local chat
v0.11.0
Discutez avec des modèles de langage génératifs localement sur votre ordinateur sans aucune configuration. LocalChat est un chat d'IA local simple, facile à configurer et Open Source construit sur lama.cpp. Il ne nécessite aucune connaissance technique et permet aux utilisateurs d’expérimenter un comportement de type ChatGPT sur leurs propres machines – entièrement conforme au RGPD et sans crainte de fuite accidentelle d’informations. Téléchargez LocalChat pour macOS, Windows ou Linux ici.
Table des matières
Aperçu | Justification | Configuration système requise | Démarrage rapide | Documentation
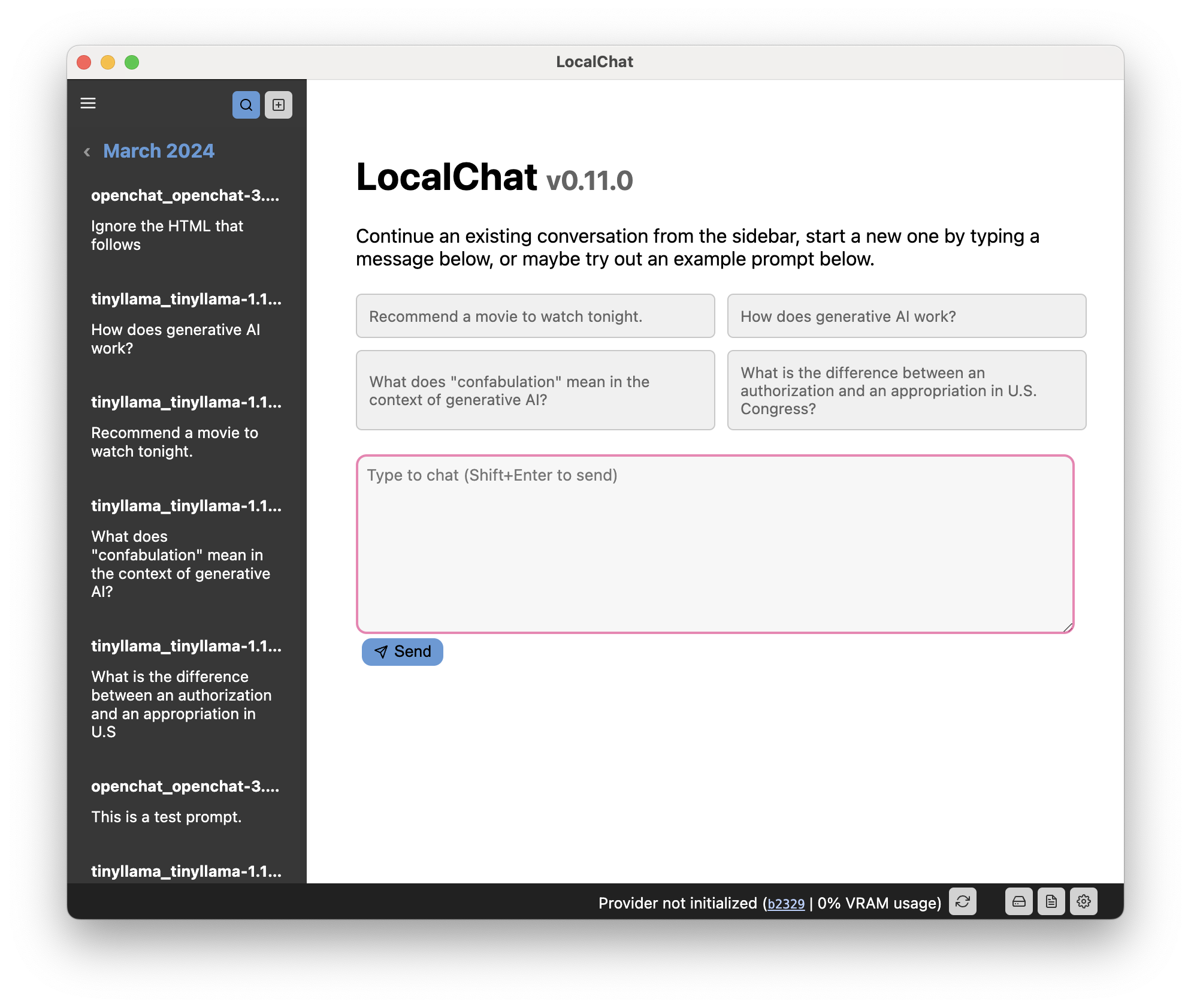
LocalChat fournit une interface de type chat pour interagir avec les grands modèles linguistiques (LLM) génératifs. Cela ressemble à n’importe quelle conversation de chat, mais se déroule localement sur votre ordinateur. Aucune donnée n'est jamais transmise à un serveur cloud.
Il existe déjà plusieurs modèles de langage génératif extrêmement performants qui ressemblent presque à ChatGPT. La principale différence est que ces modèles fonctionnent localement et sont ouverts.
Important
Comme vous le savez probablement déjà, discuter avec un LLM peut sembler très naturel, mais les modèles restent probabilistes : ils généreront le prochain mot probable en fonction du contenu de l'invite. Les LLM n'ont aucune notion du temps, de la causalité, du contexte et de ce que les linguistes appellent la pragmatique. Ainsi, ils ont tendance à inventer des événements qui ne se sont jamais produits, à mélanger des faits provenant d’événements totalement différents ou à raconter des mensonges directs (appelés « hallucinations »). Il en va de même pour le code ou les calculs que ces modèles peuvent produire. Ceci étant dit :
Soyez prudent et utilisez ce modèle à vos propres risques. Gardez à l’esprit qu’il s’agit d’un jouet et non de quelque chose de fiable.
Lorsque ChatGPT a été lancé en novembre 2022, j’étais extrêmement enthousiaste – mais en même temps également prudent. Même si j'ai été très impressionné par les capacités de GPT-3, j'étais douloureusement conscient du fait que le modèle était propriétaire et que, même s'il ne l'était pas, il serait impossible de l'exécuter localement. En tant que citoyen européen soucieux de sa vie privée, je n'aime pas l'idée de dépendre d'une société multimilliardaire qui peut couper l'accès à tout moment.
Pour cette raison, je ne pouvais pas vraiment jouer avec GPT et j'ai décidé d'attendre l'inévitable : le développement d'outils plus petits et meilleurs. À l'heure actuelle, il existe plusieurs modèles qui cochent toutes les cases : ils fonctionnent localement et ressemblent à ChatGPT. Avec la quantification (qui réduit fondamentalement la résolution avec quelques pertes de qualité), ils peuvent même être exécutés sur du matériel plus ancien.
Cependant, si vous n'avez aucune expérience avec les LLM, il sera difficile de les exécuter .
La raison pour laquelle cette application existe est (a) je voulais l'implémenter moi-même pour voir comment elle fonctionne de manière ergonomique, et (b) je voulais fournir une couche très simple pour interagir avec ces choses sans avoir à vous soucier de la configuration de PyTorch et Transformateurs localement.
Il vous suffit d'installer l'application, de télécharger un modèle et c'est parti.
Cette application nécessite un ordinateur moyennement récent pour être exécutée. Cependant, cette application dépend des LLM, notoirement gourmands en énergie. Par conséquent, votre matériel informatique dictera les modèles que vous pourrez exécuter.
Les modèles de taille "normale" auront probablement besoin d'une carte graphique dédiée avec entre 6 et 18 Go de mémoire vidéo, à moins que vous ne soyez prêt à attendre plus d'une seconde par mot.
De nos jours, de nombreux modèles se présentent sous une forme quantifiée, ce qui rend les modèles plus grands également disponibles pour du matériel plus ancien ou moins puissant. La quantification réduit parfois considérablement les exigences du système, même pour des modèles trop grands, sans trop de pertes de qualité (mais votre kilométrage peut varier d'un modèle à l'autre).
Important
En tant que modèle de langage volumineux, la génération de réponses prendra un peu de temps. Donc, surtout si vous n'avez pas de GPU dédié sur votre ordinateur, soyez patient ou essayez un modèle plus petit.
Conseil
Vous pouvez trouver la documentation complète sur le site Web de l'application.
L'interface utilisateur est divisée en trois composants principaux :
Ce code est sous licence GNU GPL 3.0. En savoir plus dans le fichier LICENSE.


