JustJoking.ai
1.0.0
Dans ce projet, j'ai formé un modèle de transformateur pour générer de courtes blagues. Ensuite, avec une légère modification de la méthode d'inférence, j'ai pu utiliser le même modèle de telle sorte qu'étant donné une chaîne initiale en entrée, le modèle essaie de la compléter de manière humoristique.
Il y a deux ordinateurs portables qui effectuent tous deux la même tâche.
Résultat de la génération de blagues 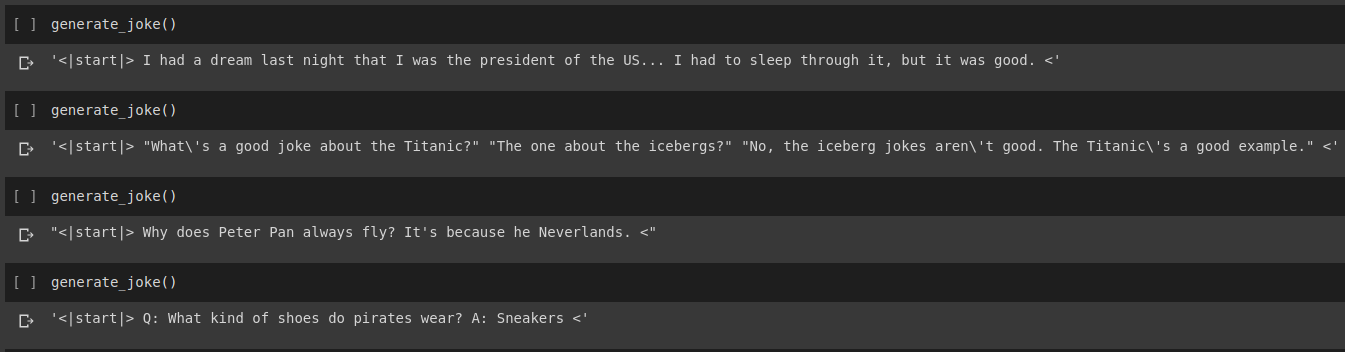
Résultat de l'achèvement de la peine 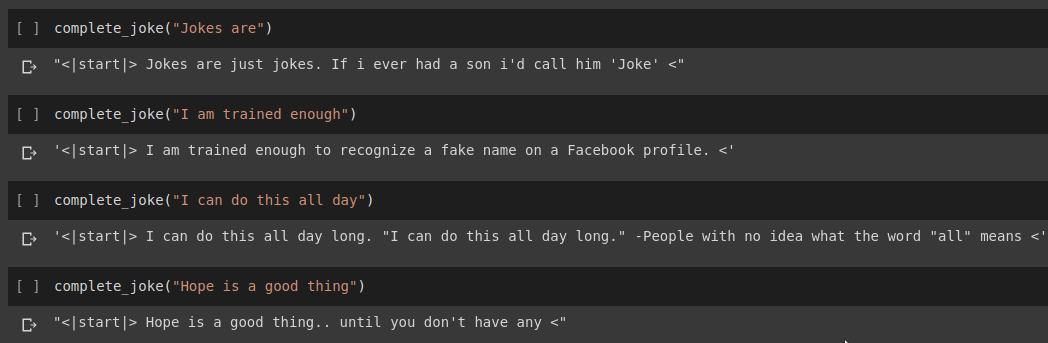
Résultats 
Pour notre tâche, nous utiliserons l'ensemble de données fourni sur Kaggle. Il s'agit d'un fichier CSV contenant plus de 200 000 blagues courtes supprimées de Reddit.
Remarque : Étant donné que l'ensemble de données est simplement supprimé de divers subreddits, un grand nombre de blagues contenues dans l'ensemble de données sont assez racistes et sexistes. Étant donné que toute IA considère ses données d’entraînement comme source unique de connaissances, il faut s’attendre à ce que notre modèle génère parfois des blagues similaires.
Une fois que nous avons tokenisé notre chaîne de blague, nous ajoutons un start_token et un end_token aux extrémités de la liste tokenisée. De plus, comme notre chaîne de plaisanterie peut être de longueur différente, nous appliquons également un remplissage dans toutes les chaînes à une max_length spécifiée afin que tous les tenseurs aient une forme similaire dans nos lots.
Le code pour cela peut être trouvé dans le notebook Joke Generation.ipynb . En cela, nous importerons le modèle GPT2Tokenizer et TFGPT2LMHead de la bibliothèque HuggingFace. Le code est écrit en Tensorflow2. Le cahier contient des commentaires expliquant le code aux endroits appropriés. En outre, HuggingFace Docs fournit une bonne documentation sur les paramètres d'entrée et la valeur de retour du modèle. Pour l'implémentation basée sur PyTorch, voir le dépôt Humour.ai de Tanul Singh
Le code pour cela peut être trouvé dans le notebook Joke_Completion_Pure_TF2_Implementation.ipynb . Pour aller plus loin dans le projet et mieux comprendre comment les choses fonctionnent, j'ai essayé de construire un transformateur sans bibliothèque externe. J'ai fait référence au didacticiel pour Transformers fourni par Tensorflow et j'ai mis certaines des explications mentionnées dans leur didacticiel dans mon cahier avec des explications supplémentaires afin qu'il soit facile de comprendre ce qui se passe.
J'ai d'abord construit un tokenizer pour notre ensemble de données et j'ai tokenisé les chaînes en l'utilisant. Ensuite, j'ai construit une couche pour Positional Encodings et MultiHeadAttention . De plus, j'ai utilisé une Lambda layer pour créer les masques adaptés à nos données.
Ensuite, j'ai créé une decoder layer unique pour notre décodeur. Ce qui suit est l'architecture d'une seule couche de décodeur.
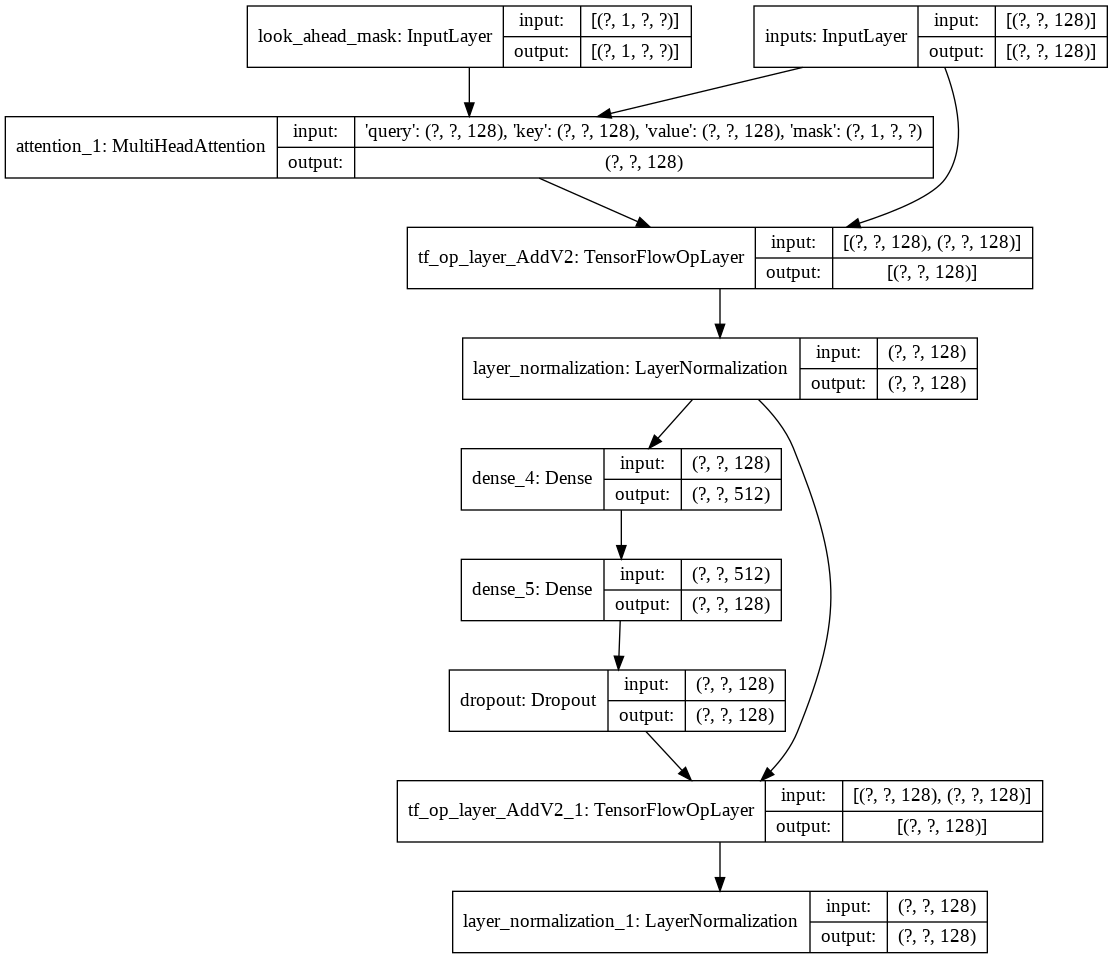
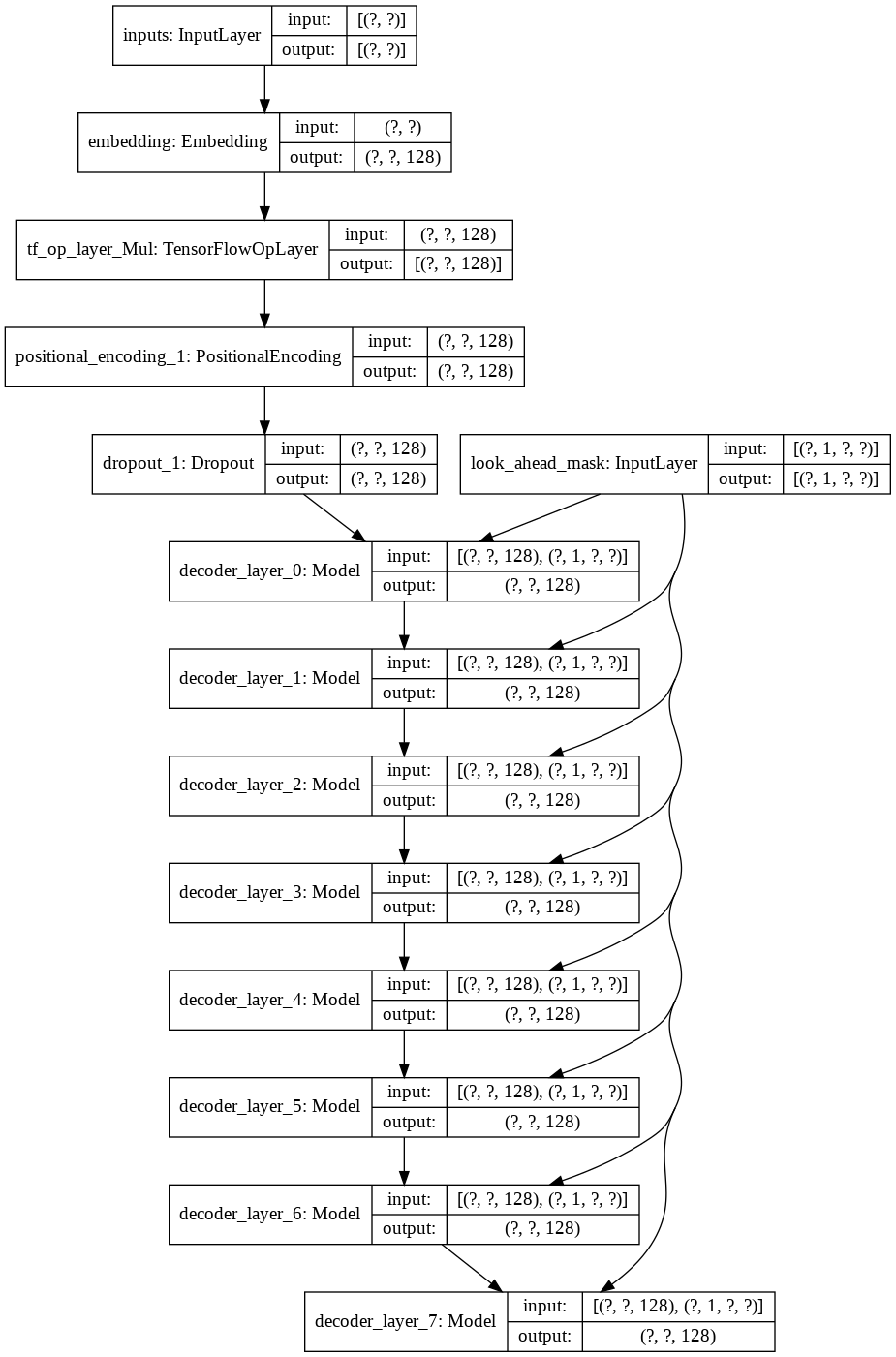
Pour le modèle transformer final, il prend les jetons d'entrée, les transmet à travers la couche lamda pour obtenir le masque et transmet à la fois le masque et les jetons à notre décodeur de langage dont la sortie est ensuite transmise à travers une couche dense. Voici l’architecture de notre modèle final.