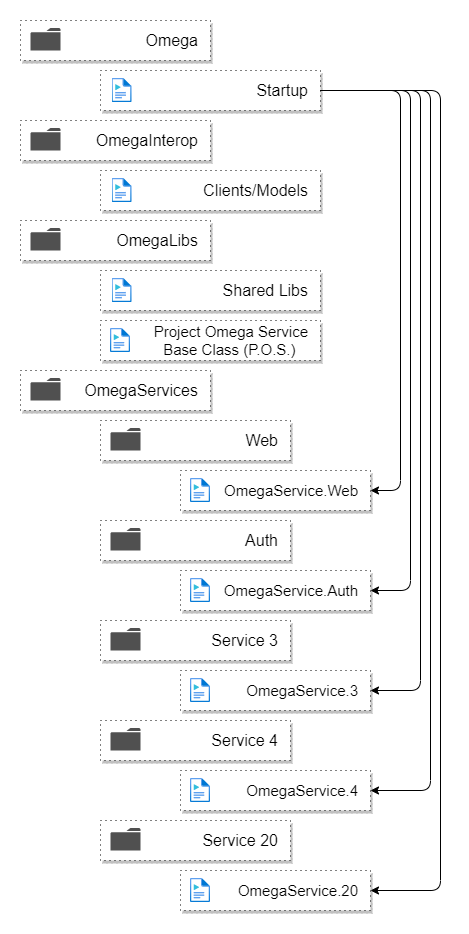
Et voici à quoi cela ressemblerait déployé en tant que microservices :
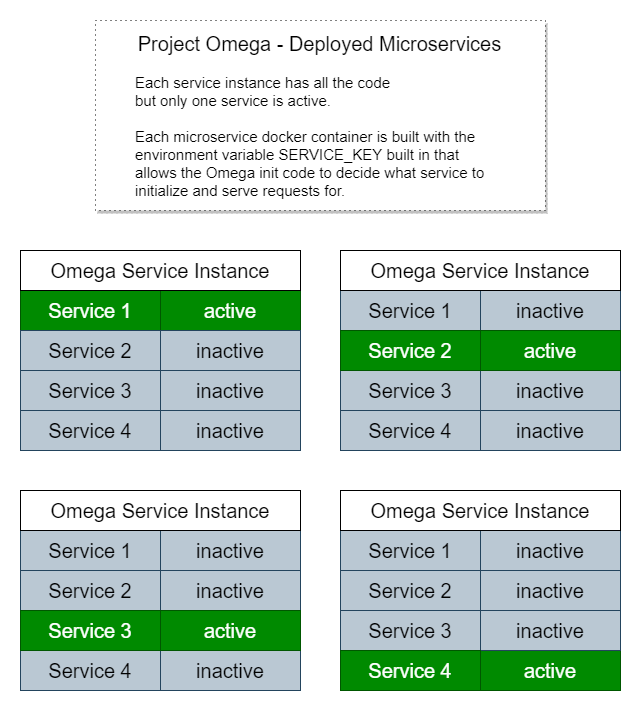
Chaque instance possède une copie de tout le code mais exécute uniquement l'initialisation, les routes des points de terminaison de service et les processus de travail pour un microservice spécifique.
C'est pourquoi il est si simple d'exécuter l'application localement comme un monolithe car nous recherchons simplement une variable d'environnement appelée SERVICE_KEY ou si elle n'est pas présente, initialisons tous les services.
Exemples d'autres initialisations spécifiques au service :
- Configuration de l'injection de dépendances
- Chaînes de connexion à la base de données
- Migration de bases de données
- Initialisation de la file d'attente des messages
- Configurer la connectivité du cache distribué
- Configuration d'une autre connectivité aux ressources cloud
- Initialisation de l'API tierce
Lorsque Startup est appelé, il analyse les assemblys pour les types qui héritent ProjectOmegaService , crée une instance et exécute la logique d'initialisation de ce service. Lors de l'exécution locale, il les exécutera tous.
Instructions de configuration
Installer les prérequis :
Notez que l'exécution de la dernière version de Docker sous Windows peut nécessiter quelques étapes supplémentaires si vous ne l'avez pas fait depuis un certain temps, comme l'installation de WSL 2 et l'actualisation de votre distribution WSL. Suivez les instructions sur le site Web de Docker.
Mesures:
- Cloner ce dépôt
- Dans un terminal à partir de la racine du dépôt, exécutez
yarn run installAll - Si vous souhaitez exécuter SQL Server sur un port autre que 1434 :
- Exécutez
yarn run syncEnvFiles - Modifiez
OMEGA_DEFAULT_DB_PORT et OMEGA_MSSQL_HOST_PORT dans .env.server
- Démarrez les dépendances à l'aide de la commande
yarn run dockerDepsUpDetached - Exécutez les migrations de bases de données la première fois que vous les exécutez ou lorsque vous recevez des modifications de quelqu'un d'autre avec les mises à jour de la base de données :
yarn run dbMigrate - Exécutez l'application en mode développement local en utilisant l'une de ces options :
- Option 1 : dans un terminal à partir de la racine du dépôt, exécutez
yarn run both (cela est utilisé simultanément pour exécuter les commandes des options 2) - Option 2 : utiliser 2 bornes distinctes. Dans un terminal, exécutez
yarn run client et dans l'autre, exécutez yarn run server Run
- Accédez à https://localhost:3000 (cliquez après l'avertissement https)
Avant d'exécuter des tests unitaires avec dotnet test pour la première fois ou après avoir ajouté des tests unitaires sur un nouveau schéma de base de données :
- Démarrez les dépendances si elles ne sont pas déjà en cours d'exécution avec
yarn run dockerDepsUpDetached - Exécuter
yarn run testDbMigrate - Ensuite, lancez
dotnet test
Pour simuler la production et les microservices dans Docker :
- Assurez-vous que les dépendances Docker sont en cours d'exécution avec
yarn run dockerDepsUpDetached - Dans un terminal à partir de la racine du dépôt, exécutez
yarn run dockerRecreateFull - Accédez à https://localhost:3000 (cliquez après l'avertissement https)
Prochaines étapes
- Journalisation des modifications
- Expérimentez avec le formateur Serilog json
- Ajouter un ID de corrélation et d'autres informations contextuelles aux entrées du journal
- Ajouter de la documentation supplémentaire
- Diagrammes du fonctionnement de la simulation Docker
- Dépendances Docker
- Description textuelle de ce que c'est, comment ça marche
- Diagrammes montrant comment Docker Deps s'intègre dans le processus de développement
- Documentation de routage/proxy
- Migration de bases de données
- Test RPC entre les services au lieu des appels de repos http (peut-être avec quelque chose comme ceci : https://github.com/aspnet/AspLabs/tree/main/src/GrpcHttpApi)
- Ajouter à la classe de base de clients interservices pour résumer la gestion et la journalisation des erreurs
- Implémentation de l'authentification
- Inscription au site frontal
- Authentification de service à service (OAuth ?)
- Génération automatique de documentation (sortie de documentation swagger et HTML XML)
- Services de configuration de file d’attente et de processus de travail
- Définition de file d'attente abstraite (pour permettre l'utilisation des services cloud en option)
- Service de type processus de travail de base avec une boucle d'événements recherchant des messages
- RabbitMQ dans docker-compose.deps.yml
- Implémentation de base de RabbitMQ connectée au service de processus de travail
- Travaux de démonstration supplémentaires de Kubernetes locaux
- La base de données nécessitera probablement d'apprendre à utiliser un volume persistant Kubernetes, à moins que je puisse comprendre comment ajuster la mise en réseau pour exposer la base de données hôte.
- Ajoutez Seq ou rendez la fonctionnalité Seq facultative et ne l'utilisez pas lors de l'exécution dans Kubernetes
- Métaprojet/script pour analyser la solution
- Analyser les services concernés en fonction des fichiers modifiés (pour la granularité du déploiement)
- Échafaudage du projet :
- Possibilité de lancer une nouvelle copie du projet en utilisant une autre "clé" de projet en plus d'Omega pour tous les noms de projet/répertoire
- Capacité à faire tourner un nouveau projet dans des conteneurs Docker et à effectuer des tests d'intégration efficaces pour garantir la réussite de la création d'un nouveau projet
Divers
Si vous développez sous Linux, vous pouvez rencontrer cette erreur lors du démarrage du serveur :
System.AggregateException : une ou plusieurs erreurs se sont produites. (La limite utilisateur configurée (128) sur le nombre d'instances inotify a été atteinte, ou la limite par processus sur le nombre de descripteurs de fichiers ouverts a été atteinte.)
Cela est probablement dû à un trop grand nombre de surveillances de fichiers utilisées par vscode. Vous pouvez augmenter votre limite d'instances inotify (pas seulement la limite de surveillance, qui est probablement déjà définie très haut dans votre fichier /etc/sysctl.conf ) en exécutant cette commande :
echo fs.inotify.max_user_instances=524288 | sudo tee -a /etc/sysctl.conf && sudo sysctl -p
Autres documents
Analyse coûts-avantages du modèle de conception : DesignPatternCostBenefit.md
Variations du modèle de conception : DesignPatternVariations.md
Décisions : Décisions.md
Philosophies et discours de développement logiciel : https://gist.github.com/mikey-t/3d5d6f0f5316abf9e74fb553be9fdef3


