CTCWordBeamSearch
1.0.0
Décodeur de classification temporelle connexionniste (CTC) avec dictionnaire et modèle de langage (LM).
pip install .tests/ et exécutez pytest pour vérifier si l'installation a fonctionné L'exemple de jouet suivant montre comment utiliser la recherche par faisceau de mots. Le modèle hypothétique (par exemple un modèle de reconnaissance de texte) est capable de reconnaître 3 caractères différents : "a", "b" et " " (espace). Les mots de cet exemple de jouet peuvent contenir les caractères « a » et « b » (mais pas « » qui est le séparateur de mots). Le modèle de langage est formé à partir d'un corpus de texte qui ne contient que deux mots : « a » et « ba ».
Dans cet extrait de code, une instance de recherche par faisceau de mots est créée et un tableau numpy en forme de TxBx(C+1) est décodé :
import numpy as np
from word_beam_search import WordBeamSearch
corpus = 'a ba' # two words "a" and "ba", separated by whitespace
chars = 'ab ' # the characters that can be recognized (in this order)
word_chars = 'ab' # characters that form words
# RNN output
# 3 time-steps and 4 characters per time time ("a", "b", " ", CTC-blank)
mat = np . array ([[[ 0.9 , 0.1 , 0.0 , 0.0 ]],
[[ 0.0 , 0.0 , 0.0 , 1.0 ]],
[[ 0.6 , 0.4 , 0.0 , 0.0 ]]])
# initialize word beam search (only do this once in your code)
wbs = WordBeamSearch ( 25 , 'Words' , 0.0 , corpus . encode ( 'utf8' ), chars . encode ( 'utf8' ), word_chars . encode ( 'utf8' ))
# compute label string
label_str = wbs . compute ( mat )Le décodeur renvoie une liste avec une chaîne d'étiquette décodée pour chaque élément du lot. Pour enfin obtenir les chaînes de caractères, mappez chaque étiquette au caractère correspondant :
char_str = [] # decoded texts for batch
for curr_label_str in label_str :
s = '' . join ([ chars [ label ] for label in curr_label_str ])
char_str . append ( s )Exemples :
tests/test_word_beam_search.py Paramètres du constructeur de la classe WordBeamSearch :
0<len(wordChars)<len(chars) . Dans le cas où seuls des mots uniques doivent être détectés, il n'est pas nécessaire d'utiliser un caractère de séparation, donc les deux paramètres peuvent également être égaux : 0<len(wordChars)<=len(chars) Entrée dans la méthode WordBeamSearch.compute :
La recherche par faisceau de mots est un algorithme de décodage CTC. Il est utilisé pour des tâches de reconnaissance de séquences telles que la reconnaissance de texte manuscrit ou la reconnaissance vocale automatique.
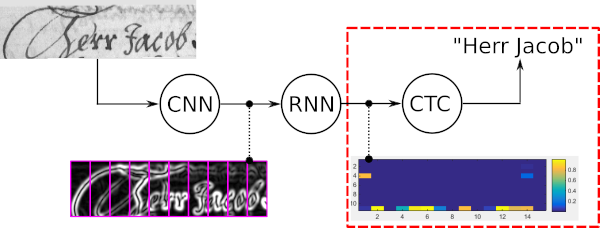
Les quatre propriétés principales de la recherche par faisceau de mots sont :
L'exemple suivant montre un cas d'utilisation typique de la recherche par faisceau de mots ainsi que les résultats donnés par cinq décodeurs différents. Le décodage du meilleur chemin et la recherche de faisceau vanille se trompent car ces décodeurs n'utilisent que la sortie bruyante du modèle optique. L'extension de la recherche par faisceau Vanilla par un LM au niveau du caractère améliore le résultat en autorisant uniquement les séquences de caractères probables. Le passage de jetons utilise un dictionnaire et un LM au niveau des mots et obtient donc tous les mots correctement. Cependant, il n’est pas capable de reconnaître les chaînes de caractères arbitraires comme les nombres. La recherche par faisceau de mots est capable de reconnaître les mots à l'aide d'un dictionnaire, mais elle est également capable d'identifier correctement les caractères autres que les mots.

Plus d'informations :
extras/prototype/extras/tf/ Veuillez citer l'article suivant si vous utilisez la recherche par faisceau de mots dans votre travail de recherche.
@inproceedings{scheidl2018wordbeamsearch,
title = {Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm},
author = {Scheidl, H. and Fiel, S. and Sablatnig, R.},
booktitle = {16th International Conference on Frontiers in Handwriting Recognition},
pages = {253--258},
year = {2018},
organization = {IEEE}
}


