DiSQ Score
1.0.0
Implémentation officielle de notre article : Questionnement socratique discursif : évaluation de la fidélité des modèles linguistiques à la compréhension des relations discursives (2024) Yisong Miao, Hongfu Liu, Wenqiang Lei, Nancy F. Chen, Min-Yen Kan. ACL 2024.
Document PDF : https://yisong.me/publications/acl24-DiSQ-CR.pdf
Diapositives : https://yisong.me/publications/acl24-DiSQ-Slides.pdf
Affiche : https://yisong.me/publications/acl24-DiSQ-Poster.pdf
git clone [email protected]:YisongMiao/DiSQ-Score.git
conda activate
cd DiSQ-Score
cd scripts
pip install -r requirements.txt
Souhaitez-vous connaître le DiSQ Score pour n’importe quel modèle de langage ? Vous êtes invités à utiliser cette commande sur une seule ligne !

Nous fournissons une commande simplifiée pour évaluer tout modèle de langage (LM) hébergé dans le hub de modèles HuggingFace. Il est recommandé de l'utiliser pour tout nouveau modèle (en particulier ceux non étudiés dans notre article).
bash scripts/one_model.sh <modelurl>
La variable < modelurl > spécifie le chemin raccourci dans le hub Huggingface, par exemple :
bash scripts/one_model.sh meta-llama/Meta-Llama-3-8B
Avant d'exécuter les fichiers bash, veuillez modifier le fichier bash pour spécifier votre chemin vers votre cache HuggingFace local.
Par exemple, dans scripts/one_model.sh :
#!/bin/bash
# Please define your own path here
huggingface_path=YOUR_PATH
vous pouvez remplacer YOUR_PATH par l'emplacement du répertoire absolu de votre cache Huggingface (par exemple /disk1/yisong/hf-cache ).
Nous recommandons au moins 200 Go d'espace libre.
Un fichier texte de sortie sera enregistré dans data/results/verbalizations/Meta-Llama-3-8B.txt , qui contient :
=== The results for model: Meta-Llama-3-8B ===
Dataset: pdtb
DiSQ Score : 0.206
Targeted Score: 0.345
Counterfactual Score: 0.722
Consistency: 0.827
DiSQ Score for Comparison.Concession: 0.188
DiSQ Score for Comparison.Contrast: 0.22
DiSQ Score for Contingency.Reason: 0.164
DiSQ Score for Contingency.Result: 0.177
DiSQ Score for Expansion.Conjunction: 0.261
DiSQ Score for Expansion.Equivalence: 0.221
DiSQ Score for Expansion.Instantiation: 0.191
DiSQ Score for Expansion.Level-of-detail: 0.195
DiSQ Score for Expansion.Substitution: 0.151
DiSQ Score for Temporal.Asynchronous: 0.312
DiSQ Score for Temporal.Synchronous: 0.084
=== End of the results for model: Meta-Llama-3-8B ===
=== The results for model: Meta-Llama-3-8B ===
Dataset: ted
DiSQ Score : 0.233
Targeted Score: 0.605
Counterfactual Score: 0.489
Consistency: 0.787
DiSQ Score for Comparison.Concession: 0.237
DiSQ Score for Comparison.Contrast: 0.268
DiSQ Score for Contingency.Reason: 0.136
DiSQ Score for Contingency.Result: 0.211
DiSQ Score for Expansion.Conjunction: 0.268
DiSQ Score for Expansion.Equivalence: 0.205
DiSQ Score for Expansion.Instantiation: 0.194
DiSQ Score for Expansion.Level-of-detail: 0.222
DiSQ Score for Expansion.Substitution: 0.176
DiSQ Score for Temporal.Asynchronous: 0.156
DiSQ Score for Temporal.Synchronous: 0.164
=== End of the results for model: Meta-Llama-3-8B ===
Nous stockons nos ensembles de données dans des fichiers JSON situés dans data/datasets/dataset_pdtb.json et data/datasets/dataset_ted.json . Par exemple, prenons une instance de l'ensemble de données PDTB :
"2": {
"Didx": 2,
"arg1": "and special consultants are springing up to exploit the new tool",
"arg2": "Blair Entertainment, has just formed a subsidiary -- 900 Blair -- to apply the technology to television",
"DR": "Expansion.Instantiation.Arg2-as-instance",
"Conn": "for instance",
"events": [
[
"special consultants springing",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
],
[
"special consultants exploit the new tool",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
]
],
"context": "Other long-distance carriers have also begun marketing enhanced 900 service, and special consultants are springing up to exploit the new tool. Blair Entertainment, a New York firm that advises TV stations and sells ads for them, has just formed a subsidiary -- 900 Blair -- to apply the technology to television. "
},
Voici les champs de cette entrée de dictionnaire :
Didx : L'ID du discours.arg1 et arg2 : Les deux arguments.DR : La relation discursive.Conn : Le connecteur du discours.events : une liste de paires, stockant les paires d'événements prédites comme signaux saillants.context : Le contexte du discours. cd DiSQ-Score
bash scripts/question_generation.sh
Ce fichier bash appellera question_generation.py pour générer des questions sous différentes configurations.
Les arguments de question_generation.py sont les suivants :
--dataset : Spécifie l'ensemble de données, soit pdtb , soit ted .--modelname : des alias pour les modèles ont été créés. 13b fait référence à LLaMA2-13B, 13bchat à LLaMA2-13B-Chat et vicuna-13b à Vicuna-13B. Les URL spécifiques à ces modèles peuvent être trouvées dans disq_config.py .--version : Spécifie la version des modèles d'invite à utiliser, avec les options v1 , v2 , v3 et v4 .--paraphrase : Remplace les questions standards par leurs versions paraphrasées, avec les options p1 et p2 . Contrairement aux fonctions standard qui appellent qa_utils.py , les fonctions paraphrasées appellent respectivement qa_utils_p1.py et qa_utils_p2.py .--feature : Spécifie les fonctionnalités linguistiques à utiliser pour les questions de discussion. Les caractéristiques linguistiques incluent conn (connectif de discours) et context (contexte de discours). Les données historiques d’assurance qualité nécessitent un script distinct. La sortie sera stockée, par exemple, dans data/questions/dataset_pdtb_prompt_v1.json sous la configuration dataset==pdtb et version==v1 .
Nous demandons à nos utilisateurs de générer eux-mêmes les questions car cette approche est automatique et permet d'économiser de l'espace dans notre référentiel GitHub (qui pourrait totaliser environ 200 Mo). Si vous ne parvenez pas à exécuter le fichier bash, veuillez nous contacter pour les fichiers de questions.
cd DiSQ-Score
bash scripts/question_answering.sh
Ce fichier bash appellera question_answering.py pour effectuer un questionnement socratique discursif (DiSQ) pour n'importe quel modèle donné. question_answering.py prend tous les arguments de question_generation.py , plus les nouveaux arguments suivants :
--modelurl : Spécifie l'URL de tous les nouveaux modèles qui ne figurent pas actuellement dans le fichier de configuration. Par exemple, 'meta-llama/Meta-Llama-3-8B' spécifie le modèle LLaMA3-8B et écrasera l'argument modelname .--hf-path : Spécifie le chemin pour stocker les grands paramètres du modèle. Au moins 200 Go d'espace disque libre sont recommandés.--device_number : Spécifie l'ID du GPU à utiliser. La sortie sera stockée, par exemple, dans data/results/13bchat_dataset_pdtb_prompt_v1/ . La prédiction pour chaque question est une liste de jetons et leurs probabilités, stockés dans un fichier pickle au sein du dossier.
Attention : le modèle Wizard a été supprimé par les développeurs. Nous conseillons aux utilisateurs de ne pas essayer ces modèles. Consultez le fil de discussion sur : https://huggingface.co/posts/WizardLM/329547800484476.
cd DiSQ-Score
bash scripts/eval.sh
Ce fichier bash appellera eval.py pour évaluer les prédictions du modèle précédemment obtenues.
eval.py prend le même ensemble de paramètres que question_answering.py .
Le résultat de l'évaluation sera stocké dans disq_score_pdtb.csv si l'ensemble de données spécifié est PDTB.
Il y a 20 colonnes dans le fichier CSV, à savoir :
taskcode : indique la configuration en cours de test, par exemple dataset_pdtb_prompt_v1_13bchat .modelname : Spécifie quel modèle de langage est testé.version : indique la version de l'invite.paraphrase : Le paramètre pour paraphrase.feature : Spécifie quelle fonctionnalité a été utilisée.Overall : Le DiSQ Score global.Targeted : Score ciblé, une des trois composantes du DiSQ Score .Counterfactual : Score contrefactuel, l'une des trois composantes du DiSQ Score .Consistency : Score de cohérence, une des trois composantes du DiSQ Score .Comparison.Concession : Le DiSQ Score pour cette relation discursive spécifique.Notez que nous choisissons les meilleurs résultats parmi les versions v1 à v4 pour marginaliser l'impact des modèles d'invite.
Pour ce faire, eval.py extrait automatiquement les meilleurs résultats :
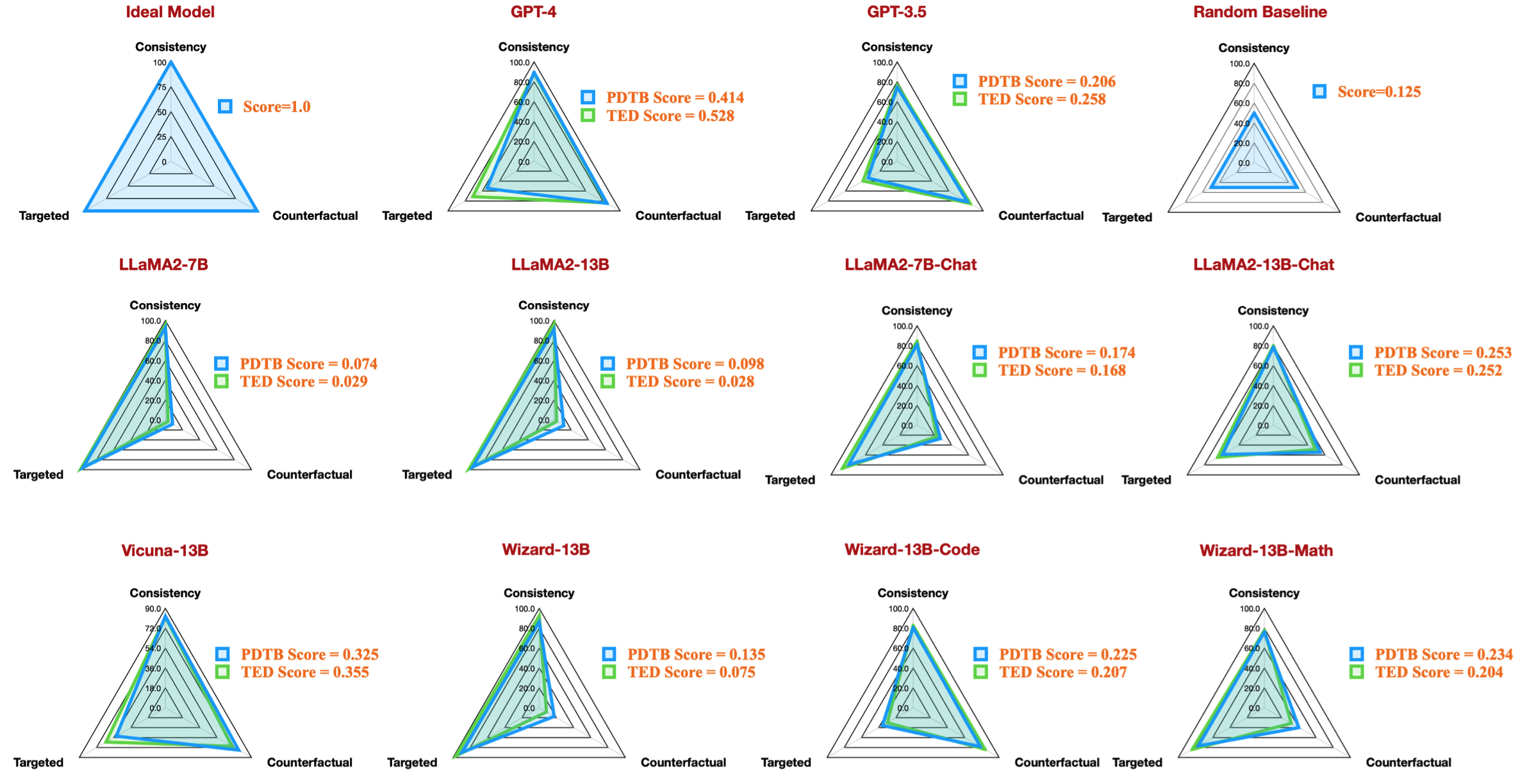
| code de tâche | nom du modèle | version | paraphrase | fonctionnalité | Dans l'ensemble | Ciblé | Contrefactuel | Cohérence | Comparaison.Concession | Comparaison.Contraste | Contingence.Raison | Contingence.Résultat | Expansion.Conjonction | Expansion.Équivalence | Expansion.Instanciation | Expansion.Niveau de détail | Expansion.Substitution | Temporel.Asynchrone | Temporel.Synchrone |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| dataset_pdtb_prompt_v4_7b | 7b | v4 | 0,074 | 0,956 | 0,084 | 0,929 | 0,03 | 0,083 | 0,095 | 0,095 | 0,077 | 0,054 | 0,086 | 0,068 | 0,155 | 0,036 | 0,047 | ||
| dataset_pdtb_prompt_v1_7bchat | 7bchat | v1 | 0,174 | 0,794 | 0,271 | 0,811 | 0,231 | 0,435 | 0,132 | 0,173 | 0,214 | 0,105 | 0,121 | 0,15 | 0,199 | 0,107 | 0,04 | ||
| dataset_pdtb_prompt_v2_13b | 13b | v2 | 0,097 | 0,945 | 0,112 | 0,912 | 0,037 | 0,099 | 0,081 | 0,094 | 0,126 | 0,101 | 0,113 | 0,107 | 0,077 | 0,083 | 0,093 | ||
| dataset_pdtb_prompt_v1_13bchat | 13bchat | v1 | 0,253 | 0,592 | 0,545 | 0,785 | 0,195 | 0,485 | 0,129 | 0,173 | 0,289 | 0,155 | 0,326 | 0,373 | 0,285 | 0,194 | 0,028 | ||
| dataset_pdtb_prompt_v2_vicuna-13b | vigogne-13b | v2 | 0,325 | 0,512 | 0,766 | 0,829 | 0,087 | 0,515 | 0,201 | 0,352 | 0,369 | 0,0 | 0,334 | 0,46 | 0,199 | 0,511 | 0,074 |
Par exemple, ce tableau montre le meilleur résultat pour les ensembles de données PDTB pour les modèles open source disponibles, qui reproduisent la figure radar de notre article :
Nous fournissons également des instructions pour évaluer les questions de discussion sur les caractéristiques linguistiques :
--feature comme conn et context dans question_generation.py (étape 1) et réexécutez toutes les expériences.question_generation_history.py . Ce script extraira les réponses des résultats d'assurance qualité stockés et générera de nouvelles questions.Pour la plupart des utilisateurs NLP, vous pourrez probablement exécuter notre code avec vos environnements virtuels (conda) existants.
Lorsque nous avons effectué nos expériences, les versions du package étaient les suivantes :
torch==2.0.1
transformers==4.30.0
sentencepiece
protobuf
scikit-learn
pandas
Cependant, nous avons observé que les modèles plus récents nécessitent des versions de package mises à niveau :
torch==2.4.0
transformers==4.43.3
sentencepiece
protobuf
scikit-learn
pandas
Si vous trouvez notre travail intéressant, n'hésitez pas à essayer notre ensemble de données/base de code.
Veuillez citer nos recherches si vous avez utilisé notre ensemble de données/base de code :
@inproceedings{acl24discursive,
title={Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations},
author={Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, and Min-Yen Kan},
booktitle={Proceedings of the Annual Meeting fof the Association of Computational Linguistics},
month={August},
year={2024},
organization={ACL},
address = "Bangkok, Thailand",
}
Si vous avez des questions ou des rapports de bugs, veuillez signaler un problème ou nous contacter directement par e-mail :
Adresse e-mail : ?@?
où ?️= yisong , ?= comp.nus.edu.sg
CC par 4.0


