DialogStudio
1.0.0

Papier, Huggingface, Modèle, Twitter
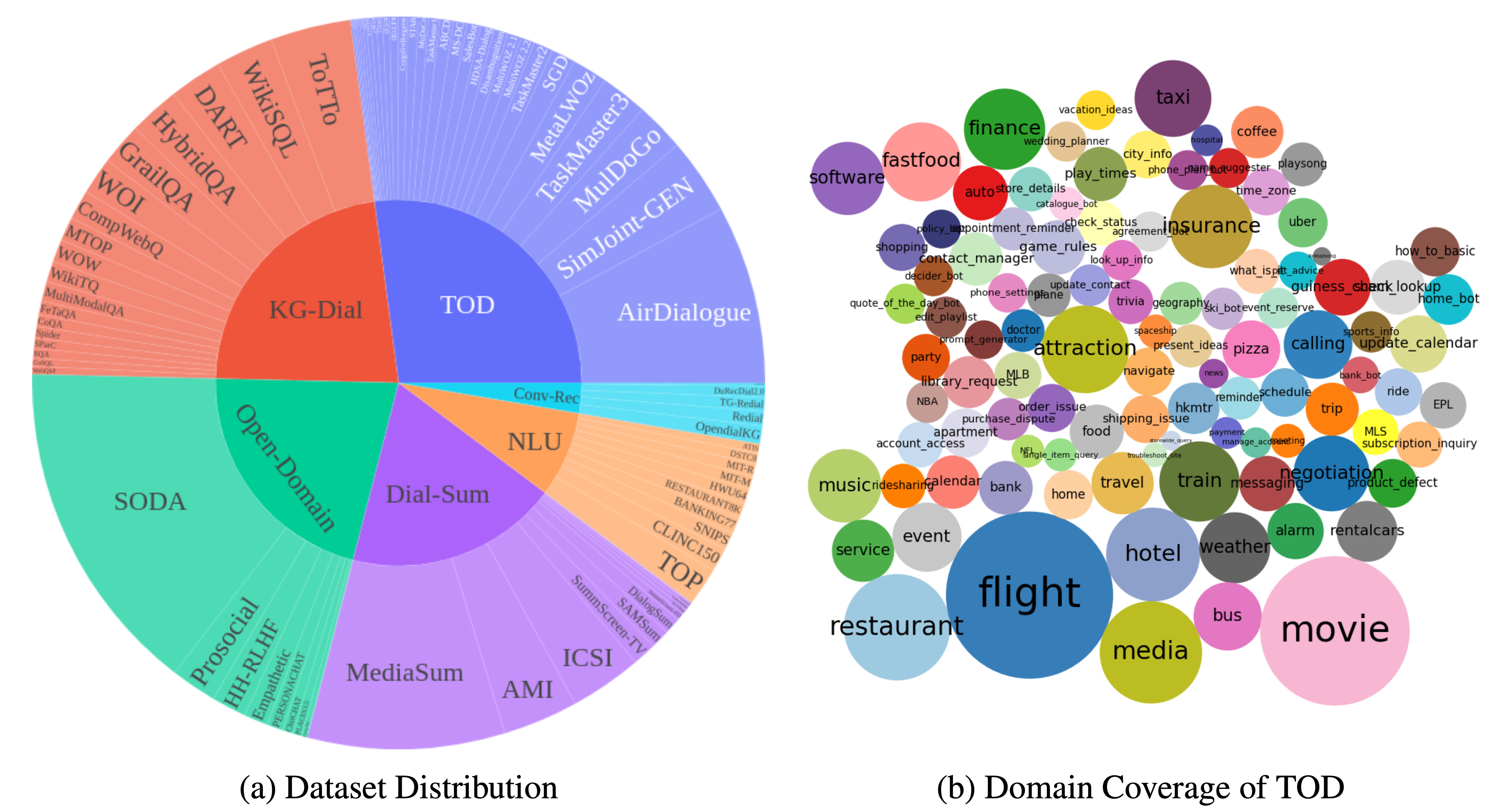
DialogStudio est une vaste collection et des ensembles de données de dialogue unifiés. La figure ci-dessous fournit un résumé des statistiques générales associées à DialogStudio . DialogStudio a unifié chaque ensemble de données tout en préservant ses informations d'origine, ce qui contribue à soutenir la recherche sur des ensembles de données individuels et la formation au Large Language Model (LLM). La liste complète de tous les ensembles de données disponibles est ici.
Les données sont téléchargeables via Huggingface comme introduit dans Chargement des données. Nous fournissons également des exemples pour chaque ensemble de données dans ce dépôt. Pour des détails plus granulaires et spécifiques à une catégorie, veuillez vous référer aux dossiers individuels correspondant à chaque catégorie au sein de la collection DialogStudio , par exemple l'ensemble de données MULTIWOZ2_2 sous la catégorie dialogues orientés tâches.
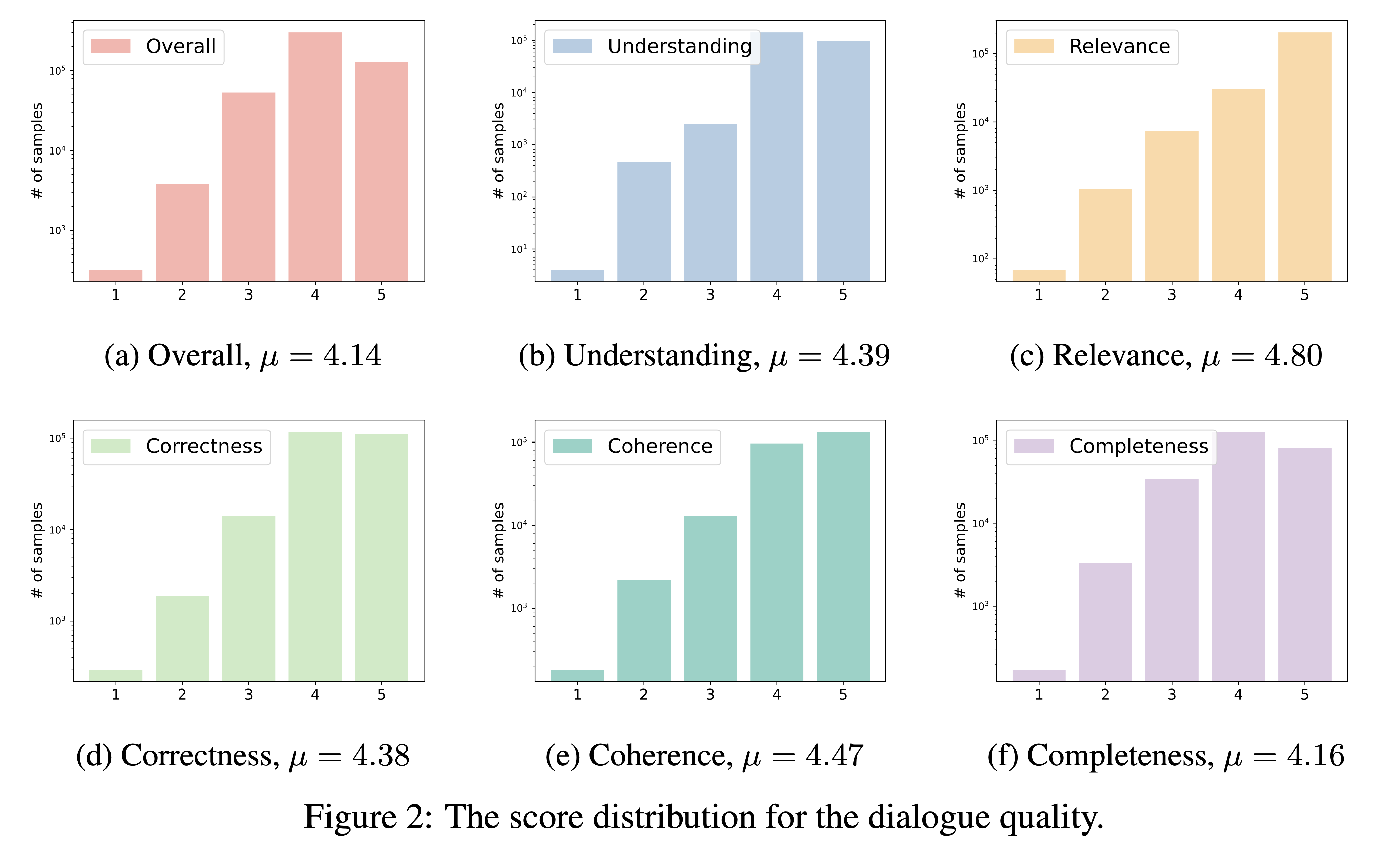
DialogStudio évalue la qualité du dialogue sur la base de six critères critiques, à savoir la compréhension, la pertinence, l'exactitude, la cohérence, l'exhaustivité et la qualité globale. Chaque critère est noté sur une échelle de 1 à 5, les notes les plus élevées étant réservées aux dialogues exceptionnels.
Compte tenu du grand nombre d'ensembles de données incorporés dans DialogStudio , nous avons utilisé « gpt-3.5-turbo » pour évaluer 33 ensembles de données distincts. Le script correspondant utilisé pour cette évaluation est accessible via le lien.
Les résultats de notre évaluation de la qualité du dialogue sont présentés ci-dessous. Nous avons l'intention de publier les résultats d'évaluation des dialogues sélectionnés individuellement dans la période à venir.
Vous pouvez charger n'importe quel ensemble de données dans DialogStudio à partir du hub HuggingFace en réclamant le {dataset_name} , qui est exactement le nom du dossier de l'ensemble de données. Tous les ensembles de données disponibles sont décrits dans le contenu de l'ensemble de données.
Vous trouverez ci-dessous un exemple de chargement de l'ensemble de données MULTIWOZ2_2 dans la catégorie des dialogues orientés tâches :
Charger l'ensemble de données
from datasets import load_dataset
dataset = load_dataset ( 'Salesforce/ DialogStudio ' , 'MULTIWOZ2_2' )Voici la structure de sortie de MultiWOZ 2.2
DatasetDict ({
train : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 8437
})
validation : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
test : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
})Les ensembles de données sont divisés en plusieurs catégories dans ce référentiel GitHub et ce hub HuggingFace. Vous pouvez consulter le tableau de l'ensemble de données pour plus d'informations. Et vous pouvez cliquer sur chaque dossier pour vérifier quelques exemples :
Nous avons déployé la version 1.0 des modèles ( DialogStudio -t5-base-v1.0, DialogStudio -t5-large-v1.0, DialogStudio -t5-3b-v1.0) formés sur quelques ensembles de données DialogStudio sélectionnés. Vérifiez chaque carte modèle pour plus de détails.
Vous trouverez ci-dessous un exemple d'exécution d'un modèle sur CPU :
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
input_text = "Answer the following yes/no question by reasoning step-by-step. Can you write 200 words in a single tweet?"
input_ids = tokenizer ( input_text , return_tensors = "pt" ). input_ids
outputs = model . generate ( input_ids , max_new_tokens = 256 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Notre projet suit la structure suivante en ce qui concerne les licences :
Pour des informations détaillées sur les licences, veuillez vous référer aux licences spécifiques accompagnant les ensembles de données d'origine. Il est important de vous familiariser avec ces conditions car nous n'assumons aucune responsabilité pour les problèmes de licence.
Nous remercions sincèrement tous les auteurs d’ensembles de données qui ont contribué au domaine de l’IA conversationnelle. Malgré des efforts minutieux, des inexactitudes dans nos citations ou références peuvent survenir. Si vous repérez des erreurs ou des omissions, veuillez soulever un problème ou soumettre une pull request pour nous aider à nous améliorer. Merci!
Les données et le code de ce référentiel sont principalement développés pour ou dérivés de l'article ci-dessous. Si vous utilisez des ensembles de données de DialogStudio , nous vous demandons de bien vouloir citer à la fois le travail original et notre propre travail (accepté par les résultats de l'EACL 2024 en tant que document long).
@article{zhang2023 DialogStudio ,
title={ DialogStudio : Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI},
author={Zhang, Jianguo and Qian, Kun and Liu, Zhiwei and Heinecke, Shelby and Meng, Rui and Liu, Ye and Yu, Zhou and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2307.10172},
year={2023}
}
Nous invitons avec enthousiasme les contributions de la communauté ! Rejoignez-nous dans notre mission commune pour faire avancer le domaine de l’IA conversationnelle !


