Projet de génération augmentée par récupération (RAG)
If this project helps you, consider buying me a coffee ☕. Your support helps me keep contributing to the open-source community!
La plateforme officielle de bRAGAI sera bientôt lancée. Rejoignez la liste d'attente pour faire partie des premiers à adopter !
Ce référentiel contient une exploration complète de la génération augmentée par récupération (RAG) pour diverses applications. Chaque bloc-notes fournit un guide pratique détaillé pour configurer et expérimenter RAG depuis un niveau d'introduction jusqu'aux implémentations avancées, y compris les requêtes multiples et les versions RAG personnalisées.
Structure du projet
Si vous souhaitez vous y lancer directement, consultez le fichier full_basic_rag.ipynb -> ce fichier vous donnera un code de démarrage passe-partout d'un chatbot RAG entièrement personnalisable.
Assurez-vous d'exécuter vos fichiers dans un environnement virtuel (section de paiement Get Started )
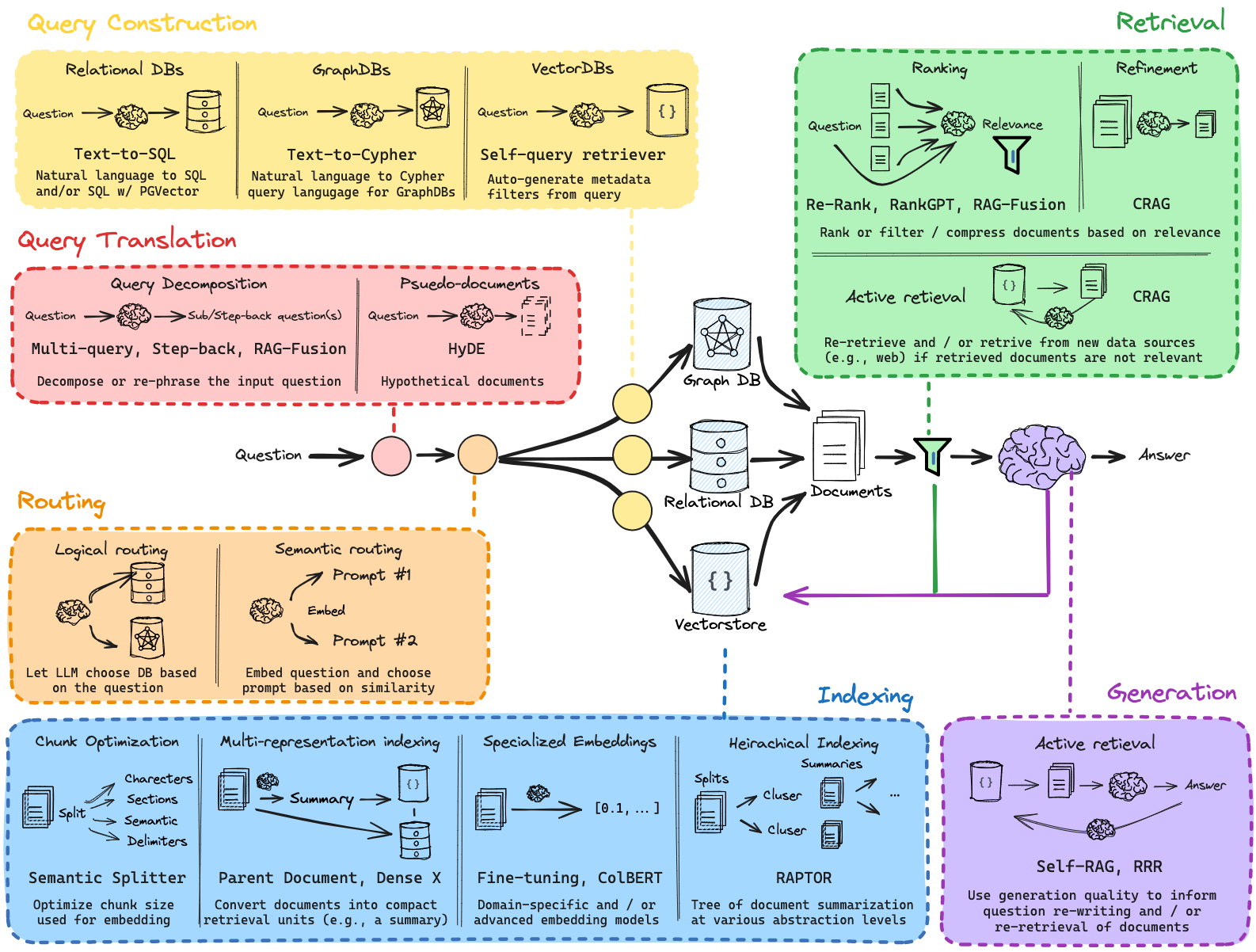
Les blocs-notes suivants se trouvent dans le répertoire tutorial_notebooks/ .
[1]_rag_setup_overview.ipynb
Ce cahier d'introduction fournit un aperçu de l'architecture RAG et de sa configuration fondamentale. Le cahier parcourt :
- Configuration de l'environnement : configuration de l'environnement, installation des bibliothèques nécessaires et configurations d'API.
- Chargement initial des données : chargeurs de documents de base et méthodes de prétraitement des données.
- Génération d'intégration : génération d'intégrations à l'aide de divers modèles, y compris les intégrations d'OpenAI.
- Vector Store : Mise en place d'un magasin de vecteurs (ChromaDB/Pinecone) pour une recherche de similarité efficace.
- Pipeline RAG de base : création d'un pipeline simple de récupération et de génération pour servir de référence.
[2]_rag_with_multi_query.ipynb
S'appuyant sur les bases, ce bloc-notes présente les techniques de requêtes multiples dans le pipeline RAG, explorant :
- Configuration multi-requêtes : configuration de plusieurs requêtes pour diversifier la récupération.
- Techniques d'intégration avancées : utilisation de plusieurs modèles d'intégration pour affiner la récupération.
- Pipeline avec multi-requêtes : implémentation de la gestion multi-requêtes pour améliorer la pertinence dans la génération de réponses.
- Comparaison et analyse : comparaison des résultats avec des pipelines à requête unique et analyse des améliorations de performances.
[3]_rag_routing_and_query_construction.ipynb
Ce bloc-notes approfondit la personnalisation d'un pipeline RAG. Il couvre :
- Routage logique : implémente un routage basé sur des fonctions pour classer les requêtes des utilisateurs vers des sources de données appropriées en fonction des langages de programmation.
- Routage sémantique : utilise les intégrations et la similarité cosinus pour diriger les questions vers une invite mathématique ou physique, optimisant ainsi la précision des réponses.
- Structuration des requêtes pour les filtres de métadonnées : définit un schéma de recherche structuré pour les métadonnées du didacticiel YouTube, permettant un filtrage avancé (par exemple, par nombre de vues, date de publication).
- Invite de recherche structurée : exploite les invites LLM pour générer des requêtes de base de données afin de récupérer le contenu pertinent en fonction des entrées de l'utilisateur.
- Intégration avec les magasins vectoriels : relie les requêtes structurées aux magasins vectoriels pour une récupération efficace des données.
[4]_rag_indexing_and_advanced_retrieval.ipynb
Dans la continuité de la personnalisation précédente, ce carnet explore :
- Préface sur la segmentation de documents : pointe vers des ressources externes pour les techniques de segmentation de documents.
- Indexation multi-représentation : met en place une structure d'indexation multi-vecteur pour gérer des documents avec différentes intégrations et représentations.
- Stockage en mémoire pour les résumés : utilise InMemoryByteStore pour stocker les résumés de documents aux côtés des documents parents, permettant une récupération efficace.
- Configuration MultiVectorRetriever : intègre plusieurs représentations vectorielles pour récupérer des documents pertinents en fonction des requêtes des utilisateurs.
- Implémentation de RAPTOR : explore RAPTOR, un modèle avancé d'indexation et de récupération, reliant à des ressources approfondies.
- Intégration ColBERT : démontre l'indexation et la récupération vectorielles au niveau des jetons basées sur ColBERT, qui capturent la signification contextuelle à un niveau plus fin.
- Exemple Wikipédia avec ColBERT : récupère des informations sur Hayao Miyazaki en utilisant le modèle de récupération ColBERT à des fins de démonstration.
[5]_rag_retrieval_and_reranking.ipynb
Ce dernier notebook rassemble les composants du système RAG, en mettant l'accent sur l'évolutivité et l'optimisation :
- Chargement et fractionnement de documents : charge et fragmente les documents pour l'indexation, les préparant au stockage vectoriel.
- Génération de requêtes multiples avec RAG-Fusion : utilise une approche basée sur des invites pour générer plusieurs requêtes de recherche à partir d'une seule question d'entrée.
- Reciprocal Rank Fusion (RRF) : implémente RRF pour reclasser plusieurs listes de récupération, fusionnant les résultats pour une pertinence améliorée.
- Configuration de la chaîne Retriever et RAG : construit une chaîne de récupération pour répondre aux requêtes, en utilisant des classements fusionnés et des chaînes RAG pour extraire des informations contextuellement pertinentes.
- Cohere Re-Ranking : démontre le reclassement avec le modèle de Cohere pour une compression et un raffinement contextuels supplémentaires.
- CRAG et Self-RAG Retrieval : explore les approches de récupération avancées telles que CRAG et Self-RAG, avec des liens vers des exemples.
- Exploration de l'impact du contexte long : liens vers des ressources expliquant l'impact de la récupération du contexte long sur les modèles RAG.
Commencer
Pré-requis : Python 3.11.7 (de préférence)
Clonez le dépôt :
git clone https://github.com/bRAGAI/bRAG-langchain.git
cd bRAG-langchain
Créer un environnement virtuel
python -m venv venv
source venv/bin/activate
Installer les dépendances : assurez-vous d'installer les packages requis répertoriés dans requirements.txt .
pip install -r requirements.txt
Exécutez les notebooks : commencez par [1]_rag_setup_overview.ipynb pour vous familiariser avec le processus de configuration. Parcourez les autres blocs-notes de manière séquentielle pour créer et expérimenter des concepts RAG plus avancés.
Configurer les variables d'environnement :
Commande de carnet : Pour suivre le projet de manière structurée :
Commencez par [1]_rag_setup_overview.ipynb
Continuez avec [2]_rag_with_multi_query.ipynb
Passez ensuite par [3]_rag_routing_and_query_construction.ipynb
Continuez avec [4]_rag_indexing_and_advanced_retrieval.ipynb
Terminez avec [5]_rag_retrieval_and_reranking.ipynb
Usage
Après avoir configuré l'environnement et exécuté les notebooks dans l'ordre, vous pouvez :
Expérimentez avec la génération augmentée par récupération : utilisez la configuration de base dans [1]_rag_setup_overview.ipynb pour comprendre les bases de RAG.
Implémenter le multi-requête : découvrez comment améliorer la pertinence des réponses en introduisant des techniques de multi-requête dans [2]_rag_with_multi_query.ipynb .
Carnets entrants (travail en cours)
- Précision du contexte avec RAGAS + LangSmith
- Guide sur l'utilisation de RAGAS et LangSmith pour évaluer la précision du contexte, la pertinence et l'exactitude des réponses dans RAG.
- Déploiement de l'application RAG
- Guide sur la façon de déployer votre application RAG
The notebooks and visual diagrams were inspired by Lance Martin's LangChain Tutorial.


