Chronologie de ChatGPT, GenerativeAI et LLM
Ce référentiel organise une chronologie des événements clés (produits, services, articles, GitHub, articles de blog et actualités) survenus avant et après l'annonce de ChatGPT.
Il rassemble une variété d'informations dans cette chronologie, avec un accent particulier sur le LLM et l'IA générative.
C'est peut-être une scène de l'histoire la plus chaude, alors j'ai pensé qu'il serait important de bien conserver ces souvenirs, alors je les ai organisés.
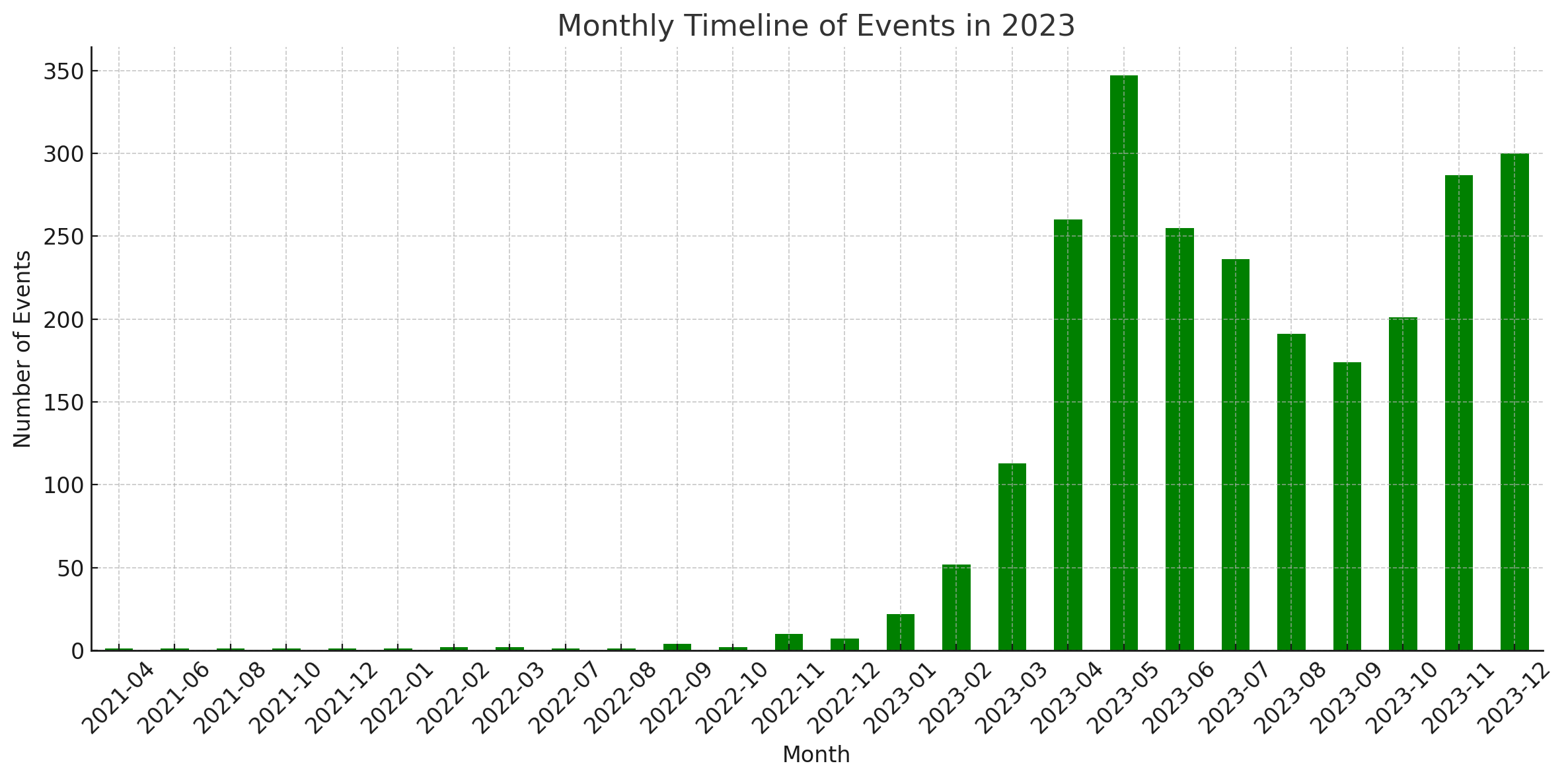
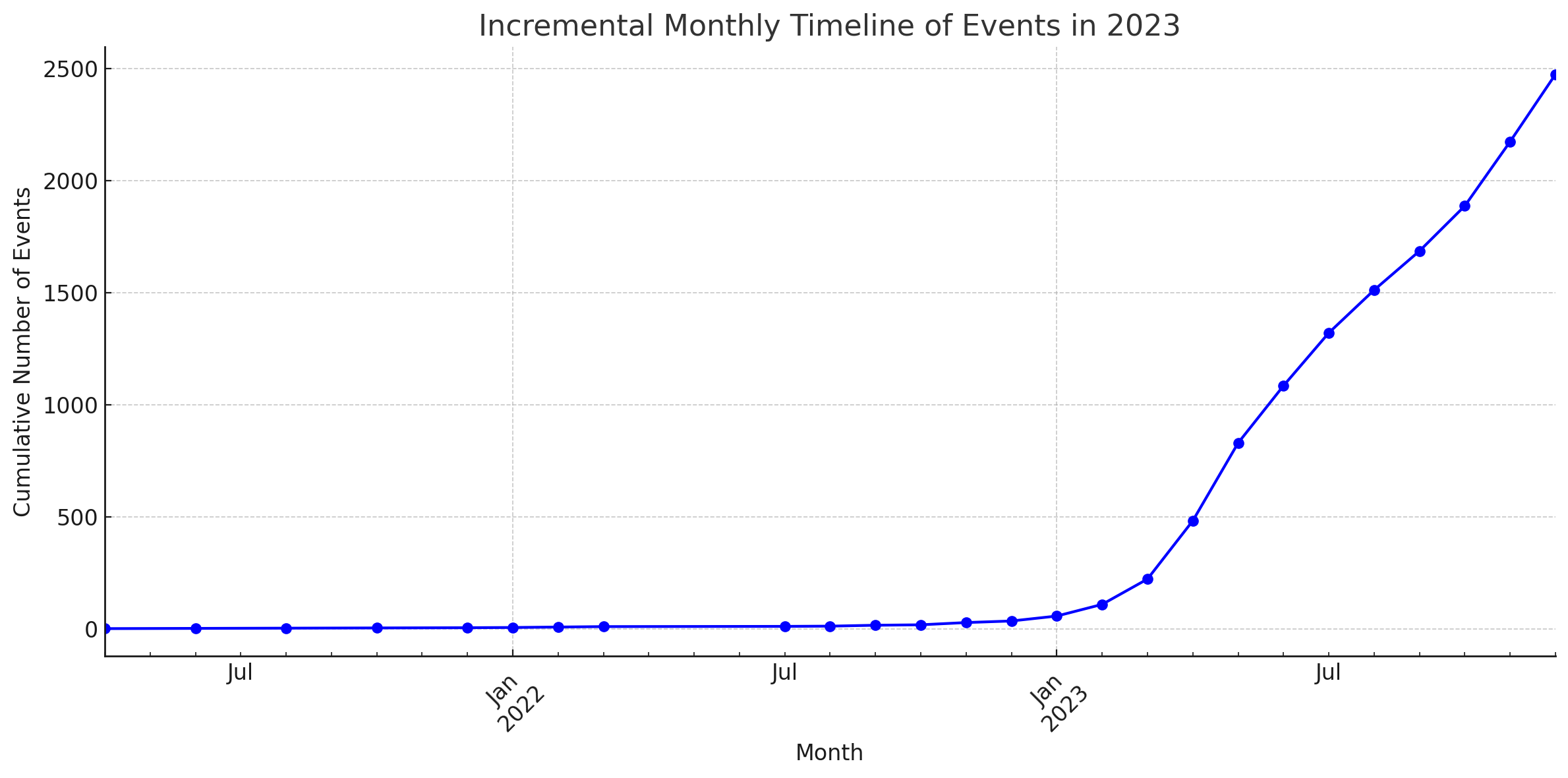
Statistiques
Ces diagrammes ont été générés par l'interprète de code de ChatGPT.
Contribuer
Les problèmes et les demandes de tirage sont grandement appréciés. Si vous n'avez jamais contribué à un projet open source auparavant, je serai plus qu'heureux de vous expliquer comment créer une pull request.
Vous pouvez commencer par ouvrir un ticket décrivant le problème que vous cherchez à résoudre et nous partirons de là.
Émoji
arXiv , PDF ?, arxiv-vanity ?, page papier ?, articles avec code ✳️, Github
Licence
Ce document est sous licence MIT © Jonghong Jeon (전종홍)
Chronologie V2
2024
- 17/05 - OpenAI conclut un accord avec Reddit pour entraîner son IA sur vos publications
(Nouvelles), - 17/05 - OpenAI dissout son équipe axée sur les risques à long terme de l'IA, moins d'un an après son annonce
(Nouvelles), - 17/05 - Rapport scientifique international sur la sécurité de l'IA avancée
(Blog), - 16/05 - TRANSIC : Transfert de politique du Sim au réel en apprenant de la correction en ligne
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Toon3D : Voir les dessins animés sous un nouvel angle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Test de la fiabilité d'un grand modèle de langage basé sur l'IA pour extraire des informations écologiques de la littérature scientifique
(Nouvelles), - 16/05 - Apprentissage en contexte à plusieurs plans dans les modèles de base multimodaux
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Comment mettre en pause l'IA avant qu'il ne soit trop tard
(Nouvelles), - 16/05 - Grounding DINO 1.5 : avancez à la "bordure" de la détection d'objets en espace ouvert
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 – Exploration et analyse du magasin GPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Dual3D : génération de texte en 3D efficace et cohérente avec diffusion latente multi-vues bimode
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Chameleon : modèles de base de fusion précoce à modes mixtes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - CAT3D : Créez n'importe quoi en 3D avec des modèles de diffusion multi-vues
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - Xmodel-VLM : une base de référence simple pour un modèle de langage de vision multimodale
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - LoRA apprend moins et oublie moins
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - Le filigrane invisible de l'IA de Google aidera à identifier le texte et la vidéo génératifs
(Nouvelles), - 15/05 - Google I/O 2024 : tout annoncé
(Blog), - 15/05 - BEHAVIOR Vision Suite : Génération d'ensembles de données personnalisables via simulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - ALPINE : Dévoilement de la capacité de planification de l'apprentissage autorégressif dans les modèles de langage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Comprendre l'écart de performances entre les algorithmes d'alignement en ligne et hors ligne
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - SpeechVerse : un modèle de langage audio généralisable à grande échelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - SpeechGuard : Explorer la robustesse contradictoire des grands modèles de langage multimodaux
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Pas de temps à perdre : consacrez du temps à la chaîne pour comprendre la vidéo mobile
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Hunyuan-DiT : un puissant transformateur de diffusion multi-résolution avec une compréhension fine du chinois
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Génération compositionnelle de texte en image avec des représentations de blob denses
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Au-delà des lois de mise à l'échelle : comprendre les performances des transformateurs avec la mémoire associative
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - SambaNova SN40L : étendre le mur de mémoire de l'IA avec le flux de données et la composition d'experts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/13 - Workflow RLHF : De la modélisation des récompenses au RLHF en ligne
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - Plot2Code : Un benchmark complet pour évaluer les grands modèles de langage multimodaux dans la génération de code à partir de tracés scientifiques
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/13 - OpenAI dévoile son nouveau modèle d'IA, GPT-4o
(Nouvelles), - 13/05 - Recherche Web MS MARCO : un ensemble de données Web riche en informations à grande échelle avec des millions d'étiquettes de clics réels
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/13 - Quelle quantité de recherche est écrite à l'aide de grands modèles de langage ?
(Blog), - 13/05 - Bonjour GPT-4o
(Blog), - 05/13 - Coin3D : Génération d'actifs 3D contrôlables et interactifs avec conditionnement guidé par proxy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/11 - Piccolo2 : Intégration générale de texte avec formation multi-tâches sur les pertes hybrides
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/11 - LogoMotion : Génération de code visuellement fondé pour une animation sensible au contenu
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/10 - INSPECT - Un framework open source pour les évaluations de grands modèles de langage
(Blog), - 05/10 - AI Safety Institute lance une nouvelle plateforme d'évaluation de la sécurité de l'IA
(Nouvelles), - 05/07 - SUTRA : Architecture de modèle de langage multilingue évolutive
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/07 - Meta lance Llama 3 Open-Source LLM
(Nouvelles), - 05/03 - Qu'est-ce qui compte lors de la construction de modèles vision-langage ?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - WildChat : 1 million de journaux d'interaction ChatGPT dans la nature
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - StoryDiffusion : auto-attention constante pour la génération d'images et de vidéos à longue portée
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - Prometheus 2 : Un modèle de langage Open Source spécialisé dans l'évaluation d'autres modèles de langage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - NeMo-Aligner : boîte à outils évolutive pour un alignement efficace des modèles
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - LLM-AD : Système de description audio basé sur un grand modèle linguistique
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - FLAME : alignement factuel pour les grands modèles linguistiques
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - Personnalisation des modèles texte-image avec une seule paire d'images
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - Champs gaussiens à élagage spectral avec compensation neuronale
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - Optimisation des préférences d'auto-lecture pour l'alignement du modèle linguistique
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - Une taille de lot d'édition plus grande est-elle toujours meilleure ? -- Une étude empirique sur l'édition de modèles avec Llama-3
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - Clover : décodage spéculatif léger régressif avec connaissances séquentielles
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - Un examen attentif des performances des grands modèles de langage en arithmétique scolaire
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 – Visual Fact Checker : Activation de la génération de sous-titres détaillés haute fidélité
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - STT : Stateful Tracking avec transformateurs pour la conduite autonome
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - SemantiCodec : un codec audio sémantique à très faible débit pour le son général
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Octopus v4 : Graphique des modèles de langage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - MotionLCM : Génération de mouvement contrôlable en temps réel via un modèle de cohérence latente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - MicroDreamer : Génération 3D Zero-shot en sim20 secondes par reconstruction itérative basée sur le score
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Lightplane : composants hautement évolutifs pour les champs neuronaux 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - KAN : Réseaux Kolmogorov-Arnold
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Optimisation des préférences de raisonnement itératif
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Invisible Stitch : Générer des scènes 3D fluides avec l'inpainting en profondeur
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - InstantFamily : Attention masquée pour la génération d'images multi-ID Zero-shot
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - GS-LRM : Grand modèle de reconstruction pour les éclaboussures gaussiennes 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 – Multiplier par dix le contexte de Llama-3 du jour au lendemain
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - DOCCI : Descriptions d'images connectées et contrastées
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Modèles de langage étendus meilleurs et plus rapides via la prédiction multi-jetons
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Stylet : Sélection automatique d'adaptateur pour les modèles à diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - SAGS : éclaboussures gaussiennes 3D sensibles à la structure
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Remplacer les juges par des jurys : évaluer les générations LLM avec un panel de modèles divers
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Profil d'IA génératif NIST AI RMF
(Nouvelles), - 29/04 - LoRA Land : 310 LLM affinés qui rivalisent avec GPT-4, un rapport technique
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Kangourou : décodage auto-spéculatif sans perte via une double sortie anticipée
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Capacités des modèles Gémeaux en médecine
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 28/04 - Paint by Inpaint : apprendre à ajouter des objets image en les supprimant d'abord
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 28/04 - LEGENT : Plateforme Ouverte pour Agents Incarnés
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 27/04 - Ag2Manip : apprentissage de nouvelles compétences de manipulation avec des représentations visuelles et d'action indépendantes des agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 26/04 - MaPa : Peinture de matériaux photoréalistes basée sur du texte pour des formes 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 26/04 - BlenderAlchemy : Édition de graphiques 3D avec des modèles Vision-Language
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Rapport Technique Télé-FLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - SEED-Bench-2-Plus : analyse comparative de modèles multimodaux de grands langages avec une compréhension visuelle riche en texte
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Revisiter l'évaluation texte-image avec Gecko : sur les métriques, les invites et les évaluations humaines
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - PLLaVA : Extension LLaVA sans paramètres des images aux vidéos pour le sous-titrage vidéo dense
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Faites en sorte que votre LLM utilise pleinement le contexte
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Répertorier les éléments un par un : une nouvelle source de données et un nouveau paradigme d'apprentissage pour les LLM multimodaux
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Saut de couche : permettre l'inférence de sortie anticipée et le décodage auto-spéculatif
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Interactive3D : Créez ce que vous voulez grâce à la génération 3D interactive
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Jusqu'où sommes-nous du GPT-4V ? Combler l'écart avec les modèles multimodaux commerciaux avec des suites Open Source
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - ConsistentID : génération de portraits avec préservation d'identité multimodale à grain fin
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - XC-Cache : assistance croisée au contexte mis en cache pour une inférence LLM efficace
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - L'éthique des assistants avancés en IA
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - PuLID : personnalisation des identifiants Pure et Lightning via un alignement contrasté
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - NeRF-XL : mise à l'échelle des NeRF avec plusieurs GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MotionMaster : transfert de mouvement de caméra sans formation pour la génération vidéo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MoDE : Experts CLIP Data via Clustering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MMT-Bench : Un benchmark multimodal complet pour évaluer les grands modèles de langage de vision vers une AGI multitâche
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MaGGIe : Tapis d'instance humaine progressif guidé et masqué
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - ID-Aligner : Améliorer la génération de texte en image préservant l'identité grâce à l'apprentissage par retour de récompense
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - Éléments d'image modifiables pour une synthèse contrôlable
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - CatLIP : précision de reconnaissance visuelle de niveau CLIP avec un pré-entraînement 2,7 fois plus rapide sur les données image-texte à l'échelle du Web
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - BASS : échantillonnage spéculatif par lots optimisé pour l'attention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - Les transformateurs peuvent représenter des modèles de langage n-gram
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - Rapport technique Pegasus-v1
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - Mélange d'experts multi-têtes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - FlashSpeech : synthèse vocale efficace Zero-Shot
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - SnapKV : LLM sait ce que vous recherchez avant la génération
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - SEED-X : Modèles multimodaux avec compréhension et génération multi-granularité unifiée
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Reconstruction des coordonnées de scène : pose de collections d'images via l'apprentissage incrémental d'un relocaliseur
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Rapport technique Phi-3 : un modèle de langage hautement performant localement sur votre téléphone
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - OpenELM : une famille de modèles de langage efficace avec un cadre de formation et d'inférence open source
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - MultiBooth : vers la génération de tous vos concepts dans une image à partir d'un texte
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Apprentissage du contrôle de locomotion H-Infinity
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Quelle est la qualité des modèles LLaMA3 quantifiés à faible bit ? Une étude empirique
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Alignez vos étapes : optimisation des programmes d'échantillonnage dans les modèles de diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Un agent d'interprétabilité automatisé multimodal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 21/04 - Hyper-SD : Modèle de cohérence segmentée de trajectoire pour une synthèse d'images efficace
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 21/04 - AdvPrompter : invites contradictoires adaptatives rapides pour les LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 20/04 - Modèles de cohérence musicale
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - La hiérarchie des instructions : former les LLM pour prioriser les instructions privilégiées
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - TextSquare : Optimisation du réglage des instructions visuelles centrées sur le texte
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - PhysDreamer : Interaction basée sur la physique avec des objets 3D via la génération vidéo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - LLM-R2 : un système de réécriture amélioré basé sur des règles pour un grand modèle de langage pour améliorer l'efficacité des requêtes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - À quel point la réalité est-elle réelle ? Un cadre d’évaluation humaine pour des exemples contradictoires sans restriction
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - Jusqu'où pouvons-nous aller avec la réparation pratique des programmes au niveau des fonctions ?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - Groma : tokenisation visuelle localisée pour la mise à la terre de grands modèles de langage multimodaux
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - Le Splatting gaussien nécessite-t-il une initialisation SFM ?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - AutoCrawler : un agent Web à compréhension progressive pour la génération de robots Web
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - TriForce : accélération sans perte de la génération de séquences longues avec décodage spéculatif hiérarchique
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Vers l'auto-amélioration des LLM via l'imagination, la recherche et la critique
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Réutilisez vos récompenses : transfert de modèle de récompense pour un alignement multilingue Zero-Shot
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Reka Core, Flash et Edge : une série de modèles linguistiques multimodaux puissants
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - OpenBezoar : petits modèles ouverts et rentables formés sur des mélanges de données d'instruction
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - MeshLRM : Grand modèle de reconstruction pour un maillage de haute qualité
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Présentation de la version 0.5 du référentiel de sécurité AI de MLCommons
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Présentation de Meta Llama 3 : le LLM le plus performant disponible à ce jour
(Blog), - 18/04 - EdgeFusion : génération de texte en image sur l'appareil
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - BLINK : les grands modèles de langage multimodaux peuvent voir mais pas percevoir
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - AniClipart : animation clipart avec priorités texte-vidéo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - MoA : Mélange d'attention pour le démêlage sujet-contexte dans la génération d'images personnalisées
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - FlowMind : Génération automatique de workflows avec des LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - Typographie dynamique : donner vie aux mots
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - API Stable Diffusion 3 maintenant disponible
(twitter), (Blog), (Démo), - 16/04 - VASA-1 : visages parlants réalistes pilotés par audio générés en temps réel
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 16/04 - La secrétaire américaine au Commerce, Gina Raimondo, annonce l'expansion de l'équipe de direction de l'AI Safety Institute des États-Unis
(Nouvelles), - 16/04 - Génération de musique longue durée avec diffusion latente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/04 - Les évaluateurs LLM reconnaissent et favorisent leurs propres générations
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/04 - Video2Game : Environnement temps réel, interactif, réaliste et compatible avec un navigateur à partir d'une seule vidéo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - Tango 2 : Aligner les générations texte-audio basées sur la diffusion grâce à l'optimisation des préférences directes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 15/04 - Apprivoiser le modèle de diffusion latente pour l'inpainting du champ de rayonnement neuronal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - Opus peut fonctionner comme une machine de Turing
(gazouillement), - 15/04 - MathGPT : exploiter Llama 2 pour créer une plateforme d'apprentissage hautement personnalisé
- 15/04 - HQ-Edit : un ensemble de données de haute qualité pour l'édition d'images basée sur des instructions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - Ctrl-Adapter : un framework efficace et polyvalent pour adapter divers contrôles à n'importe quel modèle de diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - La compression représente l'intelligence de manière linéaire
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - CompGS : représentation efficace de scènes 3D via des éclaboussures gaussiennes compressées
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 14/04 - TextHawk : Explorer la perception fine et efficace des grands modèles de langage multimodaux
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/13 - Cathie Wood se renforce dans le boom de ChatGPT avec une nouvelle participation OpenAI
(Nouvelles), - 04/12 - Mise à l'échelle (vers le bas) du CLIP : une analyse complète des données, de l'architecture et des stratégies de formation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - Sonder la conscience 3D des modèles de fondations visuelles
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - Pré-entraînement des petits LM de base avec moins de jetons
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - Sur la robustesse du guidage linguistique pour les tâches de vision de bas niveau : résultats de l'estimation de la profondeur
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - MonoPatchNeRF : amélioration des champs de rayonnement neuronal grâce au guidage monoculaire basé sur des patchs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - Megalodon : pré-entraînement et inférence LLM efficaces avec une longueur de contexte illimitée
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - ChatGPT transforme-t-il le style d'écriture des universitaires ?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - COCONut : Moderniser la segmentation COCO
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - La puce IA réduit le budget énergétique de plus de 99 %
(Nouvelles), - 04/12 - AdapterSwap : Formation continue des LLM avec garanties de suppression des données et de contrôle d'accès
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - Aperçu de la vision Grok-1.5
(Démo), - 04/12 - Le bon, le mauvais et l'humain Badge
(Nouvelles), - 04/12 – Les utilisateurs payants de ChatGPT peuvent désormais accéder à GPT-4 Turbo
(twitter), (Actualités), , () - 04/11 - La nécessité des conseils des normes d'audit en IA
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/11 - Se souvenir de Transformer pour l'apprentissage continu
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Amazon ajoute Andrew Ng, une voix leader dans le domaine de l'intelligence artificielle, à son conseil d'administration
(Nouvelles), - 04/11 - Adobe achète des vidéos pour 3 $ la minute pour créer un modèle d'IA
(Nouvelles), - 04/11 - UltraEval : une plateforme légère pour une évaluation flexible et complète des LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - Efficacité transférable et fondée sur des principes pour la segmentation du vocabulaire ouvert
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - Agent SWE
(twitter), (Démo), , () - 04/11 - Formeur de voie clairsemé
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Rho-1 : Tous les jetons ne sont pas ce dont vous avez besoin
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - ResearchAgent : Génération itérative d'idées de recherche sur la littérature scientifique avec de grands modèles de langage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - RecurrentGemma : dépasser les transformateurs pour des modèles de langage ouvert efficaces
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - OSWorld : analyse comparative des agents multimodaux pour des tâches ouvertes dans des environnements informatiques réels
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - LLoCO : Apprendre des contextes longs hors ligne
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Tirer parti des grands modèles linguistiques (LLM) pour prendre en charge l'annotation collaborative des données sur les risques en ligne entre l'homme et l'IA
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - JetMoE : atteindre les performances de Llama2 avec 0,1 million de dollars
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) (Projet), (twitter), , (✳️), () - 04/11 - HGRN2 : RNN linéaires fermés avec extension d'état
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - Des mots aux chiffres : votre grand modèle de langage est secrètement un régresseur capable lorsqu'on lui donne des exemples contextuels
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Ferret-v2 : une base de référence améliorée pour la référence et la mise à la terre avec de grands modèles de langage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - ControlNet++ : amélioration des contrôles conditionnels avec un retour de cohérence efficace
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Détection d'anomalies vidéo contextuelles dans les ensembles de données à long terme
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - ChatGPT-3.5, Claude 3 donne un coup de pied pixelisé dans le tournoi Street Fighter III pour les LLM
(Nouvelles), - 04/11 - ChatGPT peut prédire l'avenir lorsqu'il raconte des histoires se déroulant dans le futur sur le passé
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Bonnes pratiques et leçons apprises sur les données synthétiques pour les modèles de langage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Benchmark des LLM en combattant dans Street Fighter 3
(Démo), , () - 04/11 - Audio Dialogues : ensemble de données de dialogues pour la compréhension audio et musicale
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - L'application de conseils dans un intervalle limité améliore la qualité de l'échantillon et de la distribution dans les modèles de diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - AmpleGCG : Apprentissage d'un modèle génératif universel et transférable de suffixes contradictoires pour le jailbreak des LLM ouverts et fermés
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/10 - Outil de transparence LM : outil interactif pour analyser les modèles de langage de transformateur
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - Gemini 1.5 Pro comprend désormais l'audio
(gazouillement), - 04/10 - Explorer la profondeur des concepts : comment les grands modèles linguistiques acquièrent des connaissances à différentes couches ?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/10 - Urban Architect : Génération de scènes urbaines 3D orientables avec mise en page préalable
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - RealmDreamer : Génération de scènes 3D basée sur le texte avec Inpainting et diffusion de profondeur
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - OpenAI et Meta sont sur le point de publier des modèles d'IA capables de raisonner comme les humains, selon un rapport
(Nouvelles), - 04/10 - MetaCheckGPT -- Un détecteur d'hallucinations multitâche utilisant l'incertitude LLM et les méta-modèles
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - Meta confirme que son LLM open source Llama 3 arrivera le mois prochain
(Nouvelles), - 04/10 - Ne laissez aucun contexte de côté : transformateurs de contexte infinis efficaces avec une attention infinie
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - XAI incrémental : compréhension mémorable de l'IA avec des explications incrémentales
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - DreamScene360 : Génération de scène texte en 3D sans contrainte avec éclaboussures gaussiennes panoramiques
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - Le Mapo Tofu contient-il du café ? Sonder les LLM pour les connaissances culturelles liées à l'alimentation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - BRAVE : Élargir l'encodage visuel des modèles vision-langage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - La startup d'IA Mistral lance un modèle d'IA de 281 Go pour rivaliser avec OpenAI, Meta et Google
(Nouvelles), - 04/10 - Communication sémantique générative pilotée par agent pour la surveillance à distance
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - Adaptation du décodeur LLaMA au transformateur de vision
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - Une enquête sur l'intégration de l'IA générative pour la pensée critique dans les réseaux mobiles
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - Jetez-y un oeil ! Repenser la façon d'évaluer le jailbreak du modèle de langage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - RÈGLE : Quelle est la taille réelle du contexte de vos modèles de langage à contexte long ?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Révision de la densification dans le splatting gaussien
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - Reconstruire des objets portatifs en 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - RAR-b : Le raisonnement comme référence de recherche
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - Ingénierie des invites pour la préservation de la confidentialité : une enquête
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - Sur l'évaluation de l'efficacité du code source généré par les LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/09 - Rapport technique OmniFusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - MuPT : un transformateur pré-entraîné de musique symbolique générative
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - MiniCPM : dévoiler le potentiel des petits modèles de langage avec des stratégies de formation évolutives
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Magic-Boost : Boostez la génération 3D avec la diffusion conditionnée Mutli-View
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - LLM2Vec : les grands modèles de langage sont des encodeurs de texte secrètement puissants
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - InternLM-XComposer2-4KHD : un modèle pionnier en langage de grande vision gérant des résolutions de 336 pixels à 4K HD
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Hash3D : accélération sans formation pour la génération 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Google dévoile des projets open source pour l'IA générative
(Nouvelles), - 04/09 - Les éléphants n'oublient jamais : mémorisation et apprentissage de données tabulaires dans de grands modèles de langage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Apple vient de dévoiler le nouveau Ferret-UI LLM — cette IA peut lire l'écran de votre iPhone
(Nouvelles), - 04/09 - AEGIS : modération de la sécurité du contenu d'IA adaptative en ligne avec un ensemble d'experts LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - YaART : Encore une autre technologie de rendu ART
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - WILBUR : Apprentissage adaptatif en contexte pour des agents Web robustes et précis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - UniFL : Améliorer la diffusion stable via un apprentissage par feedback unifié
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - Icarus débridé : étude des dangers potentiels des entrées d'images dans la sécurité des modèles multimodaux de langage étendu
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - Le classement des hallucinations -- Un effort ouvert pour mesurer les hallucinations dans de grands modèles de langage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - Le problème de sélection des faits dans la réparation de programmes basés sur LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/08 - Swapanything: activer un échange d'objets arbitraires dans l'édition visuelle personnalisée
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Sambalingo: enseigner des modèles de grande langue nouvelles langues
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Optimisation des préférences négatives: de l'effondrement catastrophique à un désapprentissage efficace
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Naver fait ses débuts multilingues HyperClova X LLM Il sera utilisé pour construire une IA souverain pour l'Asie
(Nouvelles), - 04/08 - MoMA: adaptateur LLM multimodal pour la génération d'images personnalisée rapide
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - MEDEXPQA: référence multilingue de modèles de grande langue pour répondre à des questions médicales
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - MA-LMM: Mémoire de grand modèle multimodal pour une compréhension vidéo à long terme
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Layoutllm: réglage des instructions de mise en page avec de grands modèles de langue pour la compréhension des documents
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/08 - Ferret-UI: compréhension de l'interface utilisateur mobile à la terre avec LLMS multimodaux
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Évaluation des capacités de raisonnement interventionnel des modèles de grande langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Eagle et Finch: RWKV avec des états à valeur matricielle et une récidive dynamique
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/08 - Codeclm: alignement des modèles de langue avec des données synthétiques sur mesure
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Autocodever: Amélioration du programme autonome
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/07 - TimeGpt dans la prévision de la charge: une grande perspective du modèle de séries chronologiques
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/07 - OpenAI a transcrit plus d'un million d'heures de vidéos YouTube pour former GPT-4
(Nouvelles), - 04/07 - Modèles de génération de vidéos en accéléré comme simulateurs métamorphiques
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/07 - BYTEEDIT: Boost, conforme et accélérez l'édition générative d'image
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - Le vote majoritaire des médecins améliore la pertinence de la dépendance à l'IA en pathologie
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/06 - Diffusion-RWKV: Échelle des architectures de type RWKV pour les modèles de diffusion
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/06 - Datenerf: édition textuelle en profondeur de NERFS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - BeyondScene: Génération de scène centrée sur l'homme à haute résolution avec diffusion pré-entraînée
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - Alignement des modèles de diffusion en optimisant l'utilité humaine
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - Le cas pour développer un modèle de fondation pour la planification des tâches à partir de zéro
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Augmentation des vulnérabilités de LLM à cause du réglage fin et de la quantification
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - SpatiallTracker: suivi des pixels 2D dans l'espace 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - formation de compétences sociales avec des modèles de grandes langues
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Sigma: Réseau Siamois Mamba pour la segmentation sémantique multimodale
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/05 - Splatting gaussien robuste
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Physavatar: Apprendre la physique des avatars 3D habillés des observations visuelles
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - KOALA: CLÉ CLÉ CONDITIONNEMENT CONDITIONNEMENT VIDEO-LLM
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Indice: une évaluation de la compréhension de la langue clinique pour les LLM
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Chinois Tiny LLM: Pré-dresser un modèle de grande langue centré sur le chinois
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Aider les humains dans des comparaisons complexes: comparaison automatisée d'informations à grande échelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - AI incarné avec deux bras: apprentissage zéro, sécurité et modularité
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/04 - Évolution du modèle de langue: une perspective d'apprentissage itérée
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - La visualisation de pensée suscite un raisonnement spatial dans les modèles de grande langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) (twitter), - 04/04 - Non "zéro-shot" sans données exponentielles: la fréquence du concept de pré-formation détermine les performances du modèle multimodal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Évaluation des LLM pour détecter les erreurs dans les réponses LLM
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Évaluation des modèles de langage génératifs dans l'extraction d'informations comme correction de questions subjectives
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Optimisation directe de la NASH: l'enseignement des modèles de langue pour s'auto-imprégner avec les préférences générales
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - CBR-RAG: Raisonnement basé sur les cas pour la récupération de la génération augmentée dans les LLM pour répondre à des questions juridiques
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Capacités des modèles de grande langue dans l'ingénierie du contrôle: une étude de référence sur GPT-4, Claude 3 Opus et Gemini 1.0 Ultra
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - CantalkaboutThis: Alignez les modèles de langue pour rester sur le sujet dans les dialogues
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - AUTOWEBGLM: Bootstrap et renforcez un agent de navigation Web basé sur un modèle en grande langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - TRAPALER LLMS sur un texte compressé neuralement
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Reft: Représentation Finetuning pour les modèles de langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - RED équipe GPT-4V: Le GPT-4V est-il sûr contre les attaques de jailbreak Uni / Multi-modal?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - RALL-E: modélisation robuste du langage des codecs avec une invitation à la chaîne de pensées pour la synthèse de texte à la parole
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - PointInfinity: Résolution Modèles de diffusion ponctuelle invariante
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - MINIGPT4-VIDEO: Avançant des LLM multimodales pour une compréhension vidéo avec des jetons visuels-textuels entrelacés
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Comat: alignement modèle de diffusion de texte à image avec concept d'image à texte correspondant
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - CodeeDitorBench: Évaluation de la capacité d'édition de code des modèles de grande langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - AUTOWEBGLM: Bootstrap et renforcez un agent de navigation Web basé sur un modèle en grande langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03 - Modélisation autorégressive visuelle: génération d'images évolutive via une prédiction à l'échelle à prochaine
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03 - Sur l'évolutivité de la génération de texte à image basée sur la diffusion
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03 - Jailbreaking à plusieurs coups
() - 04/03 - LVLM-INTREPRET: Un outil d'interprétabilité pour les grands modèles de vision
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03 - Modèles linguistiques en tant que compilateurs: la simulation de l'exécution de pseudocode améliore le raisonnement algorithmique dans les modèles de langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03 - InstantStyle: Déjeuner gratuit vers la préservation du style dans la génération de texte à l'image
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03 - Freditor: Édition de NERF haute fidélité et transférable par décomposition en fréquence
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03 - La transtention croisée rend l'inférence lourde dans les modèles de diffusion de texte à image
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03 - ChatGLM-Math: Amélioration de la résolution de problèmes mathématiques dans des modèles de grande langue avec un pipeline d'autocritique
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - Le Royaume-Uni et les États-Unis annoncent le partenariat sur la science de la sécurité de l'IA
(Nouvelles), - 04/02 - Modèles de grande langue en tant que générateurs de domaine de planification
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/02 - Poro 34b et la bénédiction de la multilinalité
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - Octopus V2: modèle de langue sur dispositif pour Super Agent
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - Mélange de dépasse: alloue dynamiquement en calcul dans les modèles de langage basés sur le transformateur
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - LLMS à long contexte lutte avec un long apprentissage dans le contexte
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - LLM-ABR: Concevoir des algorithmes de débit adaptatif via de grands modèles de langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - Les modèles de grandes langues pourraient changer l'avenir des soins de santé comportementaux: une proposition de développement et d'évaluation responsables
() - 04/02 - Rapport technique HyperClova x
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - Cameractrl: Activation du contrôle de la caméra pour la génération de texte à vidéo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - Généralistes du raisonnement LLM avancé avec des arbres de préférence
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Stream of Search (SOS): Apprendre à rechercher dans la langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - LLM en tant que cerveau: une étude du raisonnement stratégique avec des modèles de langue importants
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - L'essor et la montée des modèles de grande langue de l'IA (LLMS)
(Blog), - 04/01 - Streaming de sous-titrage vidéo dense
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Mesurer la similitude du style dans les modèles de diffusion
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Gérer les choses: Amélioration de la cohérence spatiale dans les modèles de texte à image
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Pour les sociétés d'IA gourmandes de données, Internet est trop petit
(Nouvelles), - 04/01 - FlexiDreamer: génération d'image unique à 3D avec flexicubes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - EVAVERS: bibliothèque unifiée et accessible pour une évaluation du modèle de grande langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Optimisation directe des préférences des grands modèles multimodaux de la récompense du modèle de langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - DBRX, pré-formation continue, récompense, inférence plus rapide, et plus encore
(Blog), - 04/01 - Cosmicman: un modèle de fondation de texte à l'image pour l'homme
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Réseau neuronal affirmé par condition pour la génération d'images contrôlés
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - plus gros n'est pas toujours meilleur: les propriétés de mise à l'échelle des modèles de diffusion latente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Les modèles de grande langue sont-ils des chimistes surhumains?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/31 - WAVLLM: Vers un modèle de grande langue robuste et adaptatif
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/31 - fatigué des plugins? Les modèles de grands langues peuvent être des recommandateurs de bout en bout
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/03 - Enquête sur le modèle de grande langue-apprentissage du renforcement amélioré: concept, taxonomie et méthodes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/30 - ST-LLM: Les modèles de grandes langues sont des apprenants temporels efficaces
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 03/30 - Formation au bruit des modèles de langue conscient de la mise en page
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/30 - Magritte: réalisation 3D manipulative et générative de l'image, de la vue et du texte
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 03/30 - Aurora-M: Le premier modèle de langue multilingue open source est enraciné en fonction du décret américain
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Détection de problème insoluble: Évaluation de la fiabilité des modèles de langage de vision
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Transformateur-Lite: Déploiement à haute efficacité de modèles de grandes langues sur les GPU de téléphonie mobile
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Snap-it, Tap-it, Splat-it: Splatting gaussien 3D tactile pour reconstruire les surfaces difficiles
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Royaume: Résolution de référence comme modélisation du langage
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - NVIDIA H200 GPUS Crush MLPerf's LLM Inférence Benchmark
(Nouvelles), - 03/29 - Mambamixer: modèles d'espace d'état sélectif efficaces avec double token et sélection de canaux
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Llava-Gemma: Accélération des modèles de fondation multimodale avec un modèle de langage compact
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Instantsplat: éclaboussures gaussiennes sans vue peu liées à la vue sans vue en 40 secondes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Gecko: intégration de texte polyvalent distillé à partir de modèles de grosses langues
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Dijiang: modèles efficaces de grande langue grâce à la kernélisation compacte
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/29 - DeepMind se développe Safe, une application basée sur l'IA qui peut vérifier les faits LLMS
(Nouvelles), - 03/29 - CTRL-SIM: Agents de conduite réactifs et contrôlables avec apprentissage en renforcement hors ligne
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Sommes-nous sur la bonne voie pour évaluer les grands modèles de langue de vision?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - SDPO: n'utilisez pas vos données en même temps
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - Mesh2nerf: supervision directe du maillage pour la représentation et la génération du champ de radiation neuronale
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - Localisation de la mémorisation des paragraphes dans les modèles de langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - Jamba: un modèle de langue transformateur hybride-mamba
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - GaussianCube: structurer des éclaboussures gaussiennes utilisant un transport optimal pour la modélisation générative 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - Claude 3 dépasse GPT-4 dans le duel des bots AI. Voici comment entrer dans l'action
(Nouvelles), - 03/28 - Annonce de Grok-1.5
(Blog), (démo), - 03/27 - Une voie vers l'autonomie juridique: une approche interopérable et explicable de l'extraction, de la transformation, du chargement et de l'informatique des informations juridiques à l'aide de modèles de langues, de systèmes experts et de réseaux bayésiens
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - Vitar: Transformateur de vision avec n'importe quelle résolution
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - Vers un modèle de langue mondiale-anglais pour les assistants virtuels sur disque
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - TextCraftor: Votre encodeur de texte peut être un contrôleur de qualité d'image
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - Objectdrop: Bootstrap contrefactuels pour l'élimination et l'insertion des objets photoréalistes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - Mini-Gemini: Exploitation du potentiel des modèles de langage de vision multimodalité
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/27 - Factualité longue dans les modèles de grande langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/27 - Lita: Langue Instruction Assistant temporel-localisation
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/27 - GARMENT3DGEN: 3D Stylisation des vêtements et génération de texture
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - Gamba: épouser des éclaboussures gaussiennes avec du mamba pour une reconstruction 3D à vue unique
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - FlexEdit: édition d'image centrée sur l'objet basé sur une diffusion flexible et contrôlable
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - BioMedlm: un modèle de langage de paramètres 2.7b formé sur le texte biomédical
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26 - Magis: Framework multi-agent basé sur LLM pour la résolution du problème GitHub
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26 - L'inefficacité déraisonnable des couches plus profondes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26 - TC4D: Génération de texte à 4D conditionnée par la trajectoire
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26 - OCTREE-GS: Vers le rendu cohérent en temps réel avec les Gaussiens 3D structurés du LOD
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/26 - Présentation de DBRX: un nouveau statut de l'Ord-Art LLM
(Blog), - 03/26 - Rapport technique interlm2
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/26 - Amélioration de la cohérence du texte / image via l'optimisation automatique de l'invite
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26 - Perceptrons multi-couches entièrement fusionnés sur les GPU du centre de données Intel
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/26 - Egolifter: Segmentation 3D du monde ouvert pour la perception égocentrique
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26 - ANIPORTRAIT: Synthèse axée sur l'audio de l'animation de portrait photoréaliste
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/26 - 2d Splatting gaussien pour les champs de rayonnement géométriquement précis
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25 - Vers une évaluation automatique pour les capacités cliniques de LLMS: métrique, données et algorithme
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25 - REPARAGEnt: un agent autonome basé sur LLM pour la réparation du programme
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25 - RL pour les modèles de cohérence: génération de texte guidée par récompense plus rapide
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/25 - VP3d: déchaîner une invite visuelle 2D pour la génération de texte à 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25 - Trip: apprentissage résiduel temporel avec bruit d'image avant pour les modèles de diffusion d'image à vidéo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25 - SDXS: Modèles de diffusion latente en une étape en temps réel avec conditions d'image
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/25 - Système d'exploitation d'agent LLM
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/25 - Flashface: Personnalisation de l'image humaine avec préservation d'identité haute fidélité
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25 - DreamPolisher: Vers la génération de texte à 3D de haute qualité via une diffusion géométrique
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/25 - Soyez vous-même: l'attention délimitée pour la génération de texte à l'image multi-sujets
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/23 - Lorsque la génération de code basée sur LLM rencontre le processus de développement logiciel
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/22 - THESTATION: GÉNÉRATION ACTIONNÉE 3D AWARE 3D de quelques exemples
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/22 - SIMBA: Architecture simplifiée Mamba pour la vision et les séries chronologiques multivariées
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/22 - LLM2LLM: Boosting LLMS avec une nouvelle amélioration des données itératives
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/22 - Latte3d: synthèse de texte amorti à grande échelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/22 - InternvideO2: Échelle des modèles de fondation vidéo pour la compréhension vidéo multimodale
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/22 - Suivant: Évaluation et enseignement des modèles de récupération d'informations pour suivre les instructions
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/22 - Dragapart: apprendre un mouvement de niveau partielle avant pour les objets articulés
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/22 - Les modèles de grande langue peuvent-ils explorer le contexte?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/22 - Allands: Demandez-moi n'importe quoi sur les commentaires textuels à grande échelle via des modèles de grande langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 03/21 - Peergpt: sonder les rôles des agents de pairs basés sur LLM en tant que modérateurs d'équipe et participants à l'apprentissage collaboratif des enfants
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - Stylecinegan: Génération de cinémagraphes de paysage utilisant un style de style pré-formé
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/21 - StreamingT2V: Génération vidéo longue cohérente, dynamique et extensible à partir du texte
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/21 - Renoise: réelle inversion de l'image par le biais de noing itératif
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - Recours pour la remise en état: discuter avec des modèles de langage génératif
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - Rakutenai-7b: étendre les modèles de grande langue pour les japonais
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - MYVLM: Personnalisation des VLM pour les requêtes spécifiques à l'utilisateur
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - Mathverse: Votre LLM multi-modal voit-il vraiment les diagrammes des problèmes mathématiques visuels?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - GRM: grand modèle de reconstruction gaussienne pour une reconstruction et une génération 3D efficaces
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/21 - L'Assemblée générale adopte la résolution historique sur l'intelligence artificielle
(Nouvelles), - 03/21 - Flatement gaussien: champs de radiance complexes modifiables avec rendu en temps réel
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - Exploratif entre le temps et l'espace
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - DreamReward: Génération de texte à 3D avec préférence humaine
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - COBRA: Extension du Mamba à un modèle de langue multimodale en grand pour une inférence efficace
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/21 - Champ: animation d'image humaine contrôlable et cohérente avec guidage paramétrique 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/21 - Anyv2v: Un framework plug-and-play pour toutes les tâches d'édition vidéo à vidéo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Mapping LLM Security Landscapes: une proposition complète d'évaluation des risques des parties prenantes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Zigma: Modèle de diffusion Zigzag Mamba
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - VSTAR: soins infirmiers temporels génératifs pour synthèse vidéo plus longue dynamique
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Récompense: évaluation des modèles de récompense pour la modélisation du langage
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - Formation inversée pour allaiter la malédiction d'inversion
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Radsplat: éclaboussures gaussiennes informées de la radiance pour un rendu robuste en temps réel avec plus de 900 ips
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Mora: Activation de la génération de vidéos généraliste via un cadre multi-agent
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - Llamafactory: un réglage d'adaptation efficace unifié de plus de 100 modèles de langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - Idadapter: Apprendre des fonctionnalités mixtes pour la personnalisation sans réglage des modèles de texte à image
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Hyperllava: réglage dynamique des experts visuels et linguistiques pour les modèles de langage multimodal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - Évaluation des modèles frontaliers pour les capacités dangereuses
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - DepthFM: Estimation de la profondeur monoculaire rapide avec correspondance de débit
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Compress3d: un espace latent compressé pour la génération 3D à partir d'une seule image
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Be-Your-Outpainter: maîtrise la surface vidéo grâce à une adaptation spécifique à l'entrée
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Quand n'avons-nous pas besoin de modèles de vision plus importants?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - VID2ROBOT: Apprentissage politique conditionné par vidéo de bout en bout avec transformateurs transversaux
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Vers un modèle de fondation à usage général pour la pathologie informatique
() - 03/19 - TexDreamer: Vers une génération de texture humaine à haute fidélité à zéro
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Scenescript: Reconstruire les scènes avec un modèle de langage structuré autorégressif
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Mplug-docowl 1.5: Apprentissage de la structure unifiée pour la compréhension du document sans OCR
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Magic Fixup: rationalisation de la modification photo en regardant des vidéos dynamiques
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - LLMLINGUA-2: Distillation des données pour une compression rapide de tâche efficace et fidèle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - GVGEN: génération de texte à 3D avec représentation volumétrique
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - GaussianFlow: Splatting Gaussien Dynamics pour la création de contenu 4D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Fresco: Correspondance spatiale-temporelle pour la traduction vidéo à tirs zéro
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Fouriscale: une perspective de fréquence sur la synthèse d'image haute résolution sans formation
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Optimisation évolutive des recettes de fusion de modèles
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), ([: octocat:] (https : //github.com/ sakanaai / évolutionnaire-model-mege)! [Github Repo Stars] (https://img.shields.io/github/stars/ sakanaai / évolutionnaire-model-mege? style = social))) - 03/19 - Comboverse: Création des actifs 3D de composition en utilisant un guidage de diffusion spatialement conscient
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Raisonnement basé sur les graphiques: transfert de capacités de LLMS à VLMS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - MM1 d'Apple: un modèle multimodal grand langage capable d'interpréter à la fois les images et les données de texte
(Nouvelles), - 03/19 - Animatediff-Lightning: Distillation de diffusion du modèle croisé
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Agent-FLAN: Concevoir des données et des méthodes de réglage efficace des agents pour les modèles de grande langue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Un modèle de fondation en langue visuelle pour la pathologie informatique
(), (✳️) - 03/19 - Agents d'IA caractéristiques via des modèles de grands langues
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), (! [Github Repo Stars] ( https://img.shields.io/github/stars/nuaa-nlp/character100? style = social))) - 03/18 - Jusqu'où sommes-nous sur la prise de décision des LLM? Évaluation de la capacité de jeu de LLMS dans des environnements multi-agents
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 - VIDECEAGENT: Un agent multimodal auprès de la mémoire pour la compréhension vidéo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - VFUSION3D: Apprentissage des modèles génératifs 3D évolutifs à partir de modèles de diffusion vidéo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - TNT-llm: l'exploration de texte à grande échelle avec des modèles de grosses langues
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - SV3D: nouvelle synthèse multi-visualités et génération 3D à partir d'une seule image utilisant la diffusion vidéo latente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - Routerbench: une référence pour le système de routage multi-llm
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), (ss) - 03/18 - Meta-compting pour automatiser la reconnaissance visuelle zéro-shot avec LLMS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 - LN3DIFF: champs de neurones latentes évolutifs diffusion pour génération 3D rapide
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - LLAVA-UHD: un LMM percevant tout rapport d'aspect et images à haute résolution
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 - Larimar: Modèles de grande langue avec contrôle de la mémoire épisodique
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - Infinite-ID: Personnalisation préservée de l'identité via le paradigme de découplage ID-Sémantique
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - GPT-4 en tant qu'évaluateur: Évaluation des modèles de grandes langues sur la gestion des ravageurs en agriculture
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Compiler generated feedback for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - PhD: A Prompted Visual Hallucination Evaluation Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/16 - VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/16 - Do Large Language Models understand Medical Codes?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - VideoAgent: Long-form Video Understanding with Large Language Model as Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Trusting the Search: Unraveling Human Trust in Health Information from Google and ChatGPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - PERL: Parameter Efficient Reinforcement Learning from Human Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - MusicHiFi: Fast High-Fidelity Stereo Vocoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - LightIt: Illumination Modeling and Control for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - DiPaCo: Distributed Path Composition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - WavCraft: Audio Editing and Generation with Natural Language Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Editing via Factorized Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Scaling Instructable Agents Across Many Simulated Worlds
(twitter), (Blog), - 03/14 - Recurrent Drafter for Fast Speculative Decoding in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - LocalMamba: Visual State Space Model with Windowed Selective Scan
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Helpful or Harmful? Exploring the Efficacy of Large Language Models for Online Grooming Prevention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - GPT on a Quantum Computer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/14 - Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - GiT: Towards Generalist Vision Transformer through Universal Language Interface
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Exploring the Capabilities and Limitations of Large Language Models in the Electric Energy Sector
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - 3D-VLA: A 3D Vision-Language-Action Generative World Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Scaling Instructable Agents Across Many Simulated Worlds
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/13 - VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - The Human Factor in Detecting Errors of Large Language Models: A Systematic Literature Review and Future Research Directions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Simple and Scalable Strategies to Continually Pre-train Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Scaling Up Dynamic Human-Scene Interaction Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language-based game theory in the age of artificial intelligence
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language models scale reliably with over-training and on downstream tasks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Knowledge Conflicts for LLMs: A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Gemma: Open Models Based on Gemini Research and Technology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Cultural evolution in populations of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Bugs in Large Language Models Generated Code: An Empirical Study
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Synth^2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - MoAI: Mixture of All Intelligence for Large Language and Vision Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Learning Generalizable Feature Fields for Mobile Manipulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - DragAnything: Motion Control for Anything using Entity Representation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Chronos: Learning the Language of Time Series
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Transparent AI Disclosure Obligations: Who, What, When, Where, Why, How
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - HILL: A Hallucination Identifier for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - FAX: Scalable and Differentiable Federated Primitives in JAX
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FashionReGen: LLM-Empowered Fashion Report Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - VideoMamba: State Space Model for Efficient Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - V3D: Video Diffusion Models are Effective 3D Generators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Stealing Part of a Production Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - Multistep Consistency Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FaceChain-SuDe: Building Derived Class to Inherit Category Attributes for One-shot Subject-Driven Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - Chain-of-table: Evolving tables in the reasoning chain for table understanding (Blog),
- 03/11 - An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/10 - VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/09 - Algorithmic progress in language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - On Protecting the Data Privacy of Large Language Models (LLMs): A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/08 - VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - DeepSeek-VL: Towards Real-World Vision-Language Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/08 - CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Now available on Poe: Claude 3 (Demo),
- 03/08 - Google - Health-specific embedding tools for dermatology and pathology (Blog),
- 03/07 - Yi: Open Foundation Models by 01.AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Teaching Large Language Models to Reason with Reinforcement Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - StableDrag: Stable Dragging for Point-based Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Pix2Gif: Motion-Guided Diffusion for GIF Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Meet 'Liberated Qwen', an uncensored LLM that strictly adheres to system prompts (News),
- 03/07 - LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - KAIST develops next-generation ultra-low power LLM accelerator (News),
- 03/07 - Inflection-2.5: meet the world's best personal AI (News),
- 03/07 - How Far Are We from Intelligent Visual Deductive Reasoning?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Evaluating LLM models at scale (Blog),
- 03/07 - Common 7B Language Models Already Possess Strong Math Capabilities
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - SaulLM-7B: A pioneering Large Language Model for Law
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - NY hospital exec: Multimodal LLM assistants will create a “paradigm shift” in patient care (News),
- 03/06 - Learning to Decode Collaboratively with Multiple Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - Enhancing Vision-Language Pre-training with Rich Supervisions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Backtracing: Retrieving the Cause of the Query
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - AI Prompt Engineering Is Dead (News),
- 03/06 - 3D Diffusion Policy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/05 - OpenAI and Elon Musk (Blog),
- 03/05 - Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/05 - WikiTableEdit: A Benchmark for Table Editing by Natural Language Instruction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Revisiting Meta-evaluation for Grammatical Error Correction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - MathScale: Scaling Instruction Tuning for Mathematical Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Interactive Continual Learning: Fast and Slow Thinking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - In Search of Truth: An Interrogation Approach to Hallucination Detection (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ImgTrojan: Jailbreaking Vision-Language Models with ONE Image (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Generative Software Engineering (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Exploring the Limitations of Large Language Models in Compositional Relation Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Design2Code: How Far Are We From Automating Front-End Engineering? (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 3/5 - OpenAI - ChatGPT can now read responses to you. (gazouillement,
- 03/04 - The Claude 3 Model Family: Opus, Sonnet, Haiku
() (twitter), , (✳️) - 03/04 - Wukong: Towards a Scaling Law for Large-Scale Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - Large language models surpass human experts in predicting neuroscience results
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/04 - NoteLLM: A Retrievable Large Language Model for Note Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - MagicClay: Sculpting Meshes With Generative Neural Fields (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/04 - Enhancing LLM Safety via Constrained Direct Preference Optimization (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - Balancing Enhancement, Harmlessness, and General Capabilities: Enhancing Conversational LLMs with Direct RLHF (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 3/4 - ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - TripoSR: Fast 3D Object Reconstruction from a Single Image (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - RT-H: Action Hierarchies Using Language (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - Build AI for a Better Future (twitter), (News),
- 3/4 - AtomoVideo: High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 03/03 - Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research (Blog),
- 3/3 - Nvidia CEO Jensen Huang says AI could pass most human tests in 5 years (News
- 3/3 - MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - Could this be bigger than OpenAI? Microsoft invests billions in French startup — Mistral AI is a multilingual maestro that's almost as good as ChatGPT 4 (News),
- 3/3 - 3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/2 - Nvidia CEO says AI could pass human tests in five years (News
- 3/1 - Elon Musk sues OpenAI and CEO Sam Altman over contract breach (News)
- 3.1 - AtP*: An efficient and scalable method for localizing LLM behaviour to components (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - VisionLLaMA: A Unified LLaMA Interface for Vision Tasks (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Learning and Leveraging World Models in Visual Representation Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Resonance RoPE: Improving Context Length Generalization of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/29 - OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/29 - Retrieval-Augmented Generation for AI-Generated Content: A Survey (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2.29 - DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Humanoid Locomotion as Next Token Prediction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - StarCoder 2 and The Stack v2: The Next Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Trajectory Consistency Distillation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - Beyond Language Models: Byte Models are Digital World Simulators (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Syntactic Ghost: An Imperceptible General-purpose Backdoor Attacks on Pre-trained Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - ViewFusion: Towards Multi-View Consistency via Interpolated Denoising (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - MOSAIC: A Modular System for Assistive and Interactive Cooking (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 02/28 - Automatic Creative Selection with Cross-Modal Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 2.28 - Priority Sampling of Large Language Models for Compilers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Simple linear attention language models balance the recall-throughput tradeoff (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.28 - Approaching Human-Level Forecasting with Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Datasets for Large Language Models: A Comprehensive Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.28 - A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - A High Level Guide to LLM Evaluation Metrics (Blog),
- 2/27 - Users Say Microsoft's AI Has Alternate Personality as Godlike AGI That Demands to Be Worshipped (News)
- 2/27 - Google DeepMind CEO on AGI, OpenAI and Beyond – MWC 2024 (News)
- 2.27 - Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Towards Optimal Learning of Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Evaluating Very Long-Term Conversational Memory of LLM Agents (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Training-Free Long-Context Scaling of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Model (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora Generates Videos with Stunning Geometrical Consistency (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Video as the New Language for Real-World Decision Making (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - On the Societal Impact of Open Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/26 - Set the Clock: Temporal Alignment of Pretrained Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2/26 - DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models (), ()(?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/26 - Mistral Large is our flagship model, with top-tier reasoning capacities (News)
- 2.26 - Disentangled 3D Scene Generation with Layout Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Multi-LoRA Composition for Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.26 - Do Large Language Models Latently Perform Multi-Hop Reasoning? (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Nemotron-4 15B Technical Report (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - StructLM: Towards Building Generalist Models for Structured Knowledge Grounding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Towards Open-ended Visual Quality Comparison (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.25 - ChatMusician: Understanding and Generating Music Intrinsically with LLM (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.25 - FuseChat: Knowledge Fusion of Chat Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/24 - Divide-or-Conquer? Which Part Should You Distill Your LLM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/24 - Perplexity.ai Revamps Google SEO Model For LLM Era (News)
- 02/24 - Data Interpreter: An LLM Agent For Data Science
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2.24 - Empowering Large Language Model Agents through Action Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Seamless Human Motion Composition with Blended Positional Encodings (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Genie: Generative Interactive Environments (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - GPTVQ: The Blessing of Dimensionality for LLM Quantization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.22 - CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️), ()
- 02/22 - Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 2.22 - Divide-or-Conquer? Which Part Should You Distill Your LLM? (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - Watermarking Makes Language Models Radioactive (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - AutoPrompt - prompt optimization framework ()
- 2.22 - Announcing Stable Diffusion 3 (tweet), (blog)
- 2.22 - DualFocus: Integrating Macro and Micro Perspectives in Multi-modal Large Language Models (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Vision-Language Navigation with Embodied Intelligence: A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - PALO: A Polyglot Large Multimodal Model for 5B People (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion (), (), ([:paperclip:](https://arxiv.org/pdf/2402.148


