LaTeX OCR
1.0.0
Le but de ce projet est de créer un système basé sur l'apprentissage qui prend une image d'une formule mathématique et renvoie le code LaTeX correspondant.
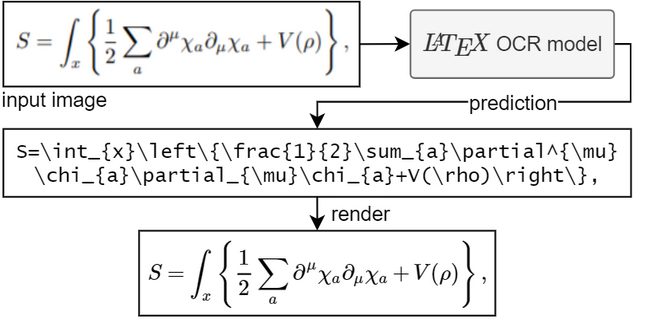
Pour exécuter le modèle, vous avez besoin de Python 3.7+
Si PyTorch n'est pas installé. Suivez leurs instructions ici.
Installez le package pix2tex :
pip install "pix2tex[gui]"
Les modèles de points de contrôle seront téléchargés automatiquement.
Il existe trois façons d'obtenir une prédiction à partir d'une image.
Vous pouvez utiliser l'outil de ligne de commande en appelant pix2tex . Ici, vous pouvez analyser les images déjà existantes du disque et les images de votre presse-papiers.
Grâce à @katie-lim, vous pouvez utiliser une interface utilisateur agréable comme moyen rapide d'obtenir la prédiction du modèle. Appelez simplement l'interface graphique avec latexocr . À partir de là, vous pouvez prendre une capture d'écran et le code latex prédit est rendu à l'aide de MathJax et copié dans votre presse-papiers.
Sous Linux, il est possible d'utiliser l'interface graphique avec gnome-screenshot (qui prend en charge plusieurs moniteurs) si gnome-screenshot a été installé au préalable. Pour Wayland, grim et slurp seront utilisés lorsqu'ils seront tous deux disponibles. Notez que gnome-screenshot n'est pas compatible avec les compositeurs Wayland basés sur wlroots. Étant donné que gnome-screenshot sera préféré lorsqu'il est disponible, vous devrez peut-être définir la variable d'environnement SCREENSHOT_TOOL sur grim dans ce cas (les autres valeurs disponibles sont gnome-screenshot et pil ).
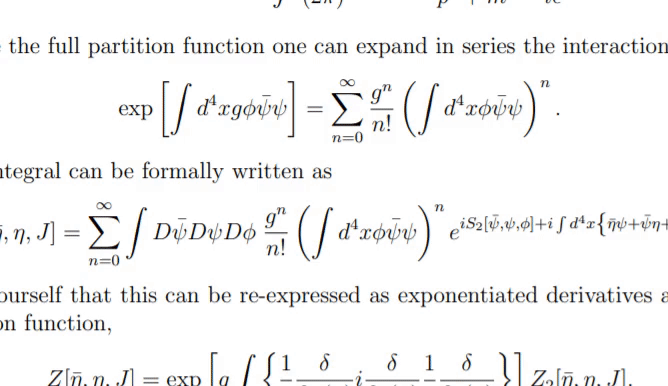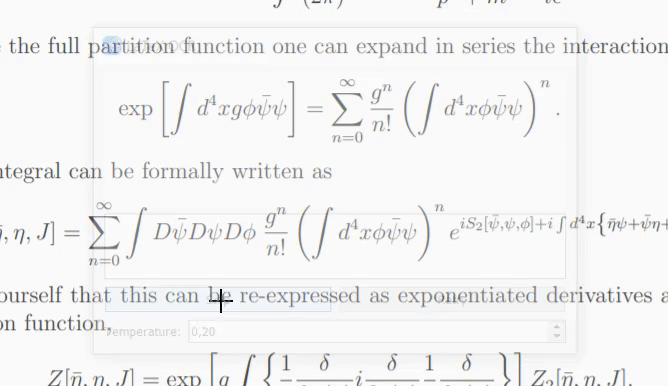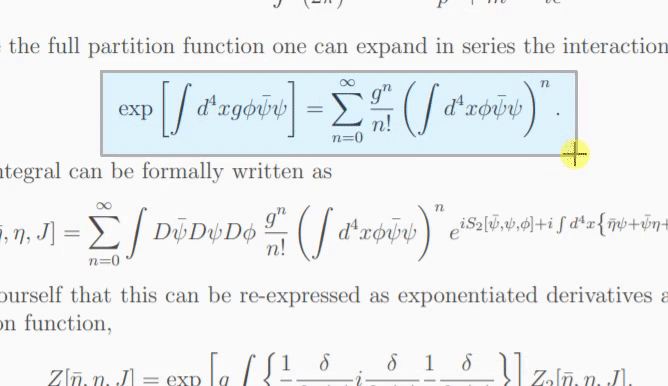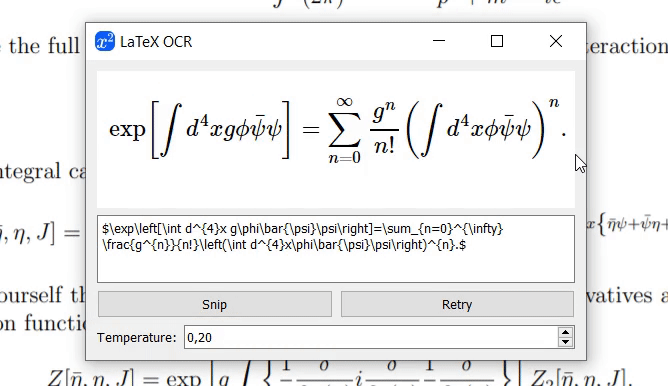
Si le modèle n'est pas sûr du contenu de l'image, il peut générer une prédiction différente à chaque fois que vous cliquez sur « Réessayer ». Avec le paramètre temperature , vous pouvez contrôler ce comportement (une basse température produira le même résultat).
Vous pouvez utiliser une API. Cela a des dépendances supplémentaires. Installez via pip install -U "pix2tex[api]" et exécutez
python -m pix2tex.api.run
pour démarrer une démo Streamlit qui se connecte à l'API sur le port 8502. Il existe également une image Docker disponible pour l'API : https://hub.docker.com/r/lukasblecher/pix2tex
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:api
Pour exécuter également la démo simplifiée
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
et accédez à http://localhost:8501/
Utiliser depuis Python
à partir de PIL import Imagefrom pix2tex.cli import LatexOCRimg = Image.open('path/to/image.png')model = LatexOCR()print(model(img))Le modèle fonctionne mieux avec des images de plus petite résolution. C'est pourquoi j'ai ajouté une étape de prétraitement où un autre réseau de neurones prédit la résolution optimale de l'image d'entrée. Ce modèle redimensionnera automatiquement l'image personnalisée pour ressembler au mieux aux données d'entraînement et augmentera ainsi les performances des images trouvées dans la nature. Pourtant, il n'est pas parfait et pourrait ne pas être en mesure de gérer des images volumineuses de manière optimale, alors ne zoomez pas complètement avant de prendre une photo.
Vérifiez toujours soigneusement le résultat. Vous pouvez essayer de refaire la prédiction avec une autre résolution si la réponse était fausse.
Vous souhaitez utiliser le forfait ?
J'essaie de compiler une documentation en ce moment.
Visitez ici : https://pix2tex.readthedocs.io/
Installez quelques dépendances pip install "pix2tex[train]" .
Nous devons d’abord combiner les images avec leurs étiquettes de vérité terrain. J'ai écrit une classe d'ensemble de données (qui doit encore être améliorée) qui enregistre les chemins relatifs vers les images avec le code LaTeX avec lequel elles ont été rendues. Pour générer le fichier pickle de l'ensemble de données, exécutez
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
Pour utiliser votre propre tokenizer, passez-le via --tokenizer (voir ci-dessous).
Vous pouvez également trouver mes données d'entraînement générées sur Google Drive (formulae.zip - images, math.txt - étiquettes). Répétez l’étape pour les données de validation et de test. Tous utilisent le même fichier texte d'étiquette.
Modifiez l'entrée data (et valdata ) dans le fichier de configuration dans le fichier .pkl nouvellement généré. Modifiez les autres hyperparamètres si vous le souhaitez. Voir pix2tex/model/settings/config.yaml pour un modèle.
Passons maintenant à l'entraînement proprement dit
python -m pix2tex.train --config path_to_config_file
Si vous souhaitez utiliser vos propres données, vous pourriez être intéressé par la création de votre propre tokenizer avec
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
N'oubliez pas de mettre à jour le chemin d'accès au tokenizer dans le fichier de configuration et de définir num_tokens sur la taille de votre vocabulaire.
Le modèle se compose d'un encodeur ViT [1] avec une dorsale ResNet et d'un décodeur Transformer [2].
| Score BLEU | distance d'édition normée | précision du jeton |
|---|---|---|
| 0,88 | 0,10 | 0,60 |
Nous avons besoin de données appariées pour que le réseau apprenne. Heureusement, il existe beaucoup de code LaTeX sur Internet, par exemple Wikipédia, arXiv. Nous utilisons également les formules de l'ensemble de données im2latex-100k [3]. Tout cela peut être trouvé ici
Afin de restituer les mathématiques dans de nombreuses polices différentes, nous utilisons XeLaTeX, générons un PDF et enfin le convertissons en PNG. Pour la dernière étape, nous devons utiliser des outils tiers :
XeLaTeX
ImageMagick avec Ghostscript. (pour convertir un pdf en png)
Node.js pour exécuter KaTeX (pour normaliser le code Latex)
Python 3.7+ et dépendances (spécifiées dans setup.py )
Mathématiques latines modernes, GFSNeohellenicMath.otf, Asana Math, XITS Math, Cambria Math
ajouter plus de mesures d'évaluation
créer une interface graphique
ajouter une recherche de faisceau
prendre en charge les formules manuscrites (un peu fait, voir le cahier de formation colab)
réduire la taille du modèle (distillation)
trouver les hyperparamètres optimaux
modifier la structure du modèle
corriger le grattage de données et récupérer plus de données
tracer le modèle (#2)
Les contributions de toute nature sont les bienvenues.
Code extrait et modifié de lucidrains, rwightman, im2markup, arxiv_leaks, pkra : Mathjax, harupy : outil de capture
[1] Une image vaut 16x16 mots
[2] L'attention est tout ce dont vous avez besoin
[3] Génération d'image à balisage avec une attention grossière à fine


