Patron
1.0.0
Ce référentiel contient le code de notre article ACL 2023 Sélection de données à démarrage à froid pour un réglage fin du modèle de langage à quelques tirs : une approche de propagation de l'incertitude basée sur des invites.
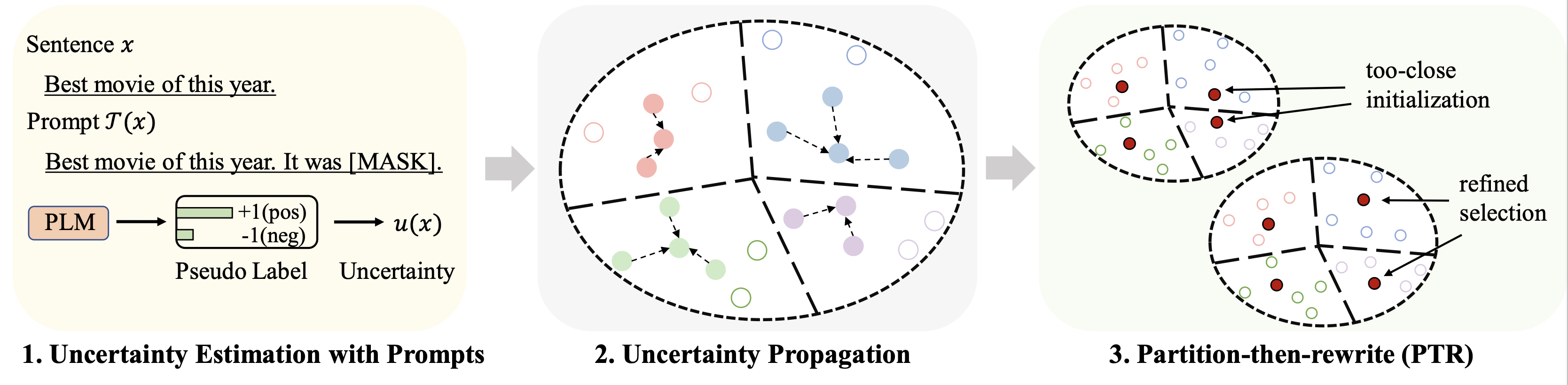
Les résultats sur différents ensembles de données (en utilisant 128 étiquettes comme budget) pour un réglage fin sont résumés comme suit :
| Méthode | BDIM | Yelp-plein | AGActualités | Yahoo! | DBPedia | TREC | Signifier |
|---|---|---|---|---|---|---|---|
| Supervision complète (base RoBERTa) | 94.1 | 66,4 | 94,0 | 77,6 | 99,3 | 97,2 | 88.1 |
| Échantillonnage aléatoire | 86,6 | 47,7 | 84,5 | 60,2 | 95,0 | 85,6 | 76,7 |
| Meilleure référence (Chang et al. 2021) | 88,5 | 46.4 | 85,6 | 61,3 | 96,5 | 87,7 | 77,6 |
| Patron (le nôtre) | 89,6 | 51.2 | 87,0 | 65.1 | 97,0 | 91.1 | 80,2 |
Pour un apprentissage basé sur des invites, nous utilisons le même pipeline que le LM-BFF. Le résultat avec 128 étiquettes est présenté comme suit.
| Méthode | BDIM | Yelp-plein | AGActualités | Yahoo! | DBPedia | TREC | Signifier |
|---|---|---|---|---|---|---|---|
| Supervision complète (base RoBERTa) | 94.1 | 66,4 | 94,0 | 77,6 | 99,3 | 97,2 | 88.1 |
| Échantillonnage aléatoire | 87,7 | 51.3 | 84,9 | 64,7 | 96,0 | 85,0 | 78.2 |
| Meilleure référence (Yuan et al., 2020) | 88,9 | 51,7 | 87,5 | 65,9 | 96,8 | 86,5 | 79,5 |
| Patron (le nôtre) | 89,3 | 55,6 | 87,8 | 67,6 | 97,4 | 88,9 | 81.1 |
python 3.8
transformers==4.2.0
pytorch==1.8.0
scikit-learn
faiss-cpu==1.6.4
sentencepiece==0.1.96
tqdm>=4.62.2
tensorboardX
nltk
openprompt
Nous utilisons les quatre ensembles de données suivants pour les principales expériences.
| Ensemble de données | Tâche | Nombre de cours | Nombre de données non étiquetées/données de test |
|---|---|---|---|
| BDIM | Sentiment | 2 | 25k/25k |
| Yelp-plein | Sentiment | 5 | 39 000/10 000 |
| Actualités AG | Sujet d'actualité | 4 | 119 000/7,6 000 |
| Yahoo! Réponses | Sujet d'assurance qualité | 5 | 180 000/30,1 000 |
| DBPedia | Sujet d'ontologie | 14 | 280 000/70 000 |
| TREC | Sujet des questions | 6 | 5k/0,5k |
Les données traitées peuvent être trouvées sur ce lien. Le dossier dans lequel placer ces ensembles de données sera décrit dans les parties suivantes.
Exécutez les commandes suivantes
python gen_embedding_simcse.py --dataset [the dataset you use] --gpuid [the id of gpu you use] --batchsize [the number of data processed in one time]
Nous fournissons la pseudo-prédiction obtenue via les invites dans le lien ci-dessus pour les ensembles de données. Veuillez vous référer aux documents originaux pour plus de détails.
Exécutez les commandes suivantes (exemple sur l'ensemble de données AG News)
python Patron _sample.py --dataset agnews --k 50 --rho 0.01 --gamma 0.5 --beta 0.5
Quelques hyperparamètres importants :
rho : le paramètre utilisé pour la propagation de l'incertitude dans l'Eq. 6 du papierbeta : la régularisation de la distance dans l'Eq. 8 du papiergamma : le poids du terme de régularisation dans l'Eq. 10 du papier Voir le dossier finetune pour des instructions détaillées.
Voir le dossier prompt_learning pour des instructions détaillées.
Consultez ce lien comme pipeline pour générer les prédictions basées sur des invites. Notez que vous devez personnaliser vos verbaliseurs et modèles d'invite.
Pour générer les intégrations de documents, vous pouvez suivre les commandes ci-dessus en utilisant SimCSE.
Une fois que vous avez généré l'index pour les données sélectionnées, vous pouvez utiliser les pipelines dans Running Fine-tuning Experiments et Running Prompt-based Learning Experiments pour les expériences de réglage fin et d'apprentissage basées sur des invites en quelques étapes.
Veuillez citer l'article suivant si vous trouvez ce dépôt utile pour votre recherche. Merci d'avance!
@article{yu2022 Patron ,
title={Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
},
author={Yue Yu and Rongzhi Zhang and Ran Xu and Jieyu Zhang and Jiaming Shen and Chao Zhang},
journal={arXiv preprint arXiv:2209.06995},
year={2022}
}
Nous tenons à remercier les auteurs du repo SimCSE et OpenPrompt pour le code bien organisé.


