IncognitoPilot
2.1.0

Un interpréteur de code IA pour les données sensibles, alimenté par GPT-4 ou Code Llama / Llama 2.
Incognito Pilot combine un Large Language Model (LLM) avec un interpréteur Python, afin qu'il puisse exécuter du code et exécuter des tâches pour vous. Il est similaire à ChatGPT Code Interpreter , mais l'interpréteur s'exécute localement et peut utiliser des modèles open source comme Code Llama / Llama 2 .
Incognito Pilot vous permet de travailler avec des données sensibles sans les télécharger sur le cloud. Soit vous utilisez un LLM local (comme Llama 2), soit une API (comme GPT-4). Dans ce dernier cas, il existe un mécanisme d'approbation dans l'interface utilisateur, qui sépare vos données locales des services distants.
Avec Incognito Pilot , vous pouvez :
et bien plus encore !
La vidéo montre Incognito Pilot avec GPT-4. Pendant que votre conversation et les résultats de code approuvés sont envoyés à l'API d'OpenAI, vos données sont conservées localement sur votre machine. L'interpréteur fonctionne également localement et traite vos données directement sur place. Et vous pouvez aller encore plus loin et utiliser Code Llama / Llama 2 pour que tout fonctionne sur votre machine.
Cette section montre comment installer Incognito Pilot à l'aide d'un modèle GPT via l'API d'OpenAI. Pour
Suivez ces étapes :
docker run -i -t
-p 3030:80
-e OPENAI_API_KEY= " sk-your-api-key "
-e ALLOWED_HOSTS= " localhost:3030 "
-v /home/user/ipilot:/mnt/data
silvanmelchior/incognito-pilot:latest-slimDans la console, vous devriez maintenant voir une URL. Ouvrez-le et vous devriez voir l'interface Incognito Pilot .
Il est également possible d'exécuter Incognito Pilot avec les crédits d'essai gratuit d'OpenAI, sans ajouter de carte de crédit. Pour le moment, cela n'inclut pas GPT-4, alors voyez ci-dessous comment changer le modèle en GPT-3.5.
Dans l'interface Incognito Pilot , vous verrez une interface de discussion avec laquelle vous pourrez interagir avec le modèle. Essayons-le !
Vous devriez maintenant être prêt à utiliser Incognito Pilot pour vos propres tâches. N'oubliez pas :
Encore une chose : la version que vous venez d'utiliser ne contient pratiquement aucun package livré avec l'interpréteur Python. Cela signifie que des choses comme la lecture d'images ou de fichiers Excel ne fonctionneront pas. Pour changer cela, retournez à la console et appuyez sur Ctrl-C pour arrêter le conteneur. Réexécutez maintenant la commande, mais supprimez le suffixe -slim de l'image. Cela téléchargera une version beaucoup plus grande, équipée de nombreux packages.
Pour utiliser un autre modèle que celui par défaut (GPT-4), définissez la variable d'environnement LLM . Les modèles GPT d'OpenAI ont le préfixe gpt: , donc pour utiliser GPT-3.5 par exemple (le ChatGPT d'origine), ajoutez ce qui suit à la commande docker run :
-e LLM= " gpt-openai:gpt-3.5-turbo "Veuillez noter que GPT-4 est considérablement meilleur dans la configuration de l'interprète que GPT-3.5.
Pour servir l'interface utilisateur sur un port différent de 3030, vous pouvez exposer le port interne 80 à un autre, par exemple 8080. Vous devez également modifier la variable hôte autorisée dans ce cas :
docker run -i -t
-p 8080:80
-e ALLOWED_HOSTS= " localhost:8080 "
...
silvanmelchior/incognito-pilotPar défaut, le jeton d'authentification, qui fait partie de l'URL que vous ouvrez, est généré aléatoirement au démarrage. Cela signifie que chaque fois que vous redémarrez le conteneur, vous devez recopier l'URL. Si vous souhaitez éviter cela, vous pouvez également fixer le jeton à une certaine valeur, en ajoutant ce qui suit à la commande docker run :
-e AUTH_TOKEN= " some-secret-token " Une fois que vous avez ouvert l'URL avec le nouveau jeton, le navigateur s'en souviendra. Ainsi, désormais, vous pouvez accéder à Incognito Pilot en ouvrant simplement http://localhost:3030, sans avoir à ajouter de token à l'URL.
Par défaut, l'interpréteur Python s'arrête au bout de 30 secondes. Pour changer cela, définissez la variable d'environnement INTERPRETER_TIMEOUT . Pendant 2 minutes par exemple, ajoutez ce qui suit à la commande docker run :
-e INTERPRETER_TIMEOUT= " 120 " Pour démarrer automatiquement Incognito Pilot avec docker / au démarrage, supprimez le -i -t de la commande d'exécution et ajoutez ce qui suit :
--restart alwaysAvec un signet de l'URL de l'interface utilisateur, vous aurez Incognito Pilot à portée de main chaque fois que vous en aurez besoin. Vous pouvez également utiliser docker-compose.
Vous n'êtes pas satisfait des packages préinstallés de la version complète (c'est-à-dire non slim) ? Vous souhaitez ajouter plus de packages Python (ou Debian) à l'interpréteur ?
Vous pouvez facilement conteneuriser vos propres dépendances avec Incognito Pilot . Pour ce faire, créez un Dockerfile comme ceci :
FROM silvanmelchior/incognito-pilot:latest-slim
SHELL [ "/bin/bash" , "-c" ]
# uncomment the following line, if you want to install more packages
# RUN apt update && apt install -y some-package
WORKDIR /opt/app
COPY requirements.txt .
RUN source venv_interpreter/bin/activate &&
pip3 install -r requirements.txtPlacez vos dépendances dans un fichier Requirements.txt et exécutez la commande suivante :
docker build --tag incognito-pilot-custom .Ensuite, exécutez le conteneur comme ceci :
docker run -i -t
...
incognito-pilot-customNon, cela a ses limites. Le compromis entre confidentialité et fonctionnalités n’est pas facile dans ce cas. Pour des choses comme les images, il est aussi puissant que l'interpréteur de code ChatGPT, car il n'a pas besoin de connaître le contenu de l'image pour la modifier. Mais pour des choses comme les feuilles de calcul, si ChatGPT ne voit pas le contenu, il doit par exemple deviner le format des données à partir de l'en-tête, ce qui peut mal tourner.
Cependant, à certains égards, il est encore meilleur que l'interpréteur de code ChatGPT : l'interpréteur a accès à Internet, ce qui permet d'effectuer un certain nombre de nouvelles tâches qui n'étaient pas possibles auparavant. De plus, vous pouvez exécuter l'interpréteur sur n'importe quelle machine, y compris les plus puissantes, afin de pouvoir résoudre des tâches beaucoup plus importantes qu'avec l'interpréteur de code ChatGPT.
Vous pouvez bien sûr le faire. L'utilisation d' Incognito Pilot présente cependant de nombreux avantages :
Quoi que vous tapiez et tous les résultats de code que vous approuvez ne sont en effet pas privés, dans le sens où ils sont envoyés à l'API cloud. Vos données restent cependant locales. L'interpréteur fonctionne également localement, traitant vos données là où elles se trouvent. Pour certaines choses, vous devrez indiquer au modèle quelque chose à propos de vos données (par exemple, le nom de fichier de la structure), mais il s'agit généralement de métadonnées que vous approuvez activement dans l'interface utilisateur et non des données réelles. À chaque étape de l'exécution, vous pouvez simplement refuser que quelque chose soit envoyé à l'API.
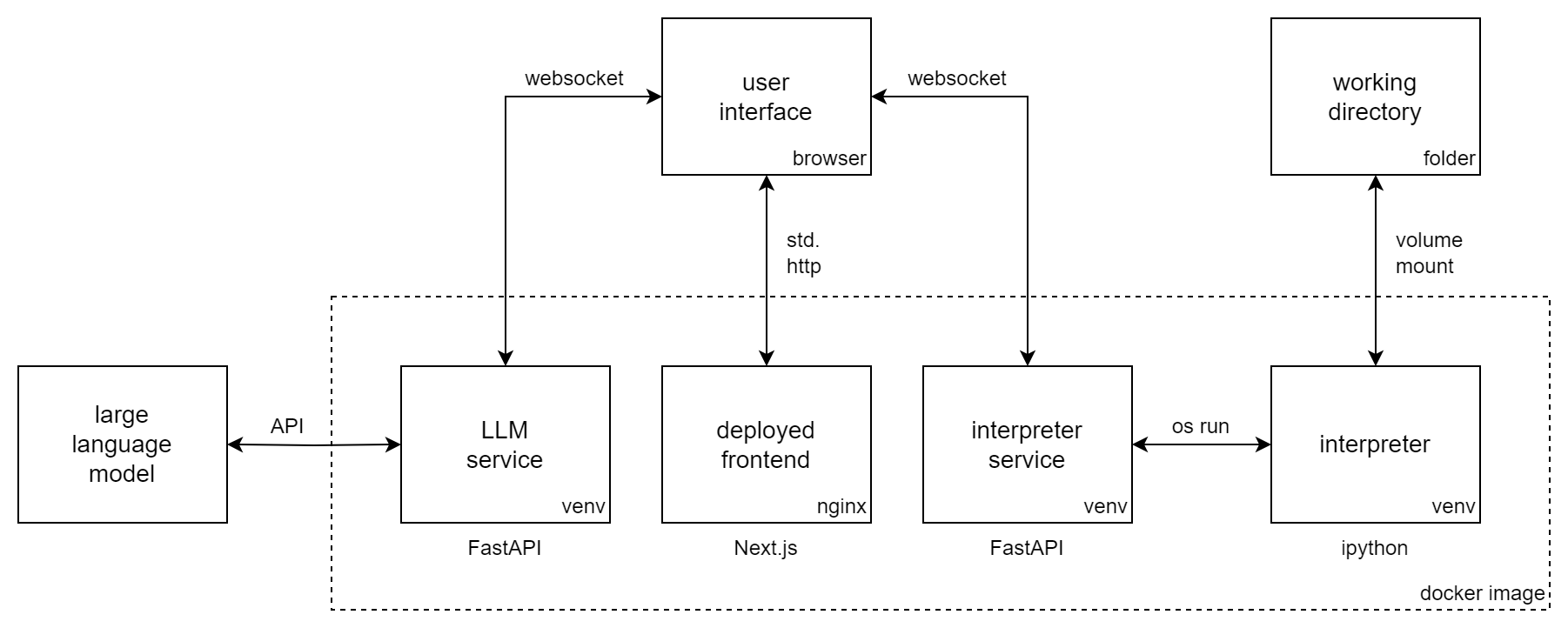
Vous souhaitez contribuer à Incognito Pilot ? Ou simplement l'installer sans docker ? Consultez les instructions et les directives de contribution.


