UniIR
1.0.0
Page d'accueil | ? Ensemble de données (référence M-BEIR) | ? Points de contrôle (modèles UniIR ) | arXiv | GitHub
Ce référentiel contient la base de code de l'article ECCV-2024 " UniIR : Training and Benchmarking Universal Multimodal Information Retrievers"
Nous proposons le cadre UniIR (Universal multimodal Information Retrieval) pour apprendre à un seul récupérateur à accomplir (éventuellement) n'importe quelle tâche de récupération. Contrairement aux systèmes IR traditionnels, UniIR doit suivre les instructions pour répondre à une requête hétérogène afin de récupérer un pool de candidats hétérogènes comprenant des millions de candidats dans diverses modalités.
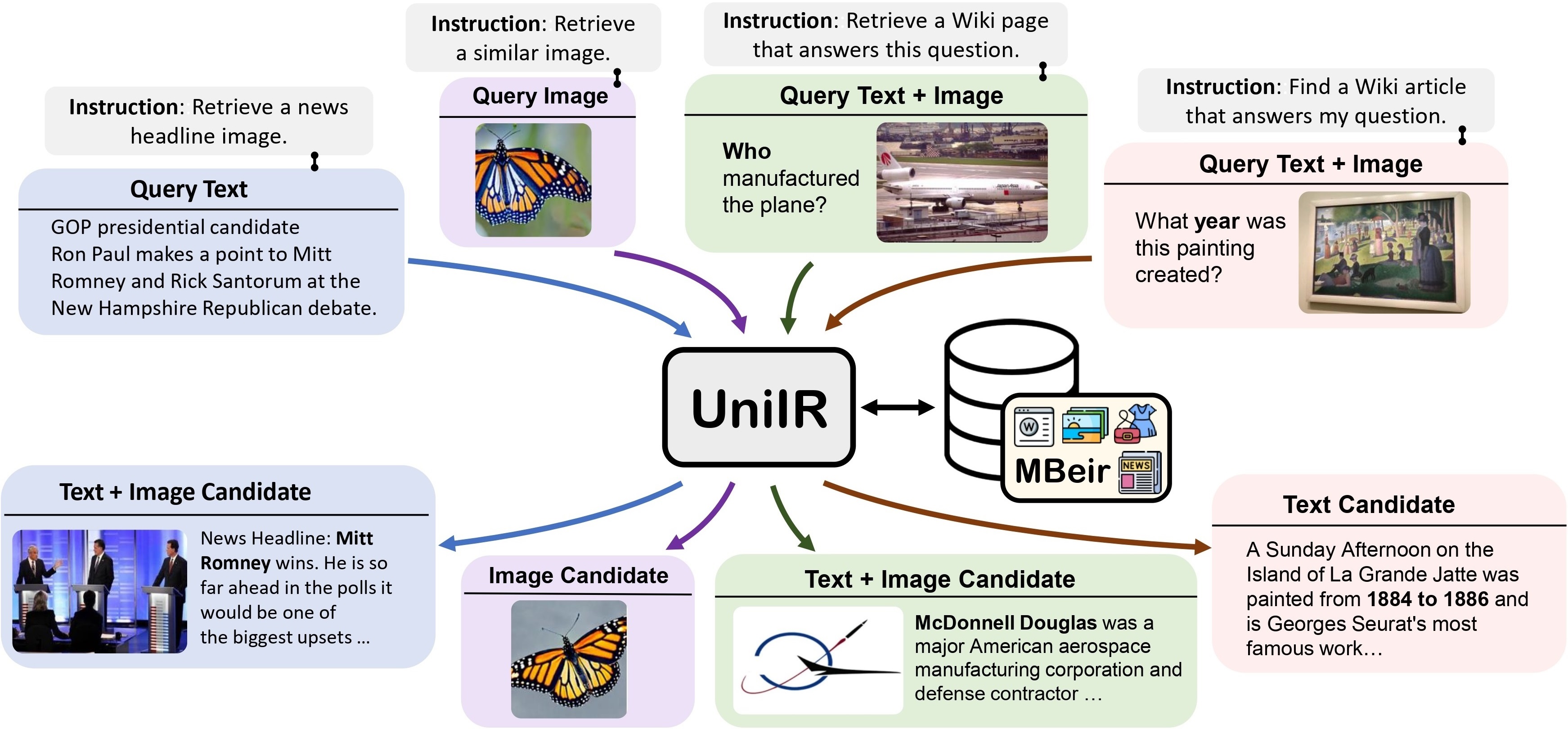 UniIR Teaser" style="largeur : 80 % ; largeur maximale : 100 % ;">
UniIR Teaser" style="largeur : 80 % ; largeur maximale : 100 % ;">
Pour former et évaluer des modèles de récupération multimodaux universels, nous construisons un benchmark de récupération à grande échelle nommé M-BEIR (Multimodal BEnchmark for Instructed Retrieval).
Nous fournissons l'ensemble de données M-BEIR dans le ? Ensemble de données . Veuillez suivre les instructions fournies sur la page HF pour télécharger l'ensemble de données et préparer les données pour la formation et l'évaluation. Vous devez configurer GiT LFS et cloner directement le dépôt :
git clone https://huggingface.co/datasets/TIGER-Lab/M-BEIR
Nous fournissons la base de code pour la formation et l'évaluation des modèles UniIR CLIP-ScoreFusion, CLIP-FeatureFusion, BLIP-ScoreFusion et BLIP-FeatureFusion.
Préparez la base de code du projet UniIR et de l'environnement Conda à l'aide des commandes suivantes :
git clone https://github.com/TIGER-AI-Lab/UniIR
cd UniIR
cd src/models/
conda env create -f UniIR _env.ymlPour entraîner les modèles UniIR à partir de points de contrôle CLIP et BLIP pré-entraînés, veuillez suivre les instructions ci-dessous. Les scripts téléchargeront automatiquement les points de contrôle CLIP et BLIP pré-entraînés.
Veuillez télécharger le benchmark M-BEIR en suivant les instructions de la section M-BEIR .
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/train/inbatch/ Modifiez inbatch.yaml pour le réglage des hyperparamètres et run_inbatch.sh pour votre propre environnement et vos chemins.
UniIR _DIR dans run_inbatch.sh vers le répertoire dans lequel vous souhaitez stocker les points de contrôle.MBEIR_DATA_DIR dans run_inbatch.sh vers le répertoire dans lequel vous stockez le benchmark M-BEIR.SRC_DIR dans run_inbatch.sh vers le répertoire où vous stockez la base de code du projet UniIR (ce dépôt)..env avec WANDB_API_KEY , WANDB_PROJECT et WANDB_ENTITY est défini.Vous pouvez ensuite exécuter la commande suivante pour entraîner le modèle UniIR CLIP_SF Large.
bash run_inbatch.sh cd src/models/ UniIR _blip/blip_featurefusion/configs_scripts/large/train/inbatch/ Modifiez inbatch.yaml pour le réglage des hyperparamètres et run_inbatch.sh pour votre propre environnement et vos chemins.
bash run_inbatch.shNous fournissons le pipeline d'évaluation des modèles UniIR sur le benchmark M-BEIR.
Veuillez créer un environnement pour la bibliothèque FAISS :
# From the root directory of the project
cd src/common/
conda env create -f faiss_env.ymlVeuillez télécharger le benchmark M-BEIR en suivant les instructions de la section M-BEIR .
Vous pouvez entraîner les modèles UniIR à partir de zéro ou télécharger les points de contrôle UniIR pré-entraînés en suivant les instructions de la section Model Zoo .
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/eval/inbatch/ Modifiez embed.yaml , index.yaml , retrieval.yaml et run_eval_pipeline_inbatch.sh pour votre propre environnement, chemins et paramètres d'évaluation.
UniIR _DIR dans run_eval_pipeline_inbatch.sh vers le répertoire dans lequel vous souhaitez stocker les fichiers volumineux, y compris les points de contrôle, les intégrations, les index et les résultats de récupération. Ensuite, vous pouvez placer le fichier clip_sf_large.pth dans le chemin suivant : $ UniIR _DIR /checkpoint/CLIP_SF/Large/Instruct/InBatch/clip_sf_large.pthmodel.ckpt_config dans le fichier embed.yaml .MBEIR_DATA_DIR dans run_eval_pipeline_inbatch.sh vers le répertoire dans lequel vous stockez le benchmark M-BEIR.SRC_DIR dans run_eval_pipeline_inbatch.sh vers le répertoire où vous stockez la base de code du projet UniIR (ce dépôt). La configuration par défaut évaluera le modèle UniIR CLIP_SF Large sur les benchmarks M-BEIR (pool de candidats hétérogènes de 5,6 millions) et M-BEIR_local (pool de candidats homogènes). UNION dans les fichiers yaml fait référence au M-BEIR (pool de candidats hétérogènes de 5,6 millions). Vous pouvez suivre les commentaires dans les fichiers yaml et modifier les configurations pour évaluer le modèle sur le benchmark M-BEIR_local uniquement.
bash run_eval_pipeline_inbatch.sh embed , index , logger et retrieval_results seront enregistrés dans le répertoire $ UniIR _DIR .
cd src/models/unii_blip/blip_featurefusion/configs_scripts/large/eval/inbatch/ De même, si vous téléchargez notre modèle UniIR pré-entraîné, vous pouvez placer le fichier blip_ff_large.pth dans le chemin suivant :
$ UniIR _DIR /checkpoint/BLIP_FF/Large/Instruct/InBatch/blip_ff_large.pthLa configuration par défaut évaluera le modèle UniIR BLIP_FF Large sur les benchmarks M-BEIR et M-BEIR_local.
bash run_eval_pipeline_inbatch.shL'évaluation UniRAG est très similaire à l'évaluation par défaut avec les différences suivantes :
retrieval_results . Ceci est utile lorsque les résultats récupérés seront utilisés dans des applications en aval telles que RAG.retrieve_image_text_pairs dans retrieval.yaml est défini sur True , un candidat complémentaire sera récupéré pour chaque candidat avec une modalité text ou image uniquement. Avec ce paramétrage, le candidat et son complément auront toujours une modalité image, text . Les candidats complémentaires sont récupérés en utilisant les candidats originaux comme requêtes (par exemple, texte de requête -> image candidate -> texte candidat complémentaire ).InBatch et inbatch par UniRAG et unirag . Nous fournissons les points de contrôle du modèle UniIR dans le ? Points de contrôle . Vous pouvez utiliser directement les points de contrôle pour les tâches de récupération ou affiner les modèles pour vos propres tâches de récupération.
| Nom du modèle | Version | Taille du modèle | Lien du modèle |
|---|---|---|---|
| UniIR (CLIP-SF) | Grand | 5,13 Go | Lien de téléchargement |
| UniIR (BLIP-FF) | Grand | 7,49 Go | Lien de téléchargement |
Vous pouvez les télécharger par
git clone https://huggingface.co/TIGER-Lab/UniIR
BibTeX :
@article { wei2023 UniIR ,
title = { UniIR : Training and benchmarking universal multimodal information retrievers } ,
author = { Wei, Cong and Chen, Yang and Chen, Haonan and Hu, Hexiang and Zhang, Ge and Fu, Jie and Ritter, Alan and Chen, Wenhu } ,
journal = { arXiv preprint arXiv:2311.17136 } ,
year = { 2023 }
}

