aug pe
1.0.0
? Document • Données (Yelp/OpenReview/PubMed) • Page du projet
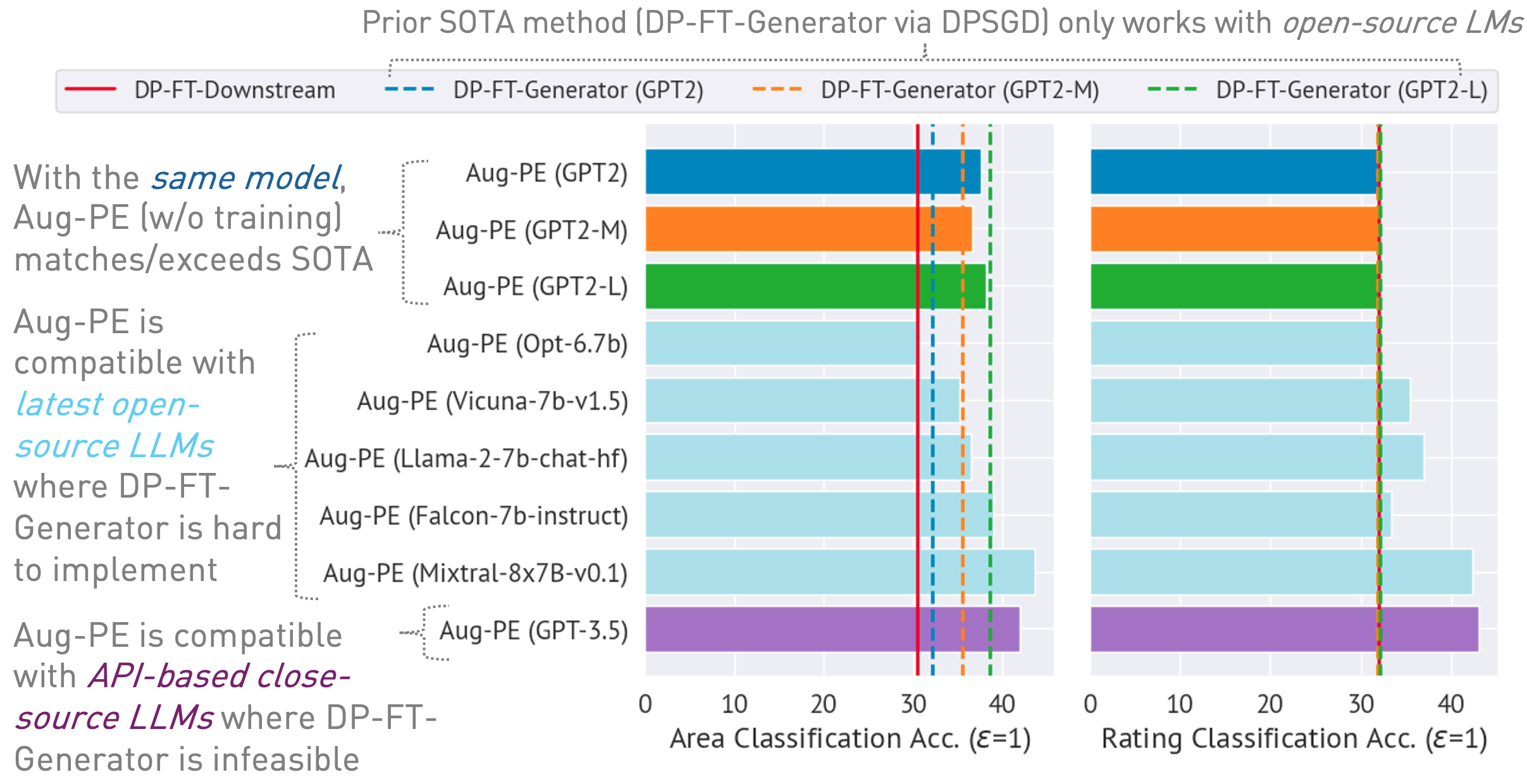
Ce référentiel implémente l'algorithme Augmented Private Evolution (Aug-PE), exploitant l'accès API d'inférence aux grands modèles de langage (LLM) pour générer du texte synthétique différentiellement privé (DP) sans avoir besoin de formation de modèle. Nous comparons le réglage fin DP-SGD et Aug-PE :

Sous
03/13/2024 : La page du projet est disponible, qui présente l'algorithme et ses résultats.03/11/2024 : Code et papier ArXiv sont disponibles. conda env create -f environment.yml
conda activate augpe
Les ensembles de données sont situés dans data/{dataset} où dataset est yelp , openreview et pubmed .
Téléchargez Yelp train.csv (1.21G) et PubMed train.csv (117 Mo) à partir de ce lien ou exécutez :
bash scripts/download_data.sh # download yelp train.csv and pubmed train.csvDescription de l'ensemble de données :
Intégrations de pré-calcul pour les données privées (ligne 1 de l'algorithme Aug-PE) :
bash scripts/embeddings.sh --openreview # Compute private embeddings
bash scripts/embeddings.sh --pubmed
bash scripts/embeddings.sh --yelp Remarque : Le calcul des intégrations pour OpenReview et PubMed est relativement rapide. Cependant, en raison de la grande taille de l'ensemble de données de Yelp (1,9 million d'échantillons d'entraînement), le processus peut prendre environ 40 minutes.
Calculez le niveau de bruit DP pour votre ensemble de données dans notebook/dp_budget.ipynb en fonction du budget de confidentialité
Pour la visualisation avec Wandb, configurez --wandb_key et --project avec votre clé et le nom de votre projet dans dpsda/arg_utils.py .
Utilisez les LLM open source de Hugging Face pour générer des données synthétiques :
export CUDA_VISIBLE_DEVICES=0
bash scripts/hf/{dataset}/generate.sh # Replace `{dataset}` with yelp, openreview, or pubmedQuelques hyperparamètres clés :
noise : bruit DP.epoch : nous utilisons 10 époques pour le réglage DP. Pour le paramètre non-DP, nous utilisons 20 époques pour Yelp et 10 époques pour les autres ensembles de données.model_type : modèle sur huggingface, tel que ["gpt2", "gpt2-medium", "gpt2-large", "meta-llama/Llama-2-7b-chat-hf", "tiiuae/falcon-7b-instruct" , "facebook/opt-6.7b", "lmsys/vicuna-7b-v1.5", "mistralai/Mixtral-8x7B-Instruct-v0.1"].num_seed_samples : nombre d'échantillons synthétiques.lookahead_degree : nombre de variations pour l'estimation de l'intégration de l'échantillon synthétique (ligne 5 dans l'algorithme Aug-PE). La valeur par défaut est 0 (auto-intégration).L : lié au nombre de variations pour générer des échantillons synthétiques candidats (ligne 18 de l'algorithme Aug-PE)feat_ext : modèle d'intégration sur les transformateurs de phrases huggingface.select_syn_mode : sélectionnez des échantillons synthétiques en fonction des votes de l'histogramme ou de la probabilité. La valeur par défaut est rank (ligne 19 dans l'algorithme Aug-PE)temperature : température pour la génération LLM.Affinez le modèle en aval avec le texte synthétique DP et évaluez la précision du modèle sur des données de test réelles :
bash scripts/hf/{dataset}/downstream.sh # Finetune downstream model and evaluate performance Mesurez la distance de distribution d'intégration :
bash scripts/hf/{dataset}/metric.sh # Calculate distribution distancePour un processus rationalisé combinant toutes les étapes de génération et d’évaluation :
bash scripts/hf/template/{dataset}.sh # Complete workflow for each dataset Nous utilisons un modèle fermé via l'API Azure OpenAI. Veuillez définir votre clé et votre point de terminaison dans apis/azure_api.py
MODEL_CONFIG = {
'gpt-3.5-turbo' :{ "openai_api_key" : "YOUR_AZURE_OPENAI_API_KEY" ,
"openai_api_base" : "YOUR_AZURE_OPENAI_ENDPOINT" ,
"engine" : 'YOUR_DEPLOYMENT_NAME' ,
},
} Ici, engine pourrait être gpt-35-turbo dans Azure.
Exécutez le script suivant pour générer des données synthétiques, évaluez-les sur la tâche en aval et calculez la distance de distribution d'intégration entre les données réelles et synthétiques :
bash scripts/gpt-3.5-turbo/{dataset}.shNous utilisons des invites liées à la longueur du texte pour GPT-3.5 pour contrôler la longueur du texte généré. Nous introduisons ici plusieurs hyperparamètres supplémentaires :
dynamic_len est utilisé pour activer le mécanisme de longueur dynamique.word_var_scale : variance du bruit gaussien utilisée pour déterminer target_word.max_token_word_scale : nombre maximum de jetons par mot. Nous définissons le max_token pour la génération LLM en fonction du target_word (spécifié dans l'invite) et du max_token_word_scale. Utilisez le notebook pour calculer la différence de distribution de longueur de texte entre les données réelles et synthétiques : notebook/text_lens_distribution.ipynb
Si vous trouvez notre travail utile, pensez à le citer comme suit :
@inproceedings {
xie2024differentially,
title = { Differentially Private Synthetic Data via Foundation Model {API}s 2: Text } ,
author = { Chulin Xie and Zinan Lin and Arturs Backurs and Sivakanth Gopi and Da Yu and Huseyin A Inan and Harsha Nori and Haotian Jiang and Huishuai Zhang and Yin Tat Lee and Bo Li and Sergey Yekhanin } ,
booktitle = { Forty-first International Conference on Machine Learning } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=LWD7upg1ob }
}Si vous avez des questions concernant le code ou le document, n'hésitez pas à envoyer un e-mail à Chulin ([email protected]) ou à ouvrir un numéro.


