Megatron LM
NVIDIA Megatron Core 0.9.0
Ce référentiel comprend deux composants essentiels : Megatron-LM et Megatron-Core . Megatron-LM sert de cadre orienté vers la recherche exploitant Megatron-Core pour la formation sur des modèles de langage étendus (LLM). Megatron-Core, quant à lui, est une bibliothèque de techniques de formation optimisées pour le GPU, accompagnée d'un support produit formel comprenant des API versionnées et des versions régulières. Vous pouvez utiliser Megatron-Core avec Megatron-LM ou Nvidia NeMo Framework pour une solution de bout en bout et cloud native. Alternativement, vous pouvez intégrer les éléments constitutifs de Megatron-Core dans votre cadre de formation préféré.
Introduit pour la première fois en 2019, Megatron (1, 2 et 3) a déclenché une vague d'innovation dans la communauté de l'IA, permettant aux chercheurs et aux développeurs d'utiliser les fondements de cette bibliothèque pour faire progresser les progrès du LLM. Aujourd'hui, bon nombre des frameworks de développement LLM les plus populaires ont été inspirés et construits en exploitant directement la bibliothèque open source Megatron-LM, suscitant une vague de modèles de base et de startups d'IA. Certains des frameworks LLM les plus populaires construits sur Megatron-LM incluent Colossal-AI, HuggingFace Accelerate et NVIDIA NeMo Framework. Une liste des projets qui ont directement utilisé Megatron peut être trouvée ici.
Megatron-Core est une bibliothèque open source basée sur PyTorch qui contient des techniques optimisées pour le GPU et des optimisations de pointe au niveau du système. Il les résume dans des API composables et modulaires, offrant une flexibilité totale aux développeurs et aux chercheurs en modèles pour former des transformateurs personnalisés à grande échelle sur l'infrastructure informatique accélérée NVIDIA. Cette bibliothèque est compatible avec tous les GPU NVIDIA Tensor Core, y compris la prise en charge de l'accélération FP8 pour les architectures NVIDIA Hopper.
Megatron-Core propose des éléments de base tels que des mécanismes d'attention, des blocs et couches de transformateur, des couches de normalisation et des techniques d'intégration. Des fonctionnalités supplémentaires telles que le recalcul d’activation et les points de contrôle distribués sont également intégrées nativement à la bibliothèque. Les éléments de base et les fonctionnalités sont tous optimisés par GPU et peuvent être construits avec des stratégies de parallélisation avancées pour une vitesse de formation et une stabilité optimales sur l'infrastructure informatique accélérée NVIDIA. Un autre composant clé de la bibliothèque Megatron-Core comprend des techniques avancées de parallélisme de modèles (tenseur, séquence, pipeline, contexte et parallélisme expert MoE).
Megatron-Core peut être utilisé avec NVIDIA NeMo, une plateforme d'IA de niveau entreprise. Alternativement, vous pouvez explorer Megatron-Core avec la boucle de formation native PyTorch ici. Visitez la documentation Megatron-Core pour en savoir plus.
Notre base de code est capable de former efficacement de grands modèles de langage (c'est-à-dire des modèles avec des centaines de milliards de paramètres) avec un parallélisme de modèles et de données. Pour démontrer comment notre logiciel s'adapte à plusieurs GPU et tailles de modèles, nous considérons des modèles GPT allant de 2 milliards de paramètres à 462 milliards de paramètres. Tous les modèles utilisent une taille de vocabulaire de 131 072 et une longueur de séquence de 4 096. Nous faisons varier la taille cachée, le nombre de têtes d'attention et le nombre de couches pour arriver à une taille de modèle spécifique. À mesure que la taille du modèle augmente, nous augmentons également légèrement la taille du lot. Nos expériences utilisent jusqu'à 6 144 GPU H100. Nous effectuons un chevauchement fin des données parallèles ( --overlap-grad-reduce --overlap-param-gather ), du tenseur parallèle ( --tp-comm-overlap ) et de la communication parallèle pipeline (activée par défaut) avec calcul pour améliorer l’évolutivité. Les débits signalés sont mesurés pour la formation de bout en bout et incluent toutes les opérations, y compris le chargement des données, les étapes d'optimisation, la communication et même la journalisation. Notez que nous n'avons pas entraîné ces modèles à la convergence.
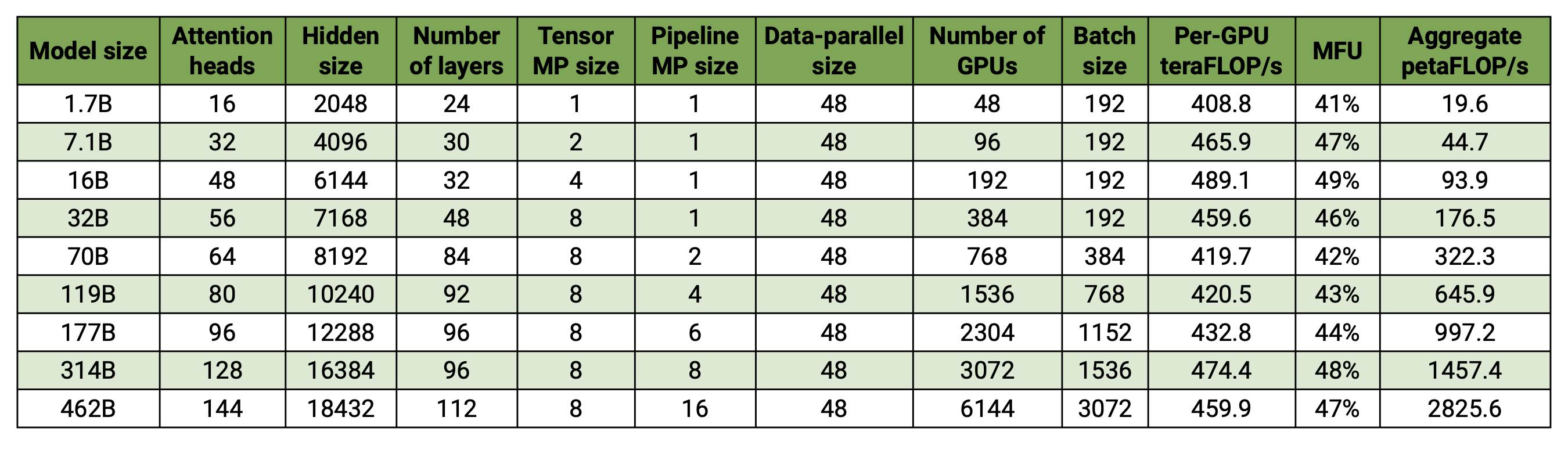
Nos résultats à faible échelle montrent une mise à l'échelle superlinéaire (MFU augmente de 41 % pour le plus petit modèle considéré à 47-48 % pour les plus grands modèles) ; en effet, les GEMM plus grands ont une intensité arithmétique plus élevée et sont par conséquent plus efficaces à exécuter.
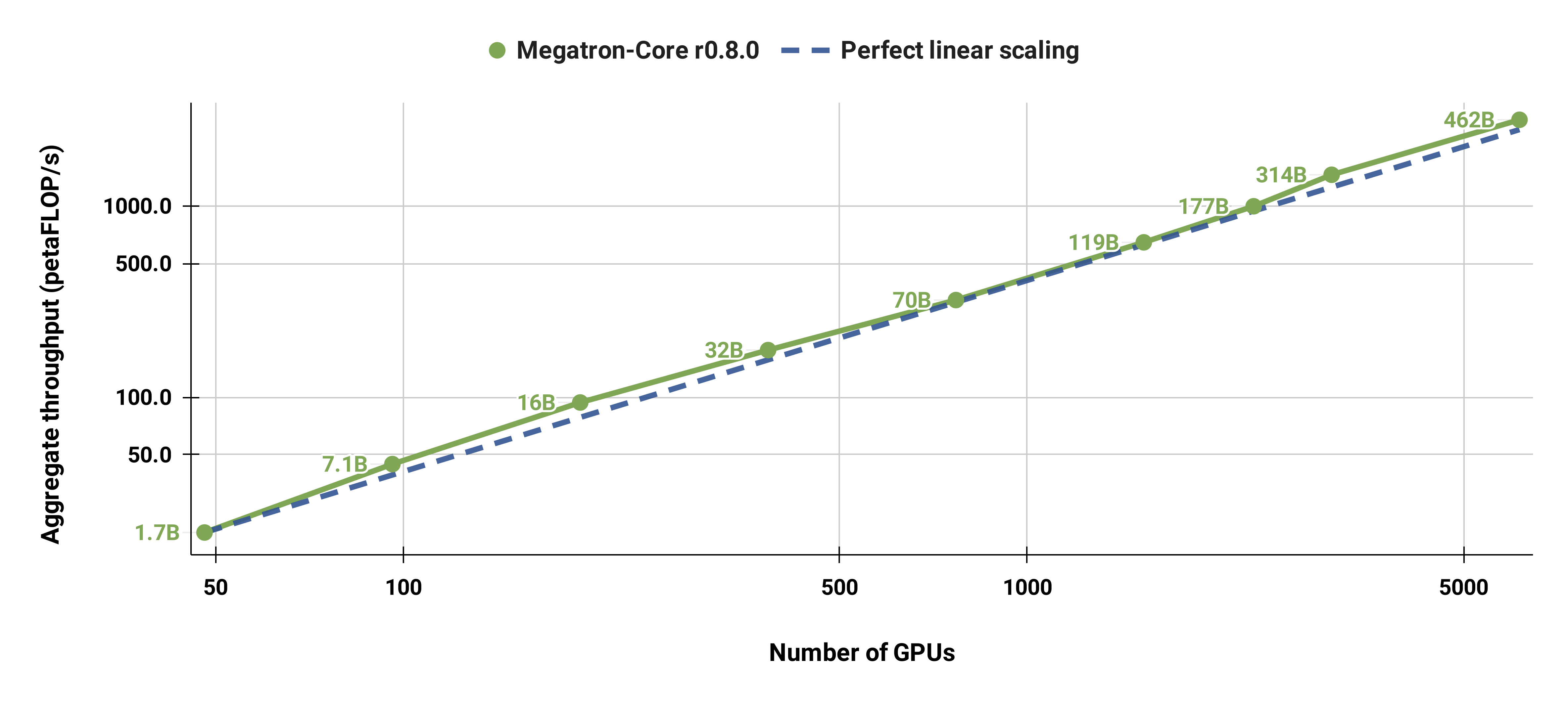
Nous avons également fortement adapté le modèle GPT-3 standard (notre version contient un peu plus de 175 milliards de paramètres en raison d'une plus grande taille de vocabulaire) de 96 GPU H100 à 4 608 GPU, en utilisant la même taille de lot de 1 152 séquences. La communication devient plus exposée à plus grande échelle, entraînant une réduction du MFU de 47 % à 42 %.
Nous vous recommandons fortement d'utiliser la dernière version du conteneur PyTorch de NGC avec les nœuds DGX. Si vous ne pouvez pas l'utiliser pour une raison quelconque, utilisez les dernières versions de pytorch, cuda, nccl et NVIDIA APEX. Le prétraitement des données nécessite NLTK, bien que cela ne soit pas requis pour la formation, l'évaluation ou les tâches en aval.
Vous pouvez lancer une instance du conteneur PyTorch et monter Megatron, votre ensemble de données et vos points de contrôle avec les commandes Docker suivantes :
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
Nous avons fourni des points de contrôle BERT-345M et GPT-345M pré-entraînés pour évaluer ou affiner les tâches en aval. Pour accéder à ces points de contrôle, inscrivez-vous d'abord et configurez la CLI du registre NVIDIA GPU Cloud (NGC). Une documentation supplémentaire pour le téléchargement de modèles peut être trouvée dans la documentation NGC.
Alternativement, vous pouvez télécharger directement les points de contrôle en utilisant :
BERT-345M-uncased : wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M-cased : wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M : wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
Les modèles nécessitent des fichiers de vocabulaire pour s'exécuter. Le fichier de vocabulaire BERT WordPièce peut être extrait des modèles BERT pré-entraînés de Google : sans casse, avec casse. Le fichier de vocabulaire GPT et le tableau de fusion peuvent être téléchargés directement.
Après l'installation, plusieurs flux de travail sont possibles. Le plus complet est :
Cependant, les étapes 1 et 2 peuvent être remplacées en utilisant l'un des modèles pré-entraînés mentionnés ci-dessus.
Nous avons fourni plusieurs scripts pour la pré-formation de BERT et GPT dans le répertoire examples , ainsi que des scripts pour les tâches en aval zéro-shot et affinées, notamment l'évaluation MNLI, RACE, WikiText103 et LAMBADA. Il existe également un script pour la génération de texte interactif GPT.
Les données de formation nécessitent un prétraitement. Tout d'abord, placez vos données d'entraînement dans un format json lâche, avec un json contenant un échantillon de texte par ligne. Par exemple:
{"src": "www.nvidia.com", "text": "Le renard brun rapide", "type": "Eng", "id": "0", "title": "Première partie"}
{"src": "Internet", "text": "saute par-dessus le chien paresseux", "type": "Eng", "id": "42", "title": "Deuxième partie"}
Le nom du champ text du json peut être modifié en utilisant l'indicateur --json-key dans preprocess_data.py Les autres métadonnées sont facultatives et ne sont pas utilisées dans la formation.
Le json lâche est ensuite traité dans un format binaire pour la formation. Pour convertir le json au format mmap, utilisez preprocess_data.py . Un exemple de script pour préparer les données pour la formation BERT est :
outils python/preprocess_data.py
--input mon-corpus.json
--output-prefix mon-bert
--vocab-file bert-vocab.txt
--tokenizer-type BertWordPièceLowerCase
--phrases divisées
La sortie sera deux fichiers nommés, dans ce cas, my-bert_text_sentence.bin et my-bert_text_sentence.idx . Le --data-path spécifié dans la formation BERT ultérieure est le chemin complet et le nouveau nom de fichier, mais sans l'extension du fichier.
Pour T5, utilisez le même prétraitement que BERT, en le renommant peut-être :
--output-prefix mon-t5
Certaines modifications mineures sont requises pour le prétraitement des données GPT, à savoir l'ajout d'une table de fusion, un jeton de fin de document, la suppression du fractionnement des phrases et une modification du type de tokeniseur :
outils python/preprocess_data.py
--input mon-corpus.json
--output-prefix mon-gpt2
--vocab-file gpt2-vocab.json
--tokenizer-type GPT2BPETokenizer
--merge-file gpt2-merges.txt
--append-eod
Ici, les fichiers de sortie sont nommés my-gpt2_text_document.bin et my-gpt2_text_document.idx . Comme auparavant, dans la formation GPT, utilisez le nom le plus long sans l'extension comme --data-path .
D'autres arguments de ligne de commande sont décrits dans le fichier source preprocess_data.py .
Le script examples/bert/train_bert_340m_distributed.sh exécute le pré-entraînement BERT d'un seul paramètre GPU 345M. Le débogage est la principale utilisation de la formation sur un seul GPU, car la base de code et les arguments de ligne de commande sont optimisés pour une formation hautement distribuée. La plupart des arguments sont assez explicites. Par défaut, le taux d'apprentissage décroît linéairement au fil des itérations d'entraînement commençant à --lr jusqu'à un minimum défini par --min-lr au fil des itérations --lr-decay-iters . La fraction d'itérations d'entraînement utilisée pour l'échauffement est définie par --lr-warmup-fraction . Bien qu'il s'agisse d'une formation sur un seul GPU, la taille du lot spécifiée par --micro-batch-size est une taille de lot de chemin unique avant-arrière et le code effectuera des étapes d'accumulation de gradient jusqu'à ce qu'il atteigne la global-batch-size qui est la taille du lot. par itération. Les données sont divisées selon un rapport de 949:50:1 pour les ensembles de formation/validation/test (la valeur par défaut est 969:30:1). Ce partitionnement s'effectue à la volée, mais est cohérent entre les exécutions avec la même graine aléatoire (1234 par défaut, ou spécifiée manuellement avec --seed ). Nous utilisons train-iters comme itérations de formation demandées. Alternativement, on peut fournir --train-samples qui correspond au nombre total d'échantillons sur lesquels s'entraîner. Si cette option est présente, alors au lieu de fournir --lr-decay-iters , il faudra fournir --lr-decay-samples .
Les options de journalisation, de sauvegarde des points de contrôle et d'intervalle d'évaluation sont spécifiées. Notez que le --data-path inclut désormais le suffixe supplémentaire _text_sentence ajouté lors du prétraitement, mais n'inclut pas les extensions de fichier.
D'autres arguments de ligne de commande sont décrits dans le fichier source arguments.py .
Pour exécuter train_bert_340m_distributed.sh , apportez toutes les modifications souhaitées, notamment en définissant les variables d'environnement pour CHECKPOINT_PATH , VOCAB_FILE et DATA_PATH . Assurez-vous de définir ces variables sur leurs chemins dans le conteneur. Lancez ensuite le conteneur avec Megatron et les chemins nécessaires montés (comme expliqué dans la configuration) et exécutez l'exemple de script.
Le script examples/gpt3/train_gpt3_175b_distributed.sh exécute un pré-entraînement GPT avec un seul paramètre GPU 345M. Comme mentionné ci-dessus, la formation sur un seul GPU est principalement destinée à des fins de débogage, car le code est optimisé pour la formation distribuée.
Il suit en grande partie le même format que le script BERT précédent avec quelques différences notables : le schéma de tokenisation utilisé est BPE (qui nécessite une table de fusion et un fichier de vocabulaire json ) au lieu de WordPièce, l'architecture du modèle permet des séquences plus longues (notez que le l'intégration de la position maximale doit être supérieure ou égale à la longueur maximale de la séquence), et --lr-decay-style a été défini sur la désintégration du cosinus. Notez que le --data-path inclut désormais le suffixe _text_document supplémentaire ajouté lors du prétraitement, mais n'inclut pas les extensions de fichier.
D'autres arguments de ligne de commande sont décrits dans le fichier source arguments.py .
train_gpt3_175b_distributed.sh peut être lancé de la même manière que décrit pour BERT. Définissez les variables d'environnement et apportez d'autres modifications, lancez le conteneur avec les montages appropriés et exécutez le script. Plus de détails dans examples/gpt3/README.md
Très similaire à BERT et GPT, le script examples/t5/train_t5_220m_distributed.sh exécute un pré-entraînement T5 de « base » sur un seul GPU (paramètre ~ 220 M). La principale différence entre BERT et GPT réside dans l'ajout des arguments suivants pour s'adapter à l'architecture T5 :
--kv-channels définit la dimension interne des matrices « clé » et « valeur » de tous les mécanismes d'attention du modèle. Pour BERT et GPT, la valeur par défaut est la taille cachée divisée par le nombre de têtes d'attention, mais peut être configurée pour T5.
--ffn-hidden-size définit la taille cachée dans les réseaux à action directe au sein d'une couche de transformateur. Pour BERT et GPT, la valeur par défaut est 4 fois la taille cachée du transformateur, mais peut être configurée pour T5.
--encoder-seq-length et --decoder-seq-length définissent séparément la longueur de la séquence pour l'encodeur et le décodeur.
Tous les autres arguments restent les mêmes pour la pré-formation BERT et GPT. Exécutez cet exemple avec les mêmes étapes décrites ci-dessus pour les autres scripts.
Plus de détails dans examples/t5/README.md
Les scripts pretrain_{bert,gpt,t5}_distributed.sh utilisent le lanceur distribué PyTorch pour la formation distribuée. En tant que tel, la formation multi-nœuds peut être réalisée en définissant correctement les variables d'environnement. Consultez la documentation officielle de PyTorch pour une description plus détaillée de ces variables d'environnement. Par défaut, la formation multi-nœuds utilise le backend distribué nccl. Un simple ensemble d'arguments supplémentaires et l'utilisation du module distribué PyTorch avec le lanceur élastique torchrun (équivalent à python -m torch.distributed.run ) sont les seules exigences supplémentaires pour adopter une formation distribuée. Voir l'un des pretrain_{bert,gpt,t5}_distributed.sh pour plus de détails.
Nous utilisons deux types de parallélisme : le parallélisme des données et le parallélisme des modèles. Notre implémentation du parallélisme des données est dans megatron/core/distributed et prend en charge le chevauchement de la réduction de gradient avec la passe arrière lorsque l'option de ligne de commande --overlap-grad-reduce est utilisée.
Deuxièmement, nous avons développé une approche de modèle parallèle bidimensionnel simple et efficace. Pour utiliser la première dimension, le parallélisme du modèle tensoriel (divisant l'exécution d'un seul module de transformateur sur plusieurs GPU, voir la section 3 de notre article), ajoutez l'indicateur --tensor-model-parallel-size pour spécifier le nombre de GPU parmi lesquels divisez le modèle, ainsi que les arguments transmis au lanceur distribué comme mentionné ci-dessus. Pour utiliser la deuxième dimension, le parallélisme de séquence, spécifiez --sequence-parallel , qui nécessite également que le parallélisme du modèle tensoriel soit activé car il est réparti sur les mêmes GPU (plus de détails dans la section 4.2.2 de notre article).
Pour utiliser le parallélisme du modèle de pipeline (partitionner les modules de transformateur en étapes avec un nombre égal de modules de transformateur sur chaque étape, puis pipeliner l'exécution en divisant le lot en microlots plus petits, voir la section 2.2 de notre article), utilisez le --pipeline-model-parallel-size -indicateur --pipeline-model-parallel-size pour spécifier le nombre d'étapes en lesquelles diviser le modèle (par exemple, diviser un modèle avec 24 couches de transformateur sur 4 étapes signifierait que chaque étape recevrait chacune 6 couches de transformateur).
Nous avons des exemples d'utilisation de ces deux formes différentes de parallélisme de modèles, les exemples de scripts se terminant par distributed_with_mp.sh .
Hormis ces changements mineurs, la formation distribuée est identique à la formation sur un seul GPU.
Le calendrier de pipeline entrelacé (plus de détails dans la section 2.2.2 de notre article) peut être activé à l'aide de l'argument --num-layers-per-virtual-pipeline-stage , qui contrôle le nombre de couches de transformateur dans une étape virtuelle (par défaut avec le planning non entrelacé, chaque GPU exécutera une seule étape virtuelle avec NUM_LAYERS / PIPELINE_MP_SIZE couches de transformateur). Le nombre total de couches dans le modèle de transformateur doit être divisible par la valeur de cet argument. De plus, le nombre de microlots dans le pipeline (calculé comme GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) ) doit être divisible par PIPELINE_MP_SIZE lors de l'utilisation de ce calendrier (cette condition est vérifiée dans une assertion dans le code). La planification entrelacée n'est pas prise en charge pour les pipelines à 2 étapes ( PIPELINE_MP_SIZE=2 ).
Pour réduire l'utilisation de la mémoire GPU lors de la formation d'un modèle volumineux, nous prenons en charge diverses formes de points de contrôle d'activation et de recalcul. Au lieu que toutes les activations soient stockées en mémoire pour être utilisées pendant le backprop, comme c'était traditionnellement le cas dans les modèles d'apprentissage profond, seules les activations à certains « points de contrôle » du modèle sont conservées (ou stockées) en mémoire, et les autres activations sont recalculées sur -le vol en cas de besoin pour le backprop. Notez que ce type de point de contrôle, le point de contrôle d'activation , est très différent du point de contrôle des paramètres du modèle et de l'état de l'optimiseur, qui est mentionné ailleurs.
Nous prenons en charge deux niveaux de granularité de recalcul : selective et full . Le recalcul sélectif est la valeur par défaut et est recommandé dans presque tous les cas. Ce mode conserve en mémoire les activations qui prennent moins d'espace de stockage mémoire et sont plus coûteuses à recalculer et recalcule les activations qui prennent plus d'espace de stockage mémoire mais sont relativement peu coûteuses à recalculer. Consultez notre article pour plus de détails. Vous devriez constater que ce mode maximise les performances tout en minimisant la mémoire requise pour stocker les activations. Pour activer le recalcul d'activation sélective, utilisez simplement --recompute-activations .
Dans les cas où la mémoire est très limitée, le recalcul full enregistre uniquement les entrées d'une couche de transformateur, ou d'un groupe, ou d'un bloc, de couches de transformateur, et recalcule tout le reste. Pour activer le recalcul d'activation complète, utilisez --recompute-granularity full . Lors de l'utilisation du recalcul d'activation full , il existe deux méthodes : uniform et block , choisies à l'aide de l'argument --recompute-method .
La méthode uniform divise uniformément les couches de transformateur en groupes de couches (chaque groupe de taille --recompute-num-layers ) et stocke les activations d'entrée de chaque groupe en mémoire. La taille du groupe de base est de 1 et, dans ce cas, l'activation d'entrée de chaque couche de transformateur est stockée. Lorsque la mémoire GPU est insuffisante, l'augmentation du nombre de couches par groupe réduit l'utilisation de la mémoire, permettant ainsi d'entraîner un modèle plus grand. Par exemple, lorsque --recompute-num-layers est défini sur 4, seule l'activation d'entrée de chaque groupe de 4 couches de transformateur est stockée.
La méthode block recalcule les activations d'entrée d'un nombre spécifique (donné par --recompute-num-layers ) de couches de transformateur individuelles par étape de pipeline et stocke les activations d'entrée des couches restantes dans l'étape de pipeline. La réduction de --recompute-num-layers entraîne le stockage des activations d'entrée dans davantage de couches de transformateur, ce qui réduit le recalcul d'activation requis dans le backprop, améliorant ainsi les performances d'entraînement tout en augmentant l'utilisation de la mémoire. Par exemple, lorsque nous spécifions 5 couches à recalculer sur 8 couches par étage de pipeline, les activations d'entrée des 5 premières couches de transformateur uniquement sont recalculées lors de l'étape de backprop tandis que les activations d'entrée pour les 3 dernières couches sont stockées. --recompute-num-layers peut être augmenté progressivement jusqu'à ce que la quantité d'espace de stockage mémoire requise soit juste assez petite pour tenir dans la mémoire disponible, utilisant ainsi au maximum la mémoire et maximisant les performances.
Utilisation : --use-distributed-optimizer . Compatible avec tous les modèles et types de données.
L'optimiseur distribué est une technique d'économie de mémoire, dans laquelle l'état de l'optimiseur est réparti uniformément sur les rangs parallèles de données (par rapport à la méthode traditionnelle de réplication de l'état de l'optimiseur sur les rangs parallèles de données). Comme décrit dans ZeRO : Memory Optimizations Toward Training Trillion Parameter Models, notre implémentation distribue tous les états de l'optimiseur qui ne chevauchent pas l'état du modèle. Par exemple, lors de l'utilisation des paramètres du modèle fp16, l'optimiseur distribué conserve sa propre copie distincte des paramètres et diplômes principaux fp32, qui sont répartis entre les rangs DP. Cependant, lors de l'utilisation des paramètres du modèle bf16, les grades principaux fp32 de l'optimiseur distribué sont les mêmes que les grades fp32 du modèle, et donc les grades dans ce cas ne sont pas distribués (bien que les paramètres principaux fp32 soient toujours distribués, car ils sont séparés du bf16). paramètres du modèle).
Les économies de mémoire théoriques varient en fonction de la combinaison du type de paramètre et du type de diplôme du modèle. Dans notre implémentation, le nombre théorique d'octets par paramètre est (où « d » est la taille parallèle des données) :
| Optim non distribué | Distribué optimal | |
|---|---|---|
| paramètre fp16, diplômes fp16 | 20 | 4 + 16/j |
| paramètre bf16, diplômés fp32 | 18 | 6 + 12/j |
| paramètre fp32, diplômes fp32 | 16 | 8 + 8/j |
Comme pour le parallélisme de données régulier, le chevauchement de la réduction de gradient (dans ce cas, une réduction-diffusion) avec le passage vers l'arrière peut être facilité en utilisant l'indicateur --overlap-grad-reduce . De plus, le chevauchement du paramètre all-gather peut être chevauché avec la passe avant en utilisant --overlap-param-gather .
Utilisation : --use-flash-attn . Supportez les dimensions de la tête d'attention au maximum 128.
FlashAttention est un algorithme rapide et économe en mémoire pour calculer l'attention exacte. Il accélère la formation du modèle et réduit les besoins en mémoire.
Pour installer FlashAttention :
pip install flash-attn Dans examples/gpt3/train_gpt3_175b_distributed.sh nous avons fourni un exemple de configuration de Megatron pour entraîner GPT-3 avec 175 milliards de paramètres sur 1 024 GPU. Le script est conçu pour Slurm avec le plugin pyxis mais peut être facilement adopté par n'importe quel autre planificateur. Il utilise un parallélisme tenseur à 8 voies et un parallélisme de pipeline à 16 voies. Avec les options global-batch-size 1536 et rampup-batch-size 16 16 5859375 , la formation commencera avec la taille de lot globale 16 et augmentera linéairement la taille de lot globale jusqu'à 1536 sur 5 859 375 échantillons avec des étapes incrémentielles 16. L'ensemble de données de formation peut être soit un seul ensemble ou plusieurs ensembles de données combinés à un ensemble de poids.
Avec une taille de lot globale totale de 1 536 sur 1 024 GPU A100, chaque itération prend environ 32 secondes, ce qui donne 138 téraFLOP par GPU, soit 44 % des FLOP de pointe théoriques.
Retro (Borgeaud et al., 2022) est un modèle de langage (LM) autorégressif uniquement avec décodeur, pré-entraîné avec récupération-augmentation. Retro offre une évolutivité pratique pour prendre en charge un pré-entraînement à grande échelle à partir de zéro en récupérant des milliards de jetons. Le pré-entraînement avec récupération fournit un mécanisme de stockage plus efficace des connaissances factuelles, par rapport au stockage implicite des connaissances factuelles dans les paramètres du réseau, réduisant ainsi considérablement les paramètres du modèle tout en obtenant une perplexité inférieure à celle du GPT standard. Retro offre également la flexibilité de mettre à jour les connaissances stockées dans les LM (Wang et al., 2023a) en mettant à jour la base de données de récupération sans entraîner à nouveau les LM.
InstructRetro (Wang et al., 2023b) augmente encore la taille de Retro à 48B, avec le plus grand LLM pré-entraîné avec récupération (en décembre 2023). Le modèle de base obtenu, Retro 48B, surpasse largement son homologue GPT en termes de perplexité. Avec le réglage des instructions sur Retro, InstructRetro démontre une amélioration significative par rapport au GPT réglé par les instructions sur les tâches en aval dans le paramètre zéro tir. Plus précisément, l'amélioration moyenne d'InstructRetro est de 7 % par rapport à son homologue GPT sur 8 tâches d'assurance qualité courtes et de 10 % par rapport à GPT sur 4 tâches d'assurance qualité longues et difficiles. Nous constatons également que l'on peut supprimer l'encodeur de l'architecture InstructRetro et utiliser directement le squelette du décodeur InstructRetro comme GPT, tout en obtenant des résultats comparables.
Dans ce référentiel, nous fournissons un guide de reproduction de bout en bout pour implémenter Retro et InstructRetro, couvrant
Voir tools/retro/README.md pour un aperçu détaillé.
Voir exemples/mamba pour plus de détails.
Nous fournissons plusieurs arguments de ligne de commande, détaillés dans les scripts répertoriés ci-dessous, pour gérer diverses tâches en aval sans tir et affinées. Cependant, vous pouvez également affiner votre modèle à partir d'un point de contrôle pré-entraîné sur d'autres corpus, si vous le souhaitez. Pour ce faire, ajoutez simplement l'indicateur --finetune et ajustez les fichiers d'entrée et les paramètres de formation dans le script de formation d'origine. Le nombre d'itérations sera réinitialisé à zéro et l'optimiseur et l'état interne seront réinitialisés. Si le réglage fin est interrompu pour une raison quelconque, assurez-vous de supprimer l'indicateur --finetune avant de continuer, sinon la formation recommencera depuis le début.
Étant donné que l'évaluation nécessite beaucoup moins de mémoire que la formation, il peut être avantageux de fusionner un modèle formé en parallèle pour une utilisation sur moins de GPU dans les tâches en aval. Le script suivant accomplit cela. Cet exemple lit un modèle GPT avec un parallélisme de tenseur à 4 voies et de modèle de pipeline à 4 voies et écrit un modèle avec un parallélisme de tenseur à 2 voies et de modèle de pipeline à 2 voies.
outils python/checkpoint/convert.py
--model-type GPT
--load-dir points de contrôle/gpt3_tp4_pp4
--save-dir points de contrôle/gpt3_tp2_pp2
--target-tensor-parallel-size 2
--target-pipeline-parallel-size 2
Plusieurs tâches en aval sont décrites ci-dessous pour les modèles GPT et BERT. Ils peuvent être exécutés en modes distribué et parallèle de modèle avec les mêmes modifications que celles utilisées dans les scripts de formation.
Nous avons inclus un simple serveur REST à utiliser pour la génération de texte dans tools/run_text_generation_server.py . Vous l'exécutez un peu comme vous démarreriez une tâche de pré-entraînement, en spécifiant un point de contrôle de pré-entraînement approprié. Il existe également quelques paramètres facultatifs : temperature , top-k et top-p . Voir --help ou le fichier source pour plus d'informations. Voir examples/inference/run_text_generation_server_345M.sh pour un exemple de la façon d'exécuter le serveur.
Une fois le serveur exécuté, vous pouvez utiliser tools/text_generation_cli.py pour l'interroger, il faut un argument qui est l'hôte sur lequel le serveur s'exécute.
tools/text_generation_cli.py localhost:5000
Vous pouvez également utiliser CURL ou tout autre outil pour interroger directement le serveur :
curl 'http://localhost:5000/api' -X 'PUT' -H 'Content-Type : application/json; charset=UTF-8' -d '{"prompts":["Bonjour tout le monde"], "tokens_to_generate":1}'
Voir megatron/inference/text_Generation_server.py pour plus d'options API.
Nous incluons un exemple dans examples/academic_paper_scripts/detxoify_lm/ pour détoxifier les modèles de langage en tirant parti du pouvoir génératif des modèles de langage.
Voir examples/academic_paper_scripts/detxoify_lm/README.md pour des didacticiels étape par étape sur la façon d'effectuer une formation adaptative au domaine et de détoxifier LM à l'aide d'un corpus auto-généré.
Nous incluons des exemples de scripts pour l'évaluation GPT sur l'évaluation de la perplexité WikiText et la précision LAMBADA Cloze.
Pour une comparaison uniforme avec des travaux antérieurs, nous évaluons la perplexité sur l'ensemble de données de test WikiText-103 au niveau des mots et calculons de manière appropriée la perplexité compte tenu du changement de jetons lors de l'utilisation de notre tokeniseur de sous-mots.
Nous utilisons la commande suivante pour exécuter l'évaluation WikiText-103 sur un modèle de paramètres 345M.
TÂCHE="WIKITEXT103"
VALID_DATA=<chemin du texte wiki>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=points de contrôle/gpt2_345m
COMMON_TASK_ARGS="--num-couches 24
--taille cachée 1024
--num-attention-heads 16
--seq-length 1024
--max-position-embeddings 1024
--fp16
--fichier-vocab $VOCAB_FILE"
tâches python/main.py
--tâche $TACHE
$COMMON_TASK_ARGS
--valid-data $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--merge-file $MERGE_FILE
--load $CHECKPOINT_PATH
--micro-lot-taille 8
--log-intervalle 10
--no-load-optim
--no-load-rng
Pour calculer la précision de cloze LAMBADA (la précision de la prédiction du dernier jeton étant donné les jetons précédents), nous utilisons une version traitée et détokenisée de l'ensemble de données LAMBADA.
Nous utilisons la commande suivante pour exécuter l'évaluation LAMBADA sur un modèle de paramètres 345M. Notez que l'indicateur --strict-lambada doit être utilisé pour exiger une correspondance de mots entiers. Assurez-vous que lambada fait partie du chemin du fichier.
TÂCHE="LAMBADA"
VALID_DATA=<chemin lambada>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=points de contrôle/gpt2_345m
COMMON_TASK_ARGS=<identiques à ceux de l'évaluation de la perplexité WikiText ci-dessus>
tâches python/main.py
--tâche $TACHE
$COMMON_TASK_ARGS
--valid-data $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--strict-lambada
--merge-file $MERGE_FILE
--load $CHECKPOINT_PATH
--micro-lot-taille 8
--log-intervalle 10
--no-load-optim
--no-load-rng
D'autres arguments de ligne de commande sont décrits dans le fichier source main.py
Le script suivant affine le modèle BERT pour l'évaluation sur l'ensemble de données RACE. Les répertoires TRAIN_DATA et VALID_DATA contiennent l'ensemble de données RACE sous forme de fichiers .txt distincts. Notez que pour RACE, la taille du lot correspond au nombre de requêtes RACE à évaluer. Étant donné que chaque requête RACE comporte quatre échantillons, la taille effective du lot transmise via le modèle sera quatre fois supérieure à la taille du lot spécifiée sur la ligne de commande.
TRAIN_DATA="données/RACE/train/milieu"
VALID_DATA="données/RACE/dev/middle
données/RACE/dev/high"
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=points de contrôle/bert_345m
CHECKPOINT_PATH=points de contrôle/bert_345m_race
COMMON_TASK_ARGS="--num-couches 24
--taille cachée 1024
--num-attention-heads 16
--séq-longueur 512
--max-position-embeddings 512
--fp16
--fichier-vocab $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--train-data $TRAIN_DATA
--valid-data $VALID_DATA
--pretrained-checkpoint $PRETRAINED_CHECKPOINT
--intervalle de sauvegarde 10000
--sauvegarder $CHECKPOINT_PATH
--log-intervalle 100
--eval-intervalle 1000
--eval-iters 10
--poids-décroissance 1.0e-1"
tâches python/main.py
--tâche COURSE
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer-type BertWordPièceLowerCase
--époques 3
--micro-lot-taille 4
--lr 1.0e-5
--lr-warmup-fraction 0,06
Le script suivant affine le modèle BERT pour l'évaluation avec le corpus de paires de phrases MultiNLI. Étant donné que les tâches correspondantes sont assez similaires, le script peut être rapidement modifié pour fonctionner également avec l'ensemble de données Quora Question Pairs (QQP).
Train_data = "data / glue_data / mnli / train.tsv"
Valid_data = "data / glue_data / mnli / dev_matched.tsv
data / glue_data / mnli / dev_mismatched.tsv "
Pretrained_checkpoint = Checkpoints / Bert_345m
Vocab_file = bert-vocab.txt
CheckPoint_path = Checkpoints / Bert_345m_mnli
Common_Task_args = <Identique à ceux de l'évaluation de la course ci-dessus>
Common_Task_args_Ext = <Identique à ceux de l'évaluation de la course ci-dessus>
python tasks / main.py
- Task Mnli
$ Commun_task_args
$ Commun_task_args_ext
- Type-Terkeizer-Type BertwordPieceLowerCase
- époques 5
--micro-lot-taille 8
- LR 5.0E-5
--LR-WARMUP-FRACTION 0,065
La famille de modèles lama-2 est un ensemble open source de modèles pré-entraînés et animés (pour le chat) qui ont obtenu de solides résultats à travers un large ensemble de références. Au moment de la sortie, les modèles LLAMA-2 ont obtenu parmi les meilleurs résultats pour les modèles open source et étaient compétitifs avec le modèle GPT-3.5 à source fermée (voir https://arxiv.org/pdf/2307.09288.pdf).
Les points de contrôle LLAMA-2 peuvent être chargés dans Megatron pour l'inférence et le finetuning. Voir la documentation ici.
La famille GPTModel Megatron-Core (MCORE) prend en charge les algorithmes de quantification avancés et l'inférence à haute performance via Tensorrt-llm.
Voir l'optimisation et le déploiement du modèle Megatron pour les exemples llama2 et nemotron3 .
Nous n'hébergeons aucun ensemble de données pour la formation GPT ou Bert, cependant, nous détaillons leur collection afin que nos résultats puissent être reproduits.
Nous vous recommandons de suivre le processus d'extraction des données Wikipedia spécifié par Google Research: "Le prétraitement recommandé est de télécharger le dernier vidage, d'extraire le texte avec wikiextractor.py, puis d'appliquer tout nettoyage nécessaire pour le convertir en texte brut."
Nous vous recommandons d'utiliser l'argument --json lors de l'utilisation de Wikiextractor, qui videra les données Wikipedia au format JSON lâche (un objet JSON par ligne), le rendant plus gérable sur le système de fichiers et également facilement consommable par notre base de code. Nous recommandons de prétraiter davantage cet ensemble de données JSON avec la normalisation de ponctuation NLTK. Pour la formation Bert, utilisez l'indicateur --split-sentences pour preprocess_data.py comme décrit ci-dessus pour inclure les ruptures de phrase dans l'indice produit. Si vous souhaitez utiliser les données Wikipedia pour la formation GPT, vous devez toujours la nettoyer avec NLTK / SPACY / FTFY, mais n'utilisez pas le drapeau --split-sentences .
Nous utilisons la bibliothèque OpenWExt OpenWExt accessible au public de l'œuvre de JCPETERS et EUKARYOTE31 pour télécharger les URL. Nous filtrons, nettoyons et déduisons ensuite tous le contenu téléchargé en fonction de la procédure décrite dans notre répertoire OpenWebText. Pour les URL Reddit correspondant au contenu jusqu'en octobre 2018, nous sommes arrivés à environ 37 Go de contenu.
La formation Megatron peut être reproductible dans le bord; Pour activer ce mode, utilisez --deterministic-mode . Cela signifie que la même configuration de formation s'exécute deux fois dans le même environnement HW et SW devrait produire des points de contrôle de modèle identiques, des pertes et des valeurs de métrique de précision (les métriques du temps d'itération peuvent varier).
Il existe actuellement trois optimisations mégatron connues qui rompent la reproductibilité tout en produisant des séries d'entraînement presque identiques:
NCCL_ALGO ) est important. Nous avons testé ce qui suit: ^NVLS , Tree , Ring , CollnetDirect , CollnetChain . Le code admet l'utilisation de ^NVLS , qui permet à NCCL le choix des algorithmes non NVLS; Son choix semble stable.--use-flash-attn .NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 .De plus, le déterminisim n'a été vérifié que dans les conteneurs Pytorch NGC jusqu'à 23,12 et plus récents. Si vous observez le non-déterminisme dans la formation de mégatron dans d'autres circonstances, veuillez ouvrir un problème.
Voici quelques-uns des projets où nous avons directement utilisé Megatron:


