node chatgpt api
v1.37.0 - Bing Image Creator support, ChatGPTClient optimizations, and more
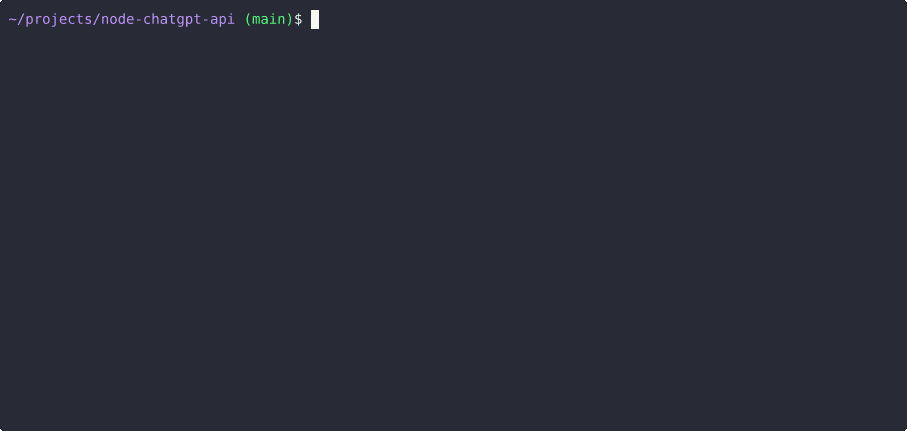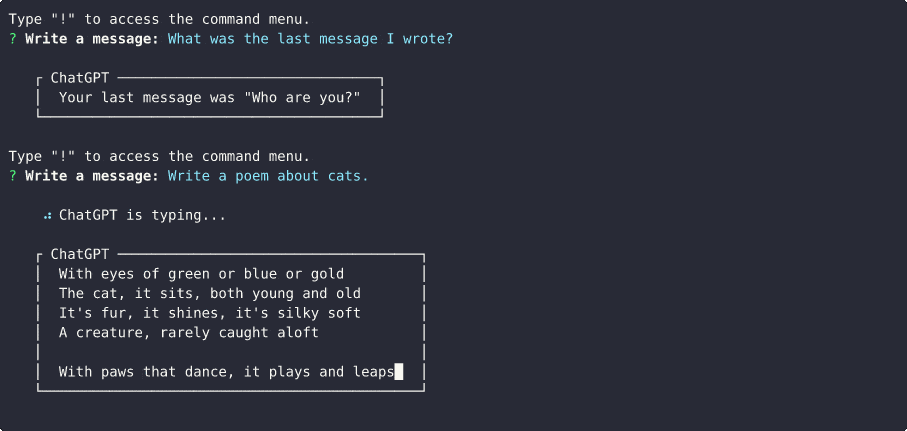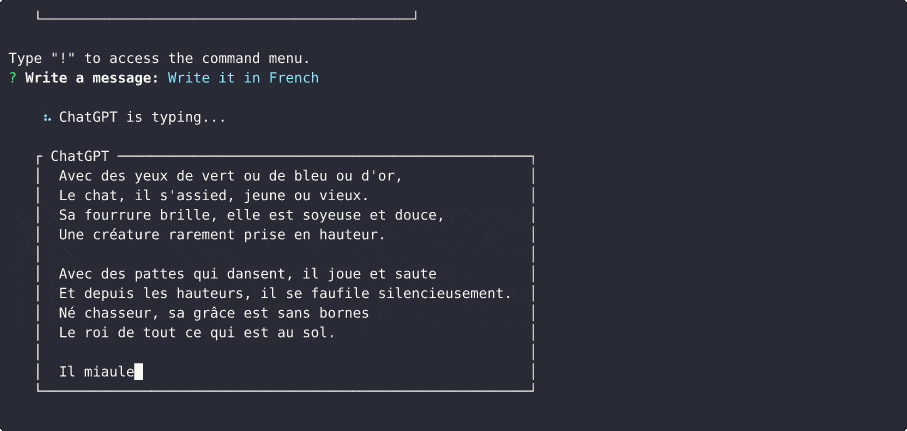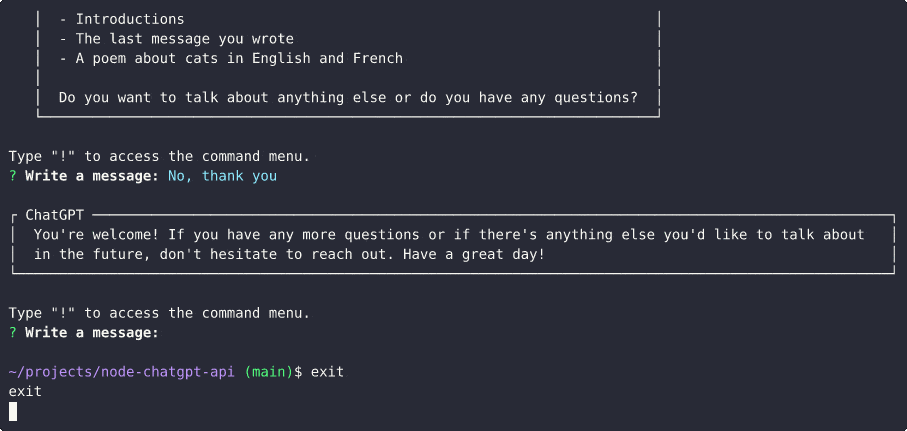
La prise en charge du modèle officiel ChatGPT a été ajoutée ! Vous pouvez désormais utiliser le modèle gpt-3.5-turbo avec l'API officielle OpenAI, en utilisant ChatGPTClient . Il s'agit du même modèle que ChatGPT utilise, et c'est le modèle le plus puissant disponible actuellement. L'utilisation de ce modèle n'est pas gratuite , mais il est 10 fois moins cher (au prix de 0,002 $ pour 1 000 jetons) que text-davinci-003 .
Voir l'article d'OpenAI, Présentation des API ChatGPT et Whisper pour plus d'informations.
Pour l'utiliser, définissez Le modèle par défaut utilisé dans modelOptions.model sur gpt-3.5-turbo et ChatGPTClient se chargera du reste.ChatGPTClient est désormais gpt-3.5-turbo . Vous pouvez toujours définir userLabel , chatGptLabel et promptPrefix (instructions système) comme d'habitude.
Il peut y avoir plus de chances que votre compte soit banni si vous continuez à automatiser chat.openai.com. Continuez à le faire à vos propres risques.
J'ai ajouté un ChatGPTBrowserClient expérimental qui dépend d'un serveur proxy inverse qui utilise un contournement Cloudflare, vous permettant de parler à ChatGPT (chat.openai.com) sans nécessiter l'automatisation du navigateur. Tout ce dont vous avez besoin est votre jeton d'accès de https://chat.openai.com/api/auth/session.
Comme toujours, veuillez noter que si vous choisissez de suivre cette voie, vous exposez votre jeton d'accès à un serveur tiers à source fermée. Si cela vous inquiète, vous pouvez choisir soit d'utiliser un compte ChatGPT gratuit pour minimiser les risques, soit de continuer à utiliser ChatGPTClient avec le modèle text-davinci-003 .
La méthode que nous utilisions pour accéder aux modèles sous-jacents de ChatGPT a malheureusement été corrigée. Vos options actuelles sont soit d'utiliser l'API officielle OpenAI avec le modèle text-davinci-003 (qui coûte de l'argent), soit d'utiliser une solution basée sur un navigateur pour s'interfacer avec le backend de ChatGPT (qui est moins puissant, plus limité en débit et est non pris en charge par cette bibliothèque pour le moment).
Avec l'aide de @PawanOsman, nous avons trouvé un moyen de continuer à utiliser les modèles sous-jacents ChatGPT . Pour éviter, espérons-le, de perdre à nouveau l'accès, nous avons décidé de fournir des serveurs proxy inverses compatibles avec l'API OpenAI. J'ai mis à jour ChatGPTClient pour prendre en charge l'utilisation d'un serveur proxy inverse au lieu du serveur API OpenAI. Voir Utilisation d'un proxy inverse pour plus d'informations sur les serveurs proxy disponibles et leur fonctionnement.
Veuillez noter que si vous choisissez d'emprunter cette voie, vous exposez votre jeton d'accès à un serveur tiers à source fermée. Si cela vous inquiète, vous pouvez choisir soit d'utiliser un compte ChatGPT gratuit pour minimiser les risques, soit de continuer à utiliser l'API officielle OpenAI avec le modèle text-davinci-003 .
J'ai trouvé un nouveau modèle de travail pour text-chat-davinci-002 , text-chat-davinci-002-sh-alpha-aoruigiofdj83 . Il s'agit du modèle sous-jacent utilisé par la version "Turbo" de ChatGPT Plus. Les réponses sont extrêmement rapides. J'ai mis à jour la bibliothèque pour utiliser ce modèle.
Mauvais timing ; text-chat-davinci-002-sh-alpha-aoruigiofdj83 a été supprimé peu de temps après, peut-être à cause d'un nouveau modèle quelque part ?
Découvrez la puissance de la version GPT-4 de ChatGPT de Bing avec BingAIClient (expérimental). Le serveur API et la CLI doivent encore être mis à jour pour prendre en charge cela , mais vous pouvez utiliser le client directement dès maintenant. Veuillez noter que si votre compte est toujours sur liste d'attente, vous ne pourrez pas utiliser ce client.
Même si text-chat-davinci-002-20221122 est de nouveau disponible, il semble qu'il soit constamment surchargé et renvoie une erreur 429. Il est probable qu'OpenAI n'ait consacré qu'une petite quantité de ressources à ce modèle pour éviter qu'il ne soit largement utilisé par le public. De plus, j'ai entendu dire que les versions plus récentes sont désormais verrouillées pour les employés et partenaires d'OpenAI. Il est donc peu probable que nous puissions trouver des solutions de contournement avant la sortie officielle du modèle.
Vous pouvez plutôt utiliser le modèle text-davinci-003 en remplacement immédiat. Gardez à l'esprit que text-davinci-003 n'est pas aussi bon que text-chat-davinci-002 (qui est formé via RHLF et affiné pour être une IA conversationnelle), bien que les résultats soient toujours assez bons dans la plupart des cas. Veuillez noter que l'utilisation text-davinci-003 vous coûtera des crédits ($).
Je vais réajouter la prise en charge de ChatGPT basé sur un navigateur pour le serveur API et la CLI. Veuillez suivre et surveiller ce référentiel pour les mises à jour.
Les montagnes russes ont atteint le prochain arrêt. text-chat-davinci-002-20221122 est de nouveau disponible.
Essayer d'utiliser text-chat-davinci-002-20221122 avec l'API OpenAI renvoie désormais une erreur 404. Vous pouvez plutôt utiliser le modèle text-davinci-003 en remplacement immédiat. Gardez à l'esprit que text-davinci-003 n'est pas aussi bon que text-chat-davinci-002 (qui est formé via RHLF et affiné pour être une IA conversationnelle), bien que les résultats soient toujours très bons. Veuillez noter que l'utilisation text-davinci-003 vous coûtera des crédits ($).
Veuillez patienter pour d'autres mises à jour pendant que nous étudions d'autres solutions de contournement.
Essayer d'utiliser text-chat-davinci-002-20230126 avec l'API OpenAI renvoie désormais une erreur 404. Quelqu'un a déjà trouvé le nouveau nom du modèle, mais il n'est pas disposé à le partager pour le moment. Je mettrai à jour ce référentiel une fois que j'aurai trouvé le nouveau modèle. Si vous avez des pistes, veuillez ouvrir un problème ou une pull request.
En attendant, j'ai ajouté la prise en charge de modèles comme text-davinci-003 , que vous pouvez utiliser en remplacement immédiat. Gardez à l'esprit que text-davinci-003 n'est pas aussi bon que text-chat-davinci-002 (qui est formé via RHLF et affiné pour être une IA conversationnelle), bien que les résultats soient toujours très bons. Veuillez noter que l'utilisation text-davinci-003 vous coûtera des crédits ($).
L'utilisateur Discord @pig#8932 a trouvé un modèle text-chat-davinci-002 fonctionnel, text-chat-davinci-002-20221122 . J'ai mis à jour la bibliothèque pour utiliser ce modèle.
Une implémentation client pour ChatGPT et Bing AI. Disponible en tant que module Node.js, serveur API REST et application CLI.
ChatGPTClient : prise en charge du modèle sous-jacent officiel ChatGPT, gpt-3.5-turbo , via l'API d'OpenAI.keyv-file est également inclus dans ce package et peut être utilisé pour stocker des conversations dans un fichier JSON si vous utilisez le serveur API ou la CLI (voir settings.example.js ).text-davinci-003BingAIClient : prise en charge de la version Bing de ChatGPT, propulsée par GPT-4.ChatGPTBrowserClient : support du site officiel ChatGPT, utilisant un serveur proxy inverse pour un contournement Cloudflare.npm i @waylaidwanderer/chatgpt-api Voir demos/use-bing-client.js .
Voir demos/use-client.js .
Voir demos/use-browser-client.js .
Vous pouvez installer le package en utilisant
npm i -g @waylaidwanderer/chatgpt-api puis exécutez-le en utilisant chatgpt-api . Cela prend un paramètre facultatif --settings=<path_to_settings.js> , ou recherche settings.js dans le répertoire actuel s'il n'est pas défini, avec le contenu suivant :
module . exports = {
// Options for the Keyv cache, see https://www.npmjs.com/package/keyv.
// This is used for storing conversations, and supports additional drivers (conversations are stored in memory by default).
// Only necessary when using `ChatGPTClient`, or `BingAIClient` in jailbreak mode.
cacheOptions : { } ,
// If set, `ChatGPTClient` and `BingAIClient` will use `keyv-file` to store conversations to this JSON file instead of in memory.
// However, `cacheOptions.store` will override this if set
storageFilePath : process . env . STORAGE_FILE_PATH || './cache.json' ,
chatGptClient : {
// Your OpenAI API key (for `ChatGPTClient`)
openaiApiKey : process . env . OPENAI_API_KEY || '' ,
// (Optional) Support for a reverse proxy for the completions endpoint (private API server).
// Warning: This will expose your `openaiApiKey` to a third party. Consider the risks before using this.
// reverseProxyUrl: 'https://chatgpt.hato.ai/completions',
// (Optional) Parameters as described in https://platform.openai.com/docs/api-reference/completions
modelOptions : {
// You can override the model name and any other parameters here.
// The default model is `gpt-3.5-turbo`.
model : 'gpt-3.5-turbo' ,
// Set max_tokens here to override the default max_tokens of 1000 for the completion.
// max_tokens: 1000,
} ,
// (Optional) Davinci models have a max context length of 4097 tokens, but you may need to change this for other models.
// maxContextTokens: 4097,
// (Optional) You might want to lower this to save money if using a paid model like `text-davinci-003`.
// Earlier messages will be dropped until the prompt is within the limit.
// maxPromptTokens: 3097,
// (Optional) Set custom instructions instead of "You are ChatGPT...".
// (Optional) Set a custom name for the user
// userLabel: 'User',
// (Optional) Set a custom name for ChatGPT ("ChatGPT" by default)
// chatGptLabel: 'Bob',
// promptPrefix: 'You are Bob, a cowboy in Western times...',
// A proxy string like "http://<ip>:<port>"
proxy : '' ,
// (Optional) Set to true to enable `console.debug()` logging
debug : false ,
} ,
// Options for the Bing client
bingAiClient : {
// Necessary for some people in different countries, e.g. China (https://cn.bing.com)
host : '' ,
// The "_U" cookie value from bing.com
userToken : '' ,
// If the above doesn't work, provide all your cookies as a string instead
cookies : '' ,
// A proxy string like "http://<ip>:<port>"
proxy : '' ,
// (Optional) Set to true to enable `console.debug()` logging
debug : false ,
} ,
chatGptBrowserClient : {
// (Optional) Support for a reverse proxy for the conversation endpoint (private API server).
// Warning: This will expose your access token to a third party. Consider the risks before using this.
reverseProxyUrl : 'https://bypass.churchless.tech/api/conversation' ,
// Access token from https://chat.openai.com/api/auth/session
accessToken : '' ,
// Cookies from chat.openai.com (likely not required if using reverse proxy server).
cookies : '' ,
// A proxy string like "http://<ip>:<port>"
proxy : '' ,
// (Optional) Set to true to enable `console.debug()` logging
debug : false ,
} ,
// Options for the API server
apiOptions : {
port : process . env . API_PORT || 3000 ,
host : process . env . API_HOST || 'localhost' ,
// (Optional) Set to true to enable `console.debug()` logging
debug : false ,
// (Optional) Possible options: "chatgpt", "chatgpt-browser", "bing". (Default: "chatgpt")
clientToUse : 'chatgpt' ,
// (Optional) Generate titles for each conversation for clients that support it (only ChatGPTClient for now).
// This will be returned as a `title` property in the first response of the conversation.
generateTitles : false ,
// (Optional) Set this to allow changing the client or client options in POST /conversation.
// To disable, set to `null`.
perMessageClientOptionsWhitelist : {
// The ability to switch clients using `clientOptions.clientToUse` will be disabled if `validClientsToUse` is not set.
// To allow switching clients per message, you must set `validClientsToUse` to a non-empty array.
validClientsToUse : [ 'bing' , 'chatgpt' , 'chatgpt-browser' ] , // values from possible `clientToUse` options above
// The Object key, e.g. "chatgpt", is a value from `validClientsToUse`.
// If not set, ALL options will be ALLOWED to be changed. For example, `bing` is not defined in `perMessageClientOptionsWhitelist` above,
// so all options for `bingAiClient` will be allowed to be changed.
// If set, ONLY the options listed here will be allowed to be changed.
// In this example, each array element is a string representing a property in `chatGptClient` above.
chatgpt : [
'promptPrefix' ,
'userLabel' ,
'chatGptLabel' ,
// Setting `modelOptions.temperature` here will allow changing ONLY the temperature.
// Other options like `modelOptions.model` will not be allowed to be changed.
// If you want to allow changing all `modelOptions`, define `modelOptions` here instead of `modelOptions.temperature`.
'modelOptions.temperature' ,
] ,
} ,
} ,
// Options for the CLI app
cliOptions : {
// (Optional) Possible options: "chatgpt", "bing".
// clientToUse: 'bing',
} ,
} ;Vous pouvez également installer et exécuter le package directement.
git clone https://github.com/waylaidwanderer/node-chatgpt-apinpm install (si vous n'utilisez pas Docker)settings.example.js en settings.js dans le répertoire racine et modifiez les paramètres si nécessaire.npm start ou npm run server (si vous n'utilisez pas Docker)docker-compose up (nécessite Docker) Démarrez ou poursuivez une conversation. Les paramètres facultatifs ne sont nécessaires que pour les conversations qui s'étendent sur plusieurs requêtes.
| Champ | Description |
|---|---|
| message | Le message à afficher à l'utilisateur. |
| ID de conversation | (Facultatif) Un identifiant pour la conversation que vous souhaitez poursuivre. |
| jailbreakConversationId | (Facultatif, pour BingAIClient uniquement) Définissez sur true pour démarrer une conversation en mode jailbreak. Après cela, cela devrait être l'ID de la conversation de jailbreak (donné dans la réponse en tant que paramètre également nommé jailbreakConversationId ). |
| IDMessageparent | (Facultatif, pour ChatGPTClient et BingAIClient en mode jailbreak) L'ID du message parent (c'est-à-dire response.messageId ) lors de la poursuite d'une conversation. |
| conversationSignature | (Facultatif, pour BingAIClient uniquement) Une signature pour la conversation (donnée dans la réponse en tant que paramètre également nommé conversationSignature ). Obligatoire pour poursuivre une conversation sauf en mode jailbreak. |
| ID client | (Facultatif, pour BingAIClient uniquement) L'ID du client. Obligatoire pour poursuivre une conversation sauf en mode jailbreak. |
| ID d'appel | (Facultatif, pour BingAIClient uniquement) ID de l'appel. Obligatoire pour poursuivre une conversation sauf en mode jailbreak. |
| optionsclient | (Facultatif) Un objet contenant des options pour le client. |
| clientOptions.clientToUse | (Facultatif) Client à utiliser pour ce message. Valeurs possibles : chatgpt , chatgpt-browser , bing . |
| optionsclient.* | (Facultatif) Toutes les options valides pour le client. Par exemple, pour ChatGPTClient , vous pouvez définir clientOptions.openaiApiKey pour définir une clé API pour ce message uniquement, ou clientOptions.promptPrefix pour donner à l'IA des instructions personnalisées pour ce message uniquement, etc. |
Pour configurer les options qui peuvent être modifiées par message (par défaut : toutes), consultez les commentaires pour perMessageClientOptionsWhitelist dans settings.example.js . Pour autoriser le changement de client, perMessageClientOptionsWhitelist.validClientsToUse doit être défini sur un tableau non vide, comme décrit dans l'exemple de fichier de paramètres.
Pour démarrer une conversation avec ChatGPT, envoyez une requête POST au point de terminaison /conversation du serveur avec un corps JSON avec les paramètres par Endpoints > POST /conversation ci-dessus.
{
"message" : " Hello, how are you today? " ,
"conversationId" : " your-conversation-id (optional) " ,
"parentMessageId" : " your-parent-message-id (optional, for `ChatGPTClient` only) " ,
"conversationSignature" : " your-conversation-signature (optional, for `BingAIClient` only) " ,
"clientId" : " your-client-id (optional, for `BingAIClient` only) " ,
"invocationId" : " your-invocation-id (optional, for `BingAIClient` only) " ,
}Le serveur renverra un objet JSON contenant la réponse de ChatGPT :
// HTTP/1.1 200 OK
{
"response" : "I'm doing well, thank you! How are you?" ,
"conversationId" : "your-conversation-id" ,
"messageId" : "response-message-id (for `ChatGPTClient` only)" ,
"conversationSignature" : "your-conversation-signature (for `BingAIClient` only)" ,
"clientId" : "your-client-id (for `BingAIClient` only)" ,
"invocationId" : "your-invocation-id (for `BingAIClient` only - pass this new value back into subsequent requests as-is)" ,
"details" : "an object containing the raw response from the client"
}Si la requête échoue, le serveur renverra un objet JSON avec un message d'erreur.
S'il manque une propriété requise à l'objet de requête (par exemple, message ) :
// HTTP/1.1 400 Bad Request
{
"error" : "The message parameter is required."
}S'il y a eu une erreur lors de l'envoi du message à ChatGPT :
// HTTP/1.1 503 Service Unavailable
{
"error" : "There was an error communicating with ChatGPT."
} Vous pouvez définir "stream": true dans le corps de la requête pour recevoir un flux de jetons au fur et à mesure de leur génération.
import { fetchEventSource } from '@waylaidwanderer/fetch-event-source' ; // use `@microsoft/fetch-event-source` instead if in a browser environment
const opts = {
method : 'POST' ,
headers : {
'Content-Type' : 'application/json' ,
} ,
body : JSON . stringify ( {
"message" : "Write a poem about cats." ,
"conversationId" : "your-conversation-id (optional)" ,
"parentMessageId" : "your-parent-message-id (optional)" ,
"stream" : true ,
// Any other parameters per `Endpoints > POST /conversation` above
} ) ,
} ;Voir demos/use-api-server-streaming.js pour un exemple de la façon de recevoir la réponse telle qu'elle est générée. Vous recevrez un jeton à la fois, vous devrez donc les concaténer vous-même.
Sortie réussie :
{ data : '' , event : '' , id : '' , retry : 3000 }
{ data : 'Hello' , event : '' , id : '' , retry : undefined }
{ data : '!' , event : '' , id : '' , retry : undefined }
{ data : ' How' , event : '' , id : '' , retry : undefined }
{ data : ' can' , event : '' , id : '' , retry : undefined }
{ data : ' I' , event : '' , id : '' , retry : undefined }
{ data : ' help' , event : '' , id : '' , retry : undefined }
{ data : ' you' , event : '' , id : '' , retry : undefined }
{ data : ' today' , event : '' , id : '' , retry : undefined }
{ data : '?' , event : '' , id : '' , retry : undefined }
{ data : '<result JSON here, see Method 1>' , event : 'result' , id : '' , retry : undefined }
{ data : '[DONE]' , event : '' , id : '' , retry : undefined }
// Hello! How can I help you today?Sortie d'erreur :
const message = {
data : '{"code":503,"error":"There was an error communicating with ChatGPT."}' ,
event : 'error' ,
id : '' ,
retry : undefined
} ;
if ( message . event === 'error' ) {
console . error ( JSON . parse ( message . data ) . error ) ; // There was an error communicating with ChatGPT.
} fetch-event-source et utiliser la méthode POST . Suivez les mêmes instructions de configuration pour le serveur API, en créant settings.js .
Si installé globalement :
chatgpt-cliSi installé localement :
npm run cliLes réponses de ChatGPT sont automatiquement copiées dans votre presse-papiers afin que vous puissiez les coller dans d'autres applications.
Comme le montrent les exemples ci-dessus, vous pouvez définir reverseProxyUrl dans les options de ChatGPTClient pour utiliser un serveur proxy inverse au lieu de l'API ChatGPT officielle. Pour l'instant, c'est la seule façon d'utiliser les modèles sous-jacents ChatGPT . Cette méthode a été corrigée et les instructions ci-dessous ne sont plus pertinentes, mais vous souhaiterez peut-être toujours utiliser un proxy inverse pour d'autres raisons. Actuellement, les serveurs proxy inverses sont toujours utilisés pour effectuer un contournement Cloudflare pour ChatGPTBrowserClient .
Comment ça marche ? Réponse simple : ChatGPTClient > proxy inverse > serveur OpenAI. Le serveur proxy inverse fait de la magie sous le capot pour accéder au modèle sous-jacent directement via le serveur d'OpenAI, puis renvoie la réponse à ChatGPTClient .
Les instructions sont fournies ci-dessous.
accessToken ).reverseProxyUrl sur https://chatgpt.hato.ai/completions dans settings.js > chatGptClient ou ChatGPTClient .settings.chatGptClient.openaiApiKey ) sur le jeton d'accès ChatGPT que vous avez obtenu à l'étape 1.model sur text-davinci-002-render , text-davinci-002-render-paid ou text-davinci-002-render-sha en fonction des modèles ChatGPT auxquels votre compte a accès. Les modèles doivent être un nom de modèle ChatGPT, et non le nom du modèle sous-jacent, et vous ne pouvez pas utiliser un modèle auquel votre compte n'a pas accès.stream: true (API) ou onProgress (client) comme solution de contournement.accessToken ).reverseProxyUrl sur https://chatgpt.pawan.krd/api/completions dans settings.js > chatGptClient ou ChatGPTClient .settings.chatGptClient.openaiApiKey ) sur le jeton d'accès ChatGPT que vous avez obtenu à l'étape 1.model sur text-davinci-002-render , text-davinci-002-render-paid ou text-davinci-002-render-sha en fonction des modèles ChatGPT auxquels votre compte a accès. Les modèles doivent être un nom de modèle ChatGPT, et non le nom du modèle sous-jacent, et vous ne pouvez pas utiliser un modèle auquel votre compte n'a pas accès.stream: true (API) ou onProgress (client) comme solution de contournement. Une liste de projets géniaux utilisant @waylaidwanderer/chatgpt-api :
Ajoutez le vôtre à la liste en éditant ce README et en créant une pull request !
Un client Web pour ce projet est également disponible sur waylaidwanderer/PandoraAI.
ChatGPTClient Étant donné que gpt-3.5-turbo est le modèle sous-jacent de ChatGPT, j'ai dû faire de mon mieux pour reproduire la façon dont le site Web officiel de ChatGPT l'utilise. Cela signifie que mon implémentation ou le modèle sous-jacent peut ne pas se comporter exactement de la même manière :
Si vous souhaitez contribuer à ce projet, veuillez créer une pull request avec une description détaillée de vos modifications.
Ce projet est sous licence MIT.


