Grounding_LLMs_with_online_RL
1.0.0
Ce référentiel contient le code utilisé pour notre article Grounding Large Language Models with Online Reinforcement Learning.
Vous pouvez trouver plus d’informations sur notre site Web.
Nous effectuons la mise à la terre fonctionnelle des connaissances des LLM dans BabyAI-Text en utilisant la méthode GLAM : 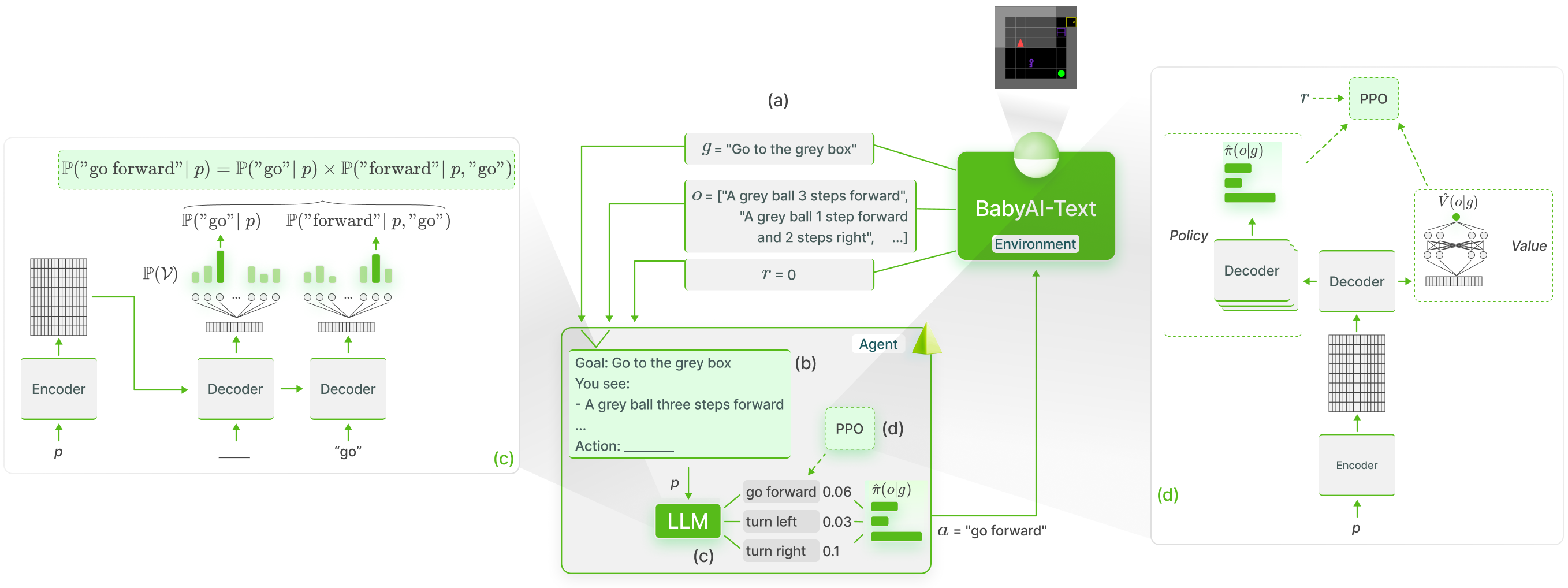
Nous publions notre environnement BabyAI-Text ainsi que le code pour réaliser nos expériences (à la fois former les agents et évaluer leurs performances). Nous nous appuyons sur la bibliothèque Lamorel pour utiliser les LLM.
Notre référentiel est structuré comme suit :
? Grounding_LLMs_with_online_RL
┣ babyai-text -- notre environnement BabyAI-Text
┣ experiments -- code pour nos expériences
┃ ┣ agents -- mise en place de tous nos agents
┃ ┃ ┣ bot -- agent bot exploitant le bot de BabyAI
┃ ┃ ┣ random_agent -- agent jouant uniformément au hasard
┃ ┃ ┣ drrn -- Agent DRRN d'ici
┃ ┃ ┣ ppo -- agents utilisant PPO
┃ ┃ ┃ ┣ symbolic_ppo_agent.py -- SymbolicPPO adapté du PPO de BabyAI
┃ ┃ ┃ ┗ llm_ppo_agent.py -- notre agent LLM fondé sur PPO
┃ ┣ configs -- configs Lamorel pour nos expériences
┃ ┣ slurm -- scripts utils pour lancer nos expérimentations sur un cluster SLURM
┃ ┣ campaign -- Scripts SLURM utilisés pour lancer nos expérimentations
┃ ┣ train_language_agent.py -- former des agents à l'aide de BabyAI-Text (LLM et DRRN) -> contient notre implémentation de la perte de PPO pour les LLM ainsi que des têtes supplémentaires au-dessus des LLM
┃ ┣ train_symbolic_ppo.py -- entraîne SymbolicPPO sur BabyAI (avec les tâches de BabyAI-Text)
┃ ┣ post-training_tests.py -- tests de généralisation des agents formés
┃ ┣ test_results.py -- utilitaires pour formater les résultats
┃ ┗ clm_behavioral-cloning.py -- code pour effectuer un clonage comportemental sur un LLM en utilisant des trajectoires
conda create -n dlp python=3.10.8; conda activate dlp
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
Installer BabyAI-Text : Voir les détails d'installation dans le package babyai-text
Installer Lamorel
git clone https://github.com/flowersteam/lamorel.git; cd lamorel/lamorel; pip install -e .; cd ../..
Veuillez utiliser Lamorel avec nos configurations. Vous pouvez trouver des exemples de nos scripts de formation dans la campagne.
Pour entraîner un modèle de langage sur un environnement BabyAI-Text, il faut utiliser le fichier train_language_agent.py . Ce script (lancé avec Lamorel) utilise les entrées de configuration suivantes :
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
num_steps : 1000 # Total number of training steps
max_episode_steps : 3 # Maximum number of steps in a single episode
frames_per_proc : 40 # The number of collected transitions to perform a PPO update will be frames_per_proc*number_envs
discount : 0.99 # Discount factor used in PPO
lr : 1e-6 # Learning rate used to finetune the LLM
beta1 : 0.9 # PPO's hyperparameter
beta2 : 0.999 # PPO's hyperparameter
gae_lambda : 0.99 # PPO's hyperparameter
entropy_coef : 0.01 # PPO's hyperparameter
value_loss_coef : 0.5 # PPO's hyperparameter
max_grad_norm : 0.5 # Maximum grad norm when updating the LLM's parameters
adam_eps : 1e-5 # Adam's hyperparameter
clip_eps : 0.2 # Epsilon used in PPO's losses clipping
epochs : 4 # Number of PPO epochs performed on each set of collected trajectories
batch_size : 16 # Minibatch size
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
template_test : 1 # Which prompt template to use to log evolution of action's probability (Section C of our paper). Choices or [1, 2].
nbr_obs : 3 # Number of past observation used in the promptPour les entrées de configuration liées au modèle de langage lui-même, veuillez consulter Lamorel.
Pour évaluer les performances d'un agent (par exemple un LLM formé, le bot de BabyAI...) sur des tâches de test, utilisez post-training_tests.py et définissez les entrées de configuration suivantes :
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
max_episode_steps : 3 # Maximum number of steps in a single episode
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
nbr_obs : 3 # Number of past observation used in the prompt
number_episodes : 10 # Number of test episodes
language : ' english ' # Useful to perform the French experiment (Section H4)
zero_shot : true # Whether the zero-shot LLM (i.e. without finetuning should be used)
modified_action_space : false # Whether a modified action space (e.g. different from the one seen during training) should be used
new_action_space : # ["rotate_left","rotate_right","move_ahead","take","release","switch"] # Modified action space
im_learning : false # Whether a LLM produced with Behavioral Cloning should be used
im_path : " " # Path to the LLM learned with Behavioral Cloning
bot : false # Whether the BabyAI's bot agent should be used

