obfuscated gradients
v1.0.0
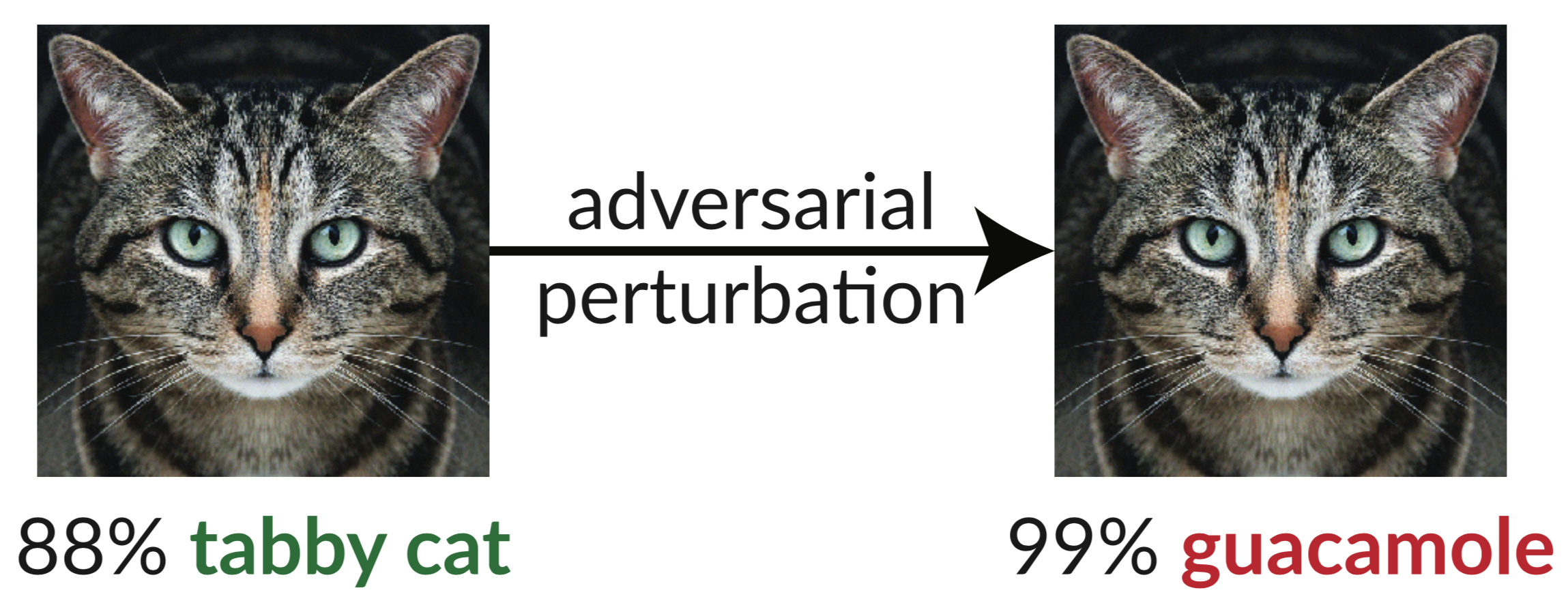
Ci-dessus, un exemple contradictoire : l'image légèrement perturbée du chat trompe un classificateur InceptionV3 en le classant comme "guacamole". De telles « images trompeuses » sont faciles à synthétiser en utilisant la descente de gradient (Szegedy et al. 2013).
Dans notre récent article, nous évaluons la robustesse de neuf articles acceptés à l'ICLR 2018 en tant que défenses non certifiées sécurisées par boîte blanche contre des exemples contradictoires. Nous constatons que sept des neuf défenses offrent une augmentation limitée de la robustesse et peuvent être brisées par des techniques d'attaque améliorées que nous développons.
Vous trouverez ci-dessous le tableau 1 de notre article, dans lequel nous montrons la robustesse de chaque défense acceptée face aux exemples contradictoires que nous pouvons construire :
| Défense | Ensemble de données | Distance | Précision |
|---|---|---|---|
| Buckman et coll. (2018) | CIFAR | 0,031 (linf) | 0%* |
| Ma et coll. (2018) | CIFAR | 0,031 (linf) | 5% |
| Guo et coll. (2018) | ImageNet | 0,05 (l2) | 0%* |
| Dhillon et coll. (2018) | CIFAR | 0,031 (linf) | 0% |
| Xie et coll. (2018) | ImageNet | 0,031 (linf) | 0%* |
| Chanson et coll. (2018) | CIFAR | 0,031 (linf) | 9%* |
| Samangouei et al. (2018) | MNIST | 0,005 (l2) | 55%** |
| Madry et coll. (2018) | CIFAR | 0,031 (linf) | 47% |
| Na et coll. (2018) | CIFAR | 0,015 (linf) | 15% |
(Les défenses indiquées par * proposent également de combiner un entraînement contradictoire ; nous rapportons ici la défense seule. Voir notre article, section 5 pour les chiffres complets. Le principe fondamental derrière la défense noté par ** a une précision de 0 % ; dans la pratique, les imperfections de la défense sont à l'origine du problème théorique. l'attaque optimale échoue, voir la section 5.4.2 pour plus de détails.)
La seule défense que nous observons qui augmente considérablement la robustesse aux exemples contradictoires dans le modèle de menace proposé est « Vers des modèles d'apprentissage profond résistants aux attaques contradictoires » (Madry et al. 2018), et nous n'avons pas pu vaincre cette défense sans sortir du modèle de menace. . Même dans ce cas, cette technique s'est avérée difficile à mettre à l'échelle d'ImageNet (Kurakin et al. 2016). Le reste des articles (outre l'article de Na et al., qui offre une robustesse limitée) s'appuient soit par inadvertance, soit intentionnellement sur ce que nous appelons des gradients obscurcis . Les attaques standards appliquent une descente de gradient pour maximiser la perte du réseau sur une image donnée afin de générer un exemple contradictoire sur un réseau neuronal. De telles méthodes d'optimisation nécessitent un signal de gradient utile pour réussir. Lorsqu’une défense obscurcit les gradients, elle brise ce signal de gradient et provoque l’échec des méthodes basées sur l’optimisation.
Nous identifions trois manières par lesquelles les défenses provoquent des gradients obscurcis et construisons des attaques pour contourner chacun de ces cas. Nos attaques sont généralement applicables à toute défense qui inclut, intentionnellement ou non, une opération non différenciable ou qui empêche le signal de gradient de circuler à travers le réseau. Nous espérons que les travaux futurs pourront utiliser nos approches pour effectuer une évaluation de sécurité plus approfondie.
Abstrait:
Nous identifions les gradients obscurcis, une sorte de masquage de gradient, comme un phénomène qui conduit à un faux sentiment de sécurité dans les défenses contre des exemples contradictoires. Alors que les défenses qui provoquent des gradients obscurcis semblent vaincre les attaques itératives basées sur l’optimisation, nous constatons que les défenses reposant sur cet effet peuvent être contournées. Nous décrivons les comportements caractéristiques des défenses présentant cet effet, et pour chacun des trois types de gradients obscurcis que nous découvrons, nous développons des techniques d'attaque pour le surmonter. Dans une étude de cas, examinant les défenses sécurisées par boîte blanche non certifiées lors de l'ICLR 2018, nous avons constaté que les gradients obscurcis sont fréquents, avec 7 défenses sur 9 reposant sur des gradients obscurcis. Nos nouvelles attaques réussissent à contourner 6 complètement, et 1 partiellement, dans le modèle de menace original considéré par chaque article.
Pour plus de détails, lisez notre article.
Ce référentiel contient nos instanciations des techniques d'attaque générales décrites dans notre article, brisant 7 des défenses ICLR 2018. Certaines défenses n'ont pas publié de code source (au moment où nous avons effectué ce travail), nous avons donc dû les réimplémenter.
@inproceedings{obfuscated-gradients, author = {Anish Athalye et Nicholas Carlini et David Wagner}, title = {Les dégradés obfuscated donnent un faux sentiment de sécurité : contourner les défenses face aux exemples contradictoires}, booktitle = {Actes de la 35e Conférence internationale sur les machines Apprentissage, {ICML} 2018}, année = {2018}, mois = juillet, url = {https://arxiv.org/abs/1802.00420},
} 

