Par Buqian Zheng(buqianz) et Yongkang Huang(yongkan1)
Affiche
Nous avons implémenté Corgy, un framework d'apprentissage profond dans Swift et Metal. Corgy peut être intégré aux applications macOS et iOS et être utilisé pour construire des réseaux neuronaux entraînés et les évaluer facilement. Nous avons obtenu une accélération de plus de 60 fois sur différents appareils dotés de différents GPU.

Le framework Metal 2 est une interface fournie par Apple qui fournit un accès quasi direct à l'unité de traitement graphique (GPU) sur iPhone/iPad et Mac. Outre les graphiques, Metal 2 a incorporé un ensemble de bibliothèques qui offrent un excellent support de parallélisme pour les opérations d'algèbre linéaire et les fonctions de traitement du signal nécessaires, capables de fonctionner sur différents types d'appareils Apple. Ces bibliothèques nous ont permis de créer des modèles d'apprentissage profond accélérés par GPU bien implémentés sur les appareils iOS, basés sur le modèle formé fourni par d'autres frameworks. 1
D'une manière générale, l'étape d'inférence d'un réseau neuronal entraîné nécessite beaucoup de calculs, en particulier pour les modèles comportant un nombre considérablement élevé de couches ou appliqués dans les scénarios nécessaires au traitement d'images haute résolution. Il convient de noter qu'il existe une énorme quantité de calculs matriciels (par exemple, couche convolutive) qui sont appropriés pour appliquer un fonctionnement parallélisé afin d'optimiser les performances.
Le premier défi auquel nous avons été confrontés est de concevoir une bonne abstraction de l'interface de programmation d'applications, expressive, facile à utiliser avec une faible courbe d'apprentissage et facile à utiliser pour nos utilisateurs.
Pendant tout le processus de développement, nous avons fait de notre mieux pour garder l'API publique aussi simple que possible, tout en conservant toutes les propriétés nécessaires pour créer tous les composants requis en tirant parti du mécanisme de programmation fonctionnel fourni par Swift. Nous avons également délibérément masqué les abstractions matérielles inutiles fournies par Metal pour faciliter la courbe d'apprentissage.
Bien que les modèles formés des différents réseaux soient faciles à obtenir sur Internet, l'hétérogénéité entre eux provoquée par les différentes mises en œuvre utilisant différents types d'outils a rendu difficile le travail de création d'un importateur de modèles universel.
Une partie du calcul est facile à comprendre de par sa conception mais nécessite une réflexion attentive lorsque vous souhaitez créer une implémentation efficace en la faisant abstraction. La convolution est un exemple représentatif.
La propriété intrinsèque de l'opération de convolution n'a pas une bonne localité, l'implémentation vanilla est difficile à comprendre et inefficace avec des boucles for compliquées. Nous devons également prendre en compte l'abstraction fournie par Metal 2 et créer un moyen pratique de partager les informations et les structures de données nécessaires entre l'hôte et l'appareil en tenant compte attentivement de la représentation des données et de la disposition de la mémoire.
Pendant la phase de développement, nous sommes consciencieux lorsqu'il s'agit de garantir que notre code s'exécute normalement sur macOS et iOS sans compromis sur les performances sur les deux plates-formes. Nous avons fait de notre mieux pour maintenir la bibliothèque de code capable de se compiler et de s'exécuter sur les deux plates-formes. Nous veillons à maximiser le code partagé entre les différentes cibles et à réutiliser le code autant que possible.
Étant donné qu'un composant entièrement implémenté de la couche de réseau neuronal doit fournir un support avec une quantité raisonnable de paramètres qui rendent le composant suffisamment utilisable, la complexité des composants est en réalité assez impressionnante. Par exemple, la couche convolutive doit prendre en charge les paramètres intégrant le rembourrage, la foulée de dilatation, etc. et tous doivent être soigneusement pris en compte lors de la parallélisation qui permet d'obtenir des performances raisonnables. Nous avons construit quelques réseaux simples pour effectuer le test de régression. Les cas de test sont créés dans d'autres frameworks (principalement PyTorch et Keras) pour garantir que toute l'implémentation fonctionne correctement.
Swift a été développé pour la première fois en juillet 2010 et publié et open source en 2014. Bien que près de 4 ans se soient écoulés depuis sa publication, le manque de bibliothèque percutante reste un problème incontournable. Une raison quelconque a causé cette situation, le rôle dominant d'Apple et le caractère itératif rapide de Swift pourraient être à l'origine de ce phénomène. Certaines bibliothèques qui sont cruciales pour nous ne sont pas suffisamment puissantes ou fonctionnelles pour répondre à nos besoins, ou encore ne sont pas bien entretenues par le développeur individuel qui les a inventées. Nous avons passé beaucoup de temps à implémenter une Variable de classe de tenseurs qui fonctionne bien pour nos demandes.
En outre, c'est une autre raison d'entraver le développement d'un analyseur de modèle universel, car la fonction de gestion des fichiers et des chaînes a des capacités très limitées.
De plus, les outils de développement et de débogage sont essentiellement limités à Xcode, bien qu'il existe d'autres choix plus généraux pour nous, Xcode reste l'outil standard de facto pour notre développement.
Pour le réglage des performances des appareils mobiles, Apple ne fournit pas de spécifications matérielles détaillées pour son SoC, le nom marketing est largement utilisé par les médias et il est difficile de déduire quel est l'impact exact d'une fonctionnalité matérielle spécifique et d'affiner les performances de la mise en œuvre. .
Nous utilisons le langage de programmation Swift, en particulier Swift 4.2, qui est le dernier en date à ce jour ; Framework Metal 2 et certaines fonctions de bibliothèque fournies par Metal Performance Shader (fonctions essentiellement d'algèbre linéaire). Bien qu'Apple ait lancé le SDK CoreML au printemps 2017, intégrant une certaine prise en charge du réseau neuronal convolutif, nous ne les utilisons pas dans Corgy pour acquérir une expérience inestimable dans le développement d'une implémentation parallélisée des couches réseau et fournir des API succinctes et intuitives avec une bonne convivialité et une courbe d'apprentissage fluide. pour que les utilisateurs puissent migrer un modèle à partir d'autres frameworks sans effort.
Nos machines cibles sont tous les appareils exécutant macOS et iOS, tels que l'iMac, le MacBook, l'iPhone et l'iPad. Plus précisément, l'appareil doté de la plate-forme prenant en charge la bibliothèque d'algèbre linéaire MPS (c'est-à-dire après iOS 10.0 et macOS 10.13), ce qui signifie que l'iPhone a été lancé après l'iPhone 5, l'iPad a été lancé après l'iPad (4e génération) et l'iPod Touch (6e génération). sont pris en charge en tant que plate-forme iOS. La gamme de produits Mac bénéficie d'une couverture encore plus large, y compris les iMac produits après fin 2009 ou après, toutes les séries MacBook lancées après mi-2010 et l'iMac Pro.
L'abstraction parallèle de Metal 2 ressemble beaucoup à CUDA : lors de l'envoi du passage de l'ordinateur au GPU, les programmeurs écriront d'abord les fonctions du noyau qui seront exécutées par chaque thread, puis spécifieront le nombre de groupes de threads (alias bloc dans CUDA) dans la grille et nombre de threads dans chaque groupe de threads, Metal exécutera les noyaux sur cette grille, le noyau est implémenté dans un dialecte C++14 nommé Metal shading Language. À l’intérieur de chaque groupe de threads, il y a une unité plus petite appelée groupe SIMD, c’est-à-dire un groupe de threads partageant les mêmes instructions SIMD. Mais dans le cadre de notre mise en œuvre, il n’est pas nécessaire d’en tenir compte.
Metal fournit une API nommée MTLCommandBuffer qui stocke les commandes codées validées et exécutées par GPU. Chaque fois que nous souhaitons lancer une tâche à effectuer par GPU, les fonctions du noyau précompilées seraient codées dans des instructions GPU, intégrées dans le pipeline Metal shading et envoyées à MTLCommandBuffer. Le tampon métallique utilisé pour stocker le paramètre de calcul qui doit être transmis à l'appareil est également défini à ce stade. Ensuite, avec un nombre spécifié de groupes de threads et de threads par groupe, la commande gérée par le tampon de commande serait complètement codée et prête à être validée sur le périphérique. Le GPU planifiera la tâche et informera le thread CPU qui soumet le travail une fois l'exécution terminée.
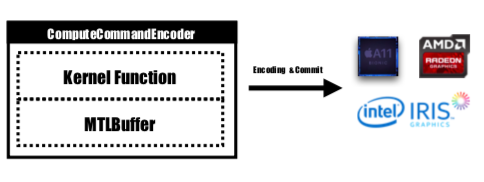
La fonction du noyau serait codée par MTLComputeCommandEncoder et la tâche serait créée pour toutes les plateformes prises en charge.
Dans notre implémentation, nous avons largement utilisé une manière intuitive de mapper l'élément dans des threads GPU : mapper chaque élément du tenseur de sortie de la couche actuelle à un thread GPU : chaque thread calcule et met à jour exactement un élément de la sortie, et l'entrée sera en lecture seule, nous n'avons donc pas à nous soucier de la synchronisation entre les threads. Dans le cadre de ce mappage, les threads avec des identifiants continus peuvent lire les données d'entrée à partir de différents emplacements de mémoire, mais écriront toujours dans des emplacements de mémoire continus. Il n'y aura donc pas d'opérations de dispersion lorsqu'un groupe SIMD écrit dans la mémoire.
Nous avons conçu une classe de tenseur Variable comme base de toute l'implémentation, nous avons utilisé et encapsulé l'opération d'algèbre linéaire dans la classe Variable au lieu d'écrire un noyau supplémentaire pour approfondir l'opération qui n'est pas notre objectif principal pour réduire la complexité de l'implémentation. et gagner du temps pour nous concentrer sur l'accélération des couches réseau.
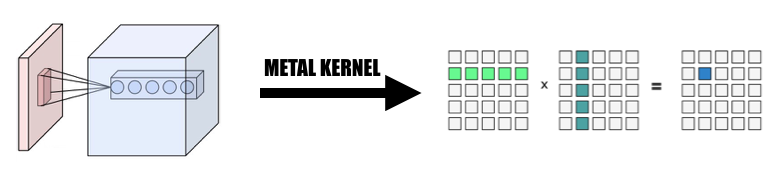
1. Changer la convolution en multiplication matricielle géante
Nous collectons les données de l'entrée de manière parallélisée pour former une matrice géante de la variable d'entrée et du poids. Nous mettons en cache le poids de chaque couche convolutive pour éviter tout recalcul. Le remplissage de la couche convolutive serait généré lors de la transformation de parallélisation pendant le calcul, puis nous invoquons le MPSMatrixMultiply dans la matrice géante et transformons les données de la matrice géante dans la classe de tenseurs normale que nous avons créée. La méthode est décrite dans les diapositives du cours.
2. La conception et la mise en œuvre de la classe Variable
La classe variable est le fondement de notre implémentation en tant que représentation tensorielle. Nous avons encapsulé le MPSMatrixMultiplication pour la variable (définissez le signe de multiplication Unicode (×) comme opérateur infixe pour le représenter avec élégance :-)).
La structure de données sous-jacente de la variable est un UnsafemutableBufferPointer qui pointe vers le type de données, nous avons choisi le Float 32 bits pour plus de simplicité. La classe Variable conservait deux tailles de données, le count contenait le numéro d'élément réellement stocké, le actualCount est la taille de tous les éléments arrondis à la taille de la page de la plate-forme obtenue en utilisant getpagesize() .
Nous maintenons ces deux valeurs pour nous assurer que makeBuffer(bytesNoCopy:) crée le tampon directement sur la région de VM spécifiée et évite les réallocations redondantes qui réduisent la surcharge. Si la mémoire à transmettre à Metal n'est pas alignée sur les pages, alors Metal ne pourra pas utiliser cette mémoire comme tampon d'entrée ou de sortie. Nous devrons utiliser la méthode makeBuffer(bytes:) , qui créera un nouveau tampon et copiera les données à partir de l'emplacement mémoire d'entrée. Nous devons donc toujours allouer plus de mémoire que nécessaire pour nous assurer que toutes les mémoires de Variable sont alignées sur les pages. Nous avons donc besoin de deux valeurs pour savoir quelle est exactement la taille de cette partie de mémoire et quelle taille devons-nous utiliser.
3. Nombre d'éléments traités par un seul thread
Nous avons essayé de mapper un thread sur plusieurs éléments, de 2 à 16 éléments par thread, les performances sont presque les mêmes mais une grande complexité est ajoutée à notre projet, nous avons donc abandonné cette approche.
Toutes les versions de processeur mentionnées ci-dessous sont du code CPU naïf à thread unique sans optimisation SIMD. L'optimisation du compilateur au niveau -Ofast est appliquée.
Les performances de notre implémentation sont bonnes, mais pas assez.
Nous avons utilisé l'iPhone 6s et un MacBook Pro 15 pouces comme plate-forme de référence. Le matériel est spécifié ci-dessous :
MacBook Pro (Retina 15 pouces, mi-2015)
iPhone6S
En comparaison avec l'implémentation naïve de la version CPU sans parallélisme, notre version GPU est plus de 60 fois plus rapide .
Le modèle MNIST étant trop petit, son résultat peut ne pas refléter l'accélération précise. Et nous n'avons pas de version monothread bien implémentée, nous ne pouvons pas donner un chiffre d'accélération précis. Parce que la version CPU est trop lente, l'accélération de Tiny YOLO est trop importante pour y croire.
Attribut du réseau de test :
MNIST :
YOLO :
Résultat de la mesure :
| iPhone6s | MNIST | Petit YOLO |
|---|---|---|
| Processeur | 1500 ms | 753 |
| GPU | 0,025s | 0,5 s |
| accélérer | ~60x | ~1500x |
| MacBook Pro | MNIST | Petit YOLO |
|---|---|---|
| Processeur | 650 ms | 729 |
| GPU | 10 ms | 0,028 s |
| accélérer | ~65x | ~26 000x |
Sur la base du benchmark ci-dessus, nous pouvons voir qu'à mesure que la taille du problème augmente,
Pourquoi disons-nous que notre accélération n’est pas suffisante ? Parce que si l'on compare avec l'implémentation officielle par Apple de MPSCNNConvolution , nous ne sommes qu'environ un tiers plus rapides, ce qui signifie qu'il reste encore beaucoup d'espace d'optimisation. Cette comparaison est basée sur une implémentation open source de YOLO sur iPhone utilisant MPSCNNConvolution officielle qui peut reconnaître environ 5 images par seconde alors que notre implémentation ne peut atteindre qu'environ 2 images par seconde.
Et en raison d'un temps limité, nous n'avons pas pu créer une meilleure version de base et une version parallélisée du processeur pour faire le test, ce qui rend le nombre d'accélération trop important.
Il convient également de signaler le gain de performances sur différentes tailles de problèmes. Comme nous pouvons le voir, MNIST n’a que 0,1 million de poids tandis que Tiny YOLO en a 17 millions. Le petit YOLO est bien plus complexe que MNIST, mais la durée d'exécution de la version GPU n'a pas beaucoup évolué. C'est encore une fois à cause de la loi d'Amdahl. À chaque lancement d'une tâche GPU, les commandes GPU correspondantes doivent être codées dans le tampon de commandes. Ce processus est intrinsèquement sériel. Lorsque la taille du problème est petite, ce processus contribue beaucoup au temps d'exécution total, donc en parallélisant l'étape d'inférence du réseau neuronal dans MINST peut ne pas obtenir la même vitesse que dans Tiny YOLO, où la surcharge de temps d'exécution est négligeable.
Qu'est-ce qui a limité votre accélération ?
if et for for qui peuvent provoquer des divergences, conduisant à une mauvaise utilisation du SIMD.Analyse plus approfondie : décomposition du temps d'exécution des différentes phases.
Prenons Tiny YOLO comme exemple, dans un exemple d'exécution avec une durée d'exécution totale de 227 ms sur Macbook, les couches convolutives ont utilisé 207 ms, soit 92 % de la durée d'exécution totale. Les couches Pooling utilisaient 14 ms (6 %) et ReLU utilisait 6 ms (2 %). Selon la loi d'Amdahl, si nous voulons améliorer encore les performances, nous devons absolument continuer à travailler sur la couche convolutive.
Dans l’ensemble, nous pensons que notre choix de framework Metal pour effectuer l’accélération du réseau neuronal sur les appareils iOS et macOS est judicieux, en particulier pour les appareils iOS. Comme elle comporte moins de cœurs, même avec les instructions SIMD, une version CPU bien réglée est moins susceptible d'obtenir des performances similaires à celles d'une version GPU.
Un travail égal est effectué par les deux membres de l’équipe.
1 https://developer.apple.com/metal/ ↩
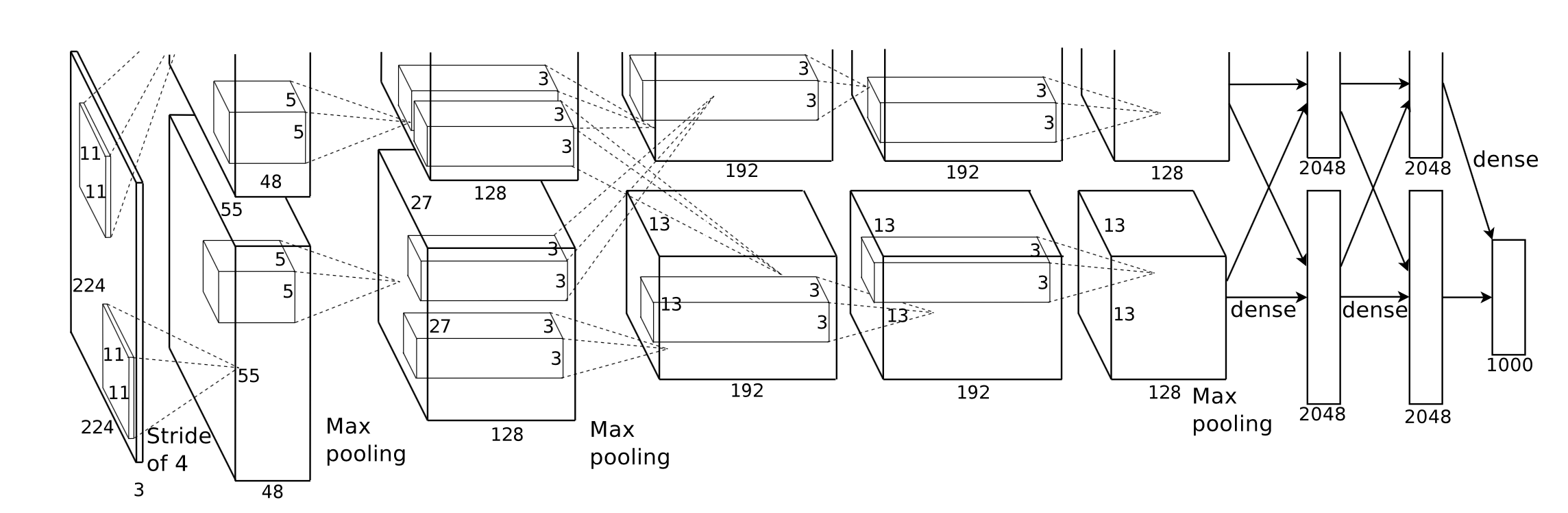
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


