segment anything
1.0.0
Veuillez consulter notre nouvelle version sur Segment Anything Model 2 (SAM 2) .
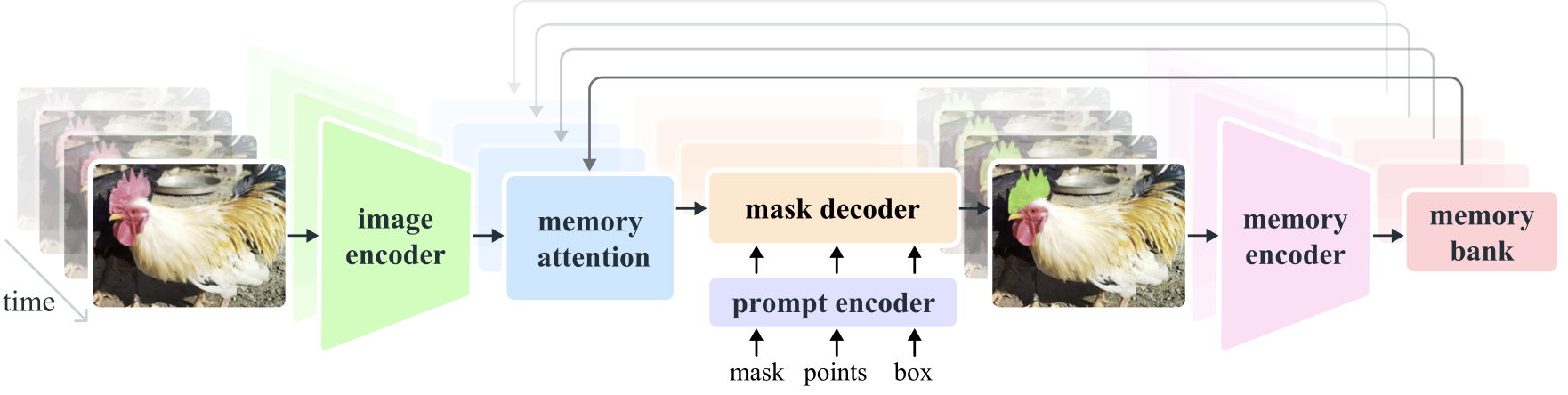
Segment Anything Model 2 (SAM 2) est un modèle de base permettant de résoudre la segmentation visuelle rapide des images et des vidéos. Nous étendons SAM à la vidéo en considérant les images comme une vidéo avec une seule image. La conception du modèle est une architecture de transformateur simple avec une mémoire de streaming pour le traitement vidéo en temps réel. Nous construisons un moteur de données de modèle dans la boucle, qui améliore le modèle et les données via l'interaction de l'utilisateur, pour collecter notre ensemble de données SA-V , le plus grand ensemble de données de segmentation vidéo à ce jour. SAM 2 formé sur nos données offre de solides performances dans un large éventail de tâches et de domaines visuels.
Recherche sur la méta-IA, FAIR
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick
[ Paper ] [ Project ] [ Demo ] [ Dataset ] [ Blog ] [ BibTeX ]
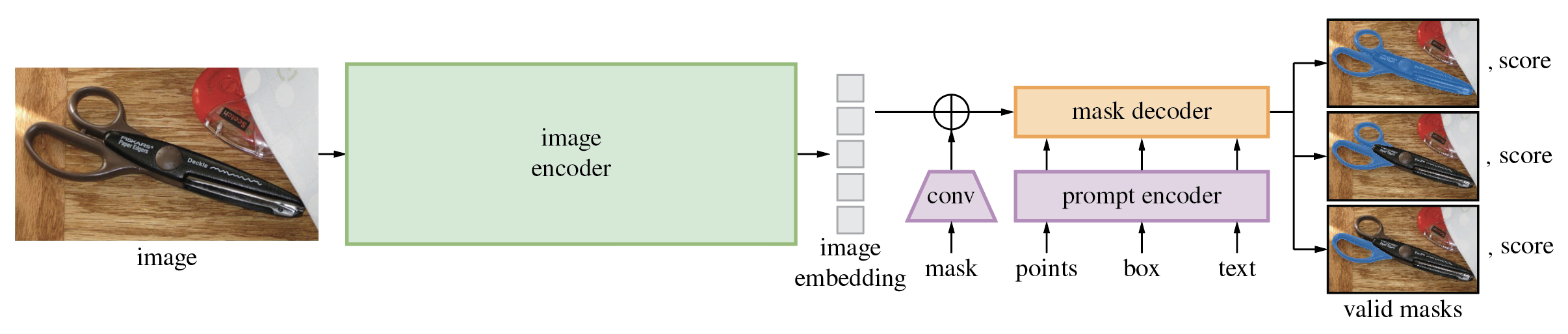
Le Segment Anything Model (SAM) produit des masques d'objets de haute qualité à partir d'invites de saisie telles que des points ou des cases, et il peut être utilisé pour générer des masques pour tous les objets d'une image. Il a été formé sur un ensemble de données de 11 millions d'images et 1,1 milliard de masques, et présente de solides performances sans tir sur une variété de tâches de segmentation.


Le code nécessite python>=3.8 , ainsi que pytorch>=1.7 et torchvision>=0.8 . Veuillez suivre les instructions ici pour installer les dépendances PyTorch et TorchVision. L'installation de PyTorch et TorchVision avec la prise en charge de CUDA est fortement recommandée.
Installer le segment n'importe quoi :
pip install git+https://github.com/facebookresearch/segment-anything.git
ou clonez le référentiel localement et installez-le avec
git clone [email protected]:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
Les dépendances facultatives suivantes sont nécessaires pour le post-traitement des masques, l'enregistrement des masques au format COCO, les exemples de notebooks et l'exportation du modèle au format ONNX. jupyter est également requis pour exécuter les exemples de notebooks.
pip install opencv-python pycocotools matplotlib onnxruntime onnx
Téléchargez d’abord un modèle de point de contrôle. Ensuite, le modèle peut être utilisé en quelques lignes seulement pour obtenir des masques à partir d'une invite donnée :
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
ou générer des masques pour une image entière :
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
De plus, des masques peuvent être générés pour les images à partir de la ligne de commande :
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
Consultez les exemples de cahiers sur l'utilisation de SAM avec des invites et la génération automatique de masques pour plus de détails.


Le décodeur de masque léger de SAM peut être exporté au format ONNX afin de pouvoir être exécuté dans n'importe quel environnement prenant en charge le runtime ONNX, comme dans un navigateur, comme présenté dans la démo. Exportez le modèle avec
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
Consultez l'exemple de bloc-notes pour plus de détails sur la façon de combiner le prétraitement d'image via le squelette de SAM avec la prédiction de masque à l'aide du modèle ONNX. Il est recommandé d'utiliser la dernière version stable de PyTorch pour l'exportation ONNX.
Le dossier demo/ contient une simple application React d'une page qui montre comment exécuter la prédiction de masque avec le modèle ONNX exporté dans un navigateur Web avec multithreading. Veuillez consulter demo/README.md pour plus de détails.
Trois versions du modèle sont disponibles avec différentes tailles de colonne vertébrale. Ces modèles peuvent être instanciés en exécutant
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
Cliquez sur les liens ci-dessous pour télécharger le point de contrôle pour le type de modèle correspondant.
default ou vit_h : modèle ViT-H SAM.vit_l : modèle ViT-L SAM.vit_b : modèle ViT-B SAM. Voir ici pour un aperçu de l'ensemble de données. L'ensemble de données peut être téléchargé ici. En téléchargeant les ensembles de données, vous reconnaissez avoir lu et accepté les termes de la licence de recherche sur les ensembles de données SA-1B.
Nous enregistrons les masques par image sous forme de fichier json. Il peut être chargé sous forme de dictionnaire en python au format ci-dessous.
{
"image" : image_info ,
"annotations" : [ annotation ],
}
image_info {
"image_id" : int , # Image id
"width" : int , # Image width
"height" : int , # Image height
"file_name" : str , # Image filename
}
annotation {
"id" : int , # Annotation id
"segmentation" : dict , # Mask saved in COCO RLE format.
"bbox" : [ x , y , w , h ], # The box around the mask, in XYWH format
"area" : int , # The area in pixels of the mask
"predicted_iou" : float , # The model's own prediction of the mask's quality
"stability_score" : float , # A measure of the mask's quality
"crop_box" : [ x , y , w , h ], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[ x , y ]], # The point coordinates input to the model to generate the mask
}Les identifiants des images peuvent être trouvés dans sa_images_ids.txt qui peut également être téléchargé à l'aide du lien ci-dessus.
Pour décoder un masque au format COCO RLE en binaire :
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
Voir ici pour plus d'instructions sur la manipulation des masques stockés au format RLE.
Le modèle est sous licence Apache 2.0.
Voir contribution et code de conduite.
Le projet Segment Anything a été rendu possible grâce à l'aide de nombreux contributeurs (par ordre alphabétique) :
Aaron Adcock, Vaibhav Aggarwal, Morteza Behrooz, Cheng-Yang Fu, Ashley Gabriel, Ahuva Goldstand, Allen Goodman, Sumanth Gurram, Jiabo Hu, Somya Jain, Devansh Kukreja, Robert Kuo, Joshua Lane, Yanghao Li, Lilian Luong, Jitendra Malik, Mallika Malhotra, William Ngan, Omkar Parkhi, Nikhil Raina, Dirk Rowe, Neil Sejoor, Vanessa Stark, Bala Varadarajan, Bram Wasti, Zachary Winstrom
Si vous utilisez SAM ou SA-1B dans votre recherche, veuillez utiliser l'entrée BibTeX suivante.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}


