nnl
gpt2-xl assets
nnl est un moteur d'inférence pour les grands modèles sur une plate-forme GPU à faible mémoire.
Les gros modèles sont trop volumineux pour tenir dans la mémoire du GPU. nnl résout ce problème avec un compromis entre la bande passante PCIE et la mémoire.
Un pipeline d'inférence typique est le suivant :
Avec le pool de mémoire GPU et la défragmentation de la mémoire, NNIL permet d'inférer un grand modèle sur une plateforme GPU bas de gamme.
Il ne s'agit que d'un projet de loisir rédigé en quelques semaines, actuellement seul le backend CUDA est pris en charge.
make lib nnl _cuda.a && make lib nnl _cuda_kernels.aCette commande construira les deux bibliothèques statiques : lib/lib nnl _cuda.a et lib/lib nnl _cuda_kernels.a . La première est la bibliothèque principale avec le backend CUDA en C++, et la seconde est destinée aux noyaux CUDA.
Un programme de démonstration de GPT2-XL (1.6B) est fourni ici. Ce programme peut être compilé par cette commande :
make gpt2_1558mAprès avoir téléchargé tous les poids de la version, nous pouvons exécuter la commande suivante sur une plate-forme GPU bas de gamme telle que GTX 1050 (2 Go de mémoire) :
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer " Et le résultat est comme ceci : 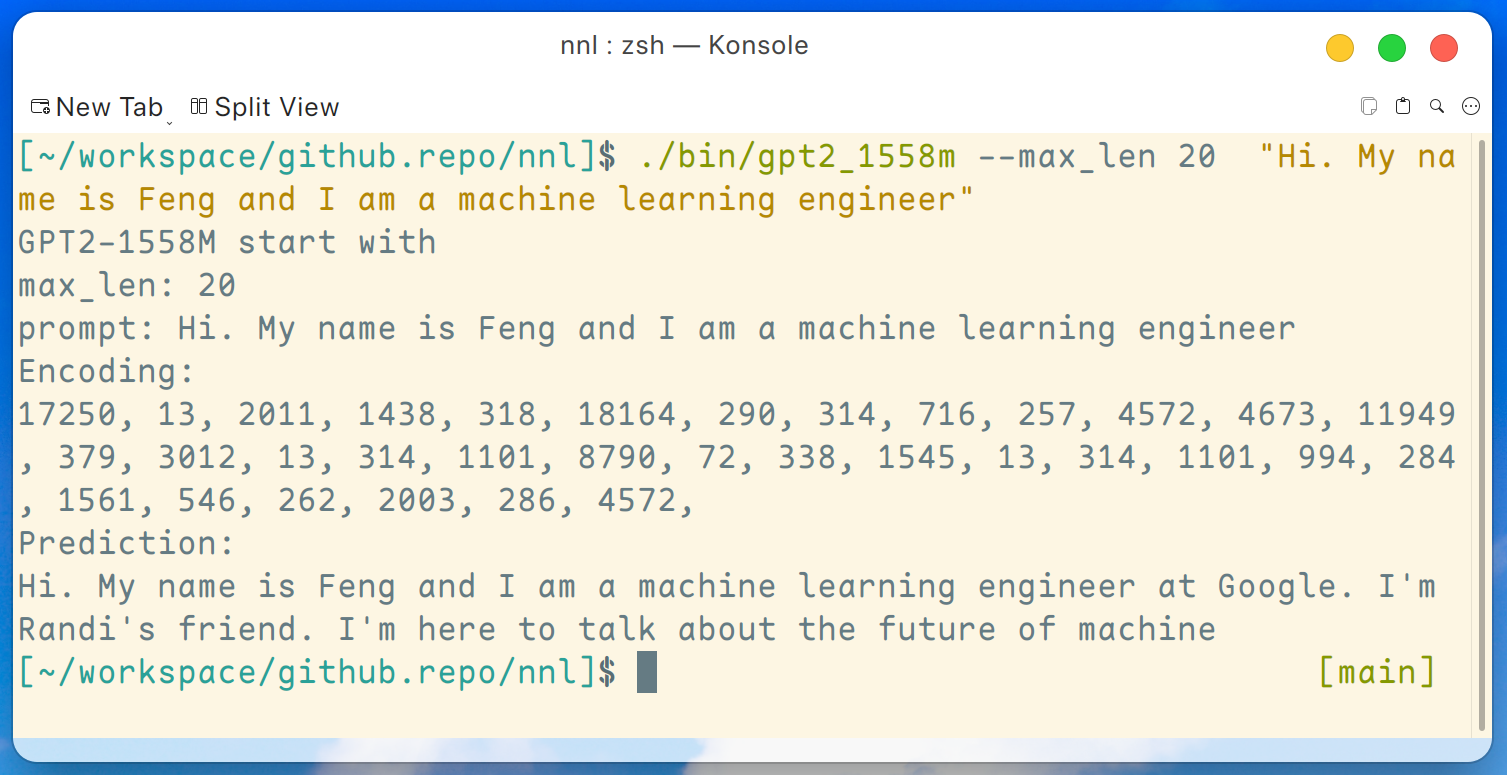
Avertissement : ce n'est qu'un exemple généré par gpt2-xl, je ne travaille pas chez Google et je ne connais pas Randi.
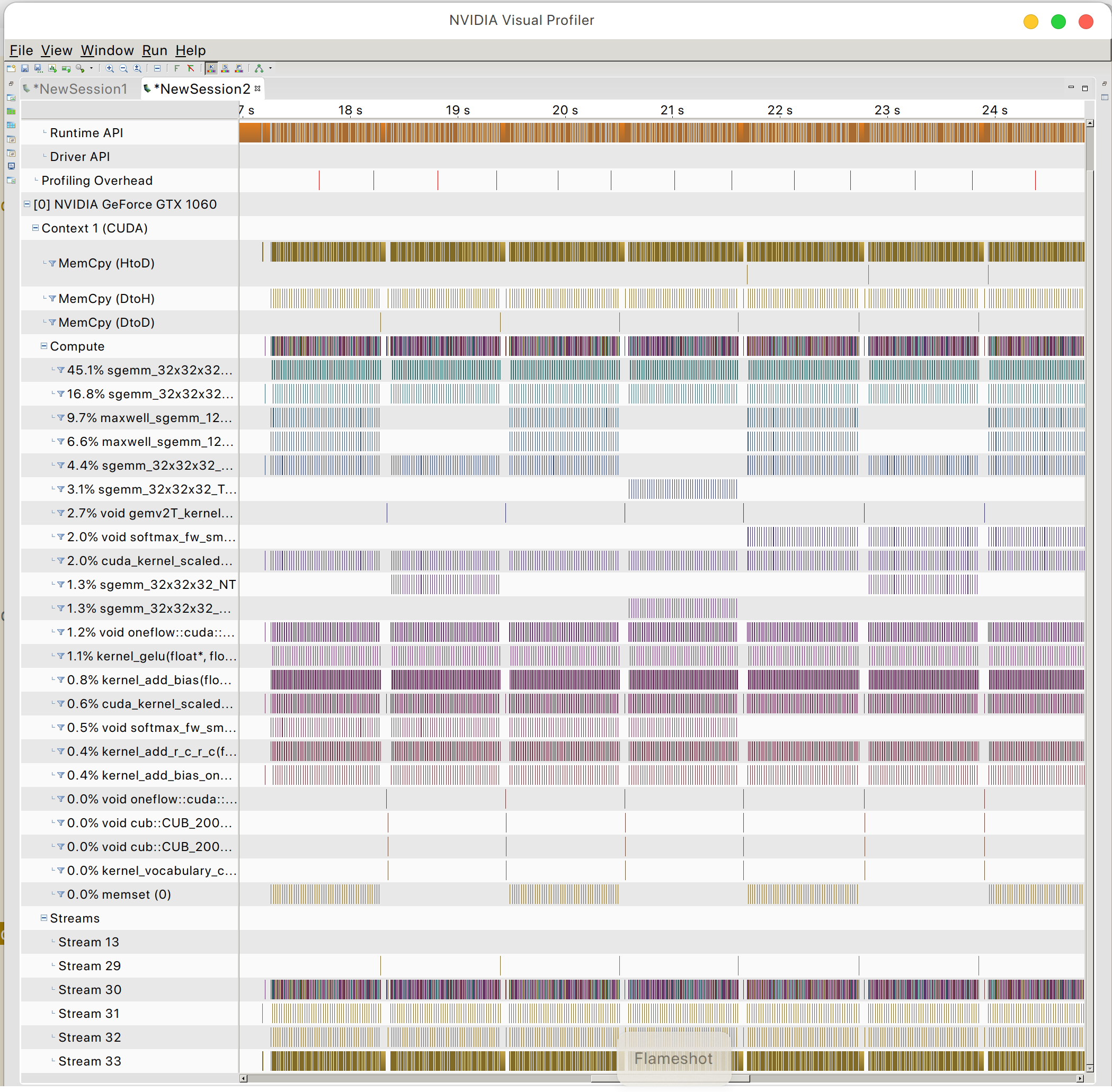
Et vous pouvez trouver le modèle d'accès à la mémoire GPU
PaixOSL