Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript ?Browser sans têteLe scraping Web de la plupart des sites Web peut être relativement simple. Ce sujet est déjà abordé en détail dans ce tutoriel. Il existe cependant de nombreux sites qui ne peuvent pas être scrapés en utilisant la même méthode. La raison en est que ces sites chargent le contenu de manière dynamique à l'aide de JavaScript.
Cette technique est également connue sous le nom d'AJAX (Asynchronous JavaScript and XML). Historiquement, cette norme était incluse dans la création d'un objet XMLHttpRequest pour récupérer du XML à partir d'un serveur Web sans recharger la page entière. De nos jours, cet objet est rarement utilisé directement. Habituellement, un wrapper comme jQuery est utilisé pour récupérer du contenu tel que JSON, HTML partiel ou même des images.
Pour gratter une page Web standard, au moins deux bibliothèques sont requises. La bibliothèque requests télécharge la page. Une fois que cette page est disponible sous forme de chaîne HTML, l'étape suivante consiste à l'analyser en tant qu'objet BeautifulSoup. Cet objet BeautifulSoup peut ensuite être utilisé pour rechercher des données spécifiques.
Voici un exemple de script simple qui imprime le texte à l'intérieur de l'élément h1 avec id défini sur firstHeading .
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert EinsteinNotez que nous travaillons avec la version 4 de la bibliothèque Beautiful Soup. Les versions antérieures sont abandonnées. Vous verrez peut-être Beautiful Soup 4 être écrit simplement Beautiful Soup, BeautifulSoup ou même bs4. Ils font tous référence à la même belle bibliothèque Soup 4.
Le même code ne fonctionnera pas si le site est dynamique. Par exemple, le même site a une version dynamique sur https://quotes.toscrape.com/js/ (notez js à la fin de cette URL).
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output La raison en est que le deuxième site est dynamique et que les données sont générées à l'aide JavaScript .
Il existe deux manières de gérer des sites comme celui-ci.
Ces deux approches sont détaillées dans ce tutoriel.
Cependant, nous devons d’abord comprendre comment déterminer si un site est dynamique.
Voici le moyen le plus simple de déterminer si un site Web est dynamique à l'aide de Chrome ou Edge. (Ces deux navigateurs utilisent Chromium sous le capot).
Ouvrez les outils de développement en appuyant sur la touche F12 . Assurez-vous que l'accent est mis sur les outils de développement et appuyez sur la combinaison de touches CTRL+SHIFT+P pour ouvrir le menu de commande.
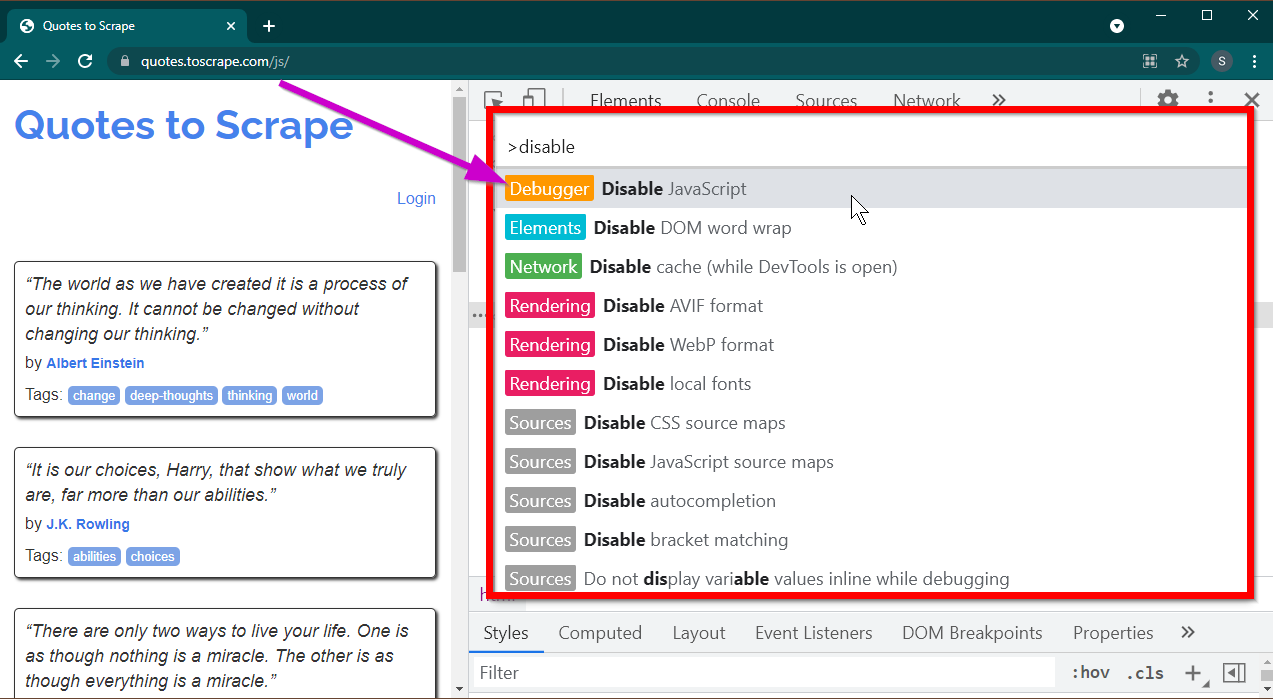
Il affichera beaucoup de commandes. Commencez à taper disable et les commandes seront filtrées pour afficher Disable JavaScript . Sélectionnez cette option pour désactiver JavaScript .
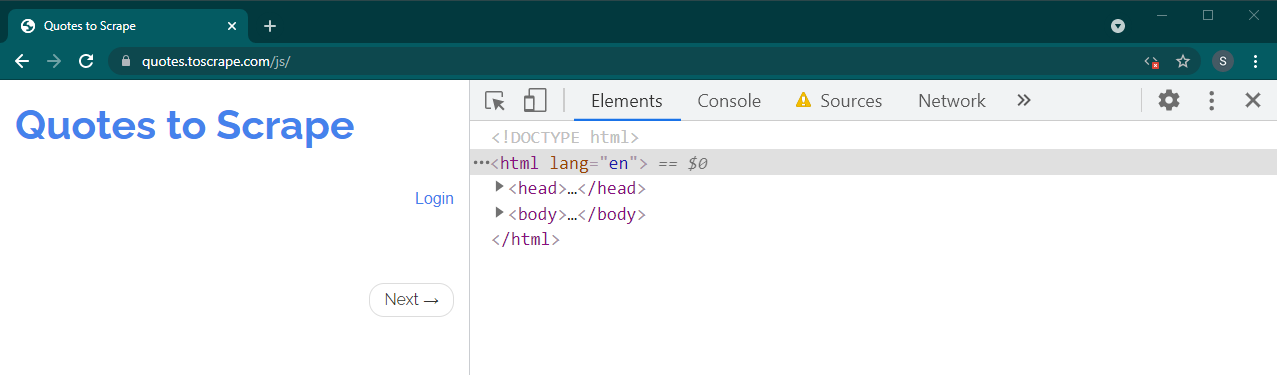
Rechargez maintenant cette page en appuyant sur Ctrl+R ou F5 . La page se rechargera.
S’il s’agit d’un site dynamique, une grande partie du contenu disparaîtra :
Dans certains cas, les sites afficheront toujours les données mais reviendront aux fonctionnalités de base. Par exemple, ce site a un défilement infini. Si JavaScript est désactivé, il affiche une pagination régulière.
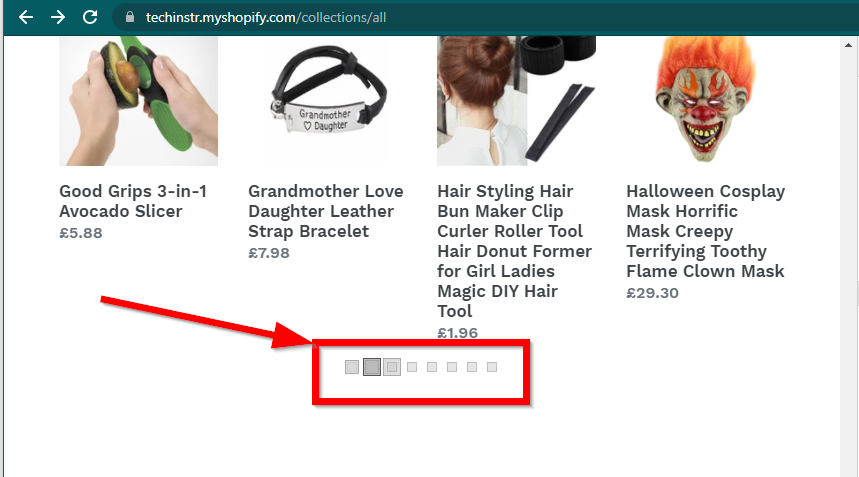 | 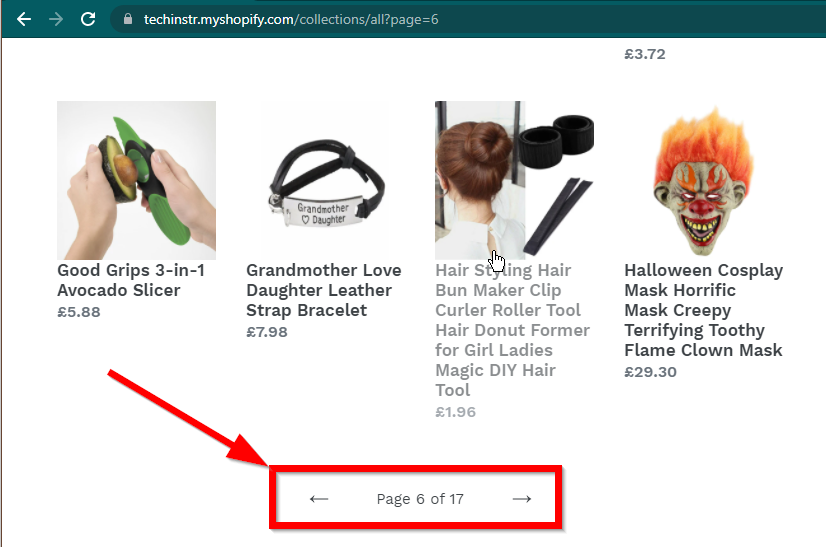 |
|---|---|
| JavaScript activé | JavaScript désactivé |
La prochaine question à laquelle il faut répondre concerne les capacités de BeautifulSoup.
JavaScript ?La réponse courte est non.
Il est important de comprendre des mots comme analyse et rendu. L'analyse consiste simplement à convertir une représentation sous forme de chaîne d'un objet Python en un objet réel.
Alors, qu’est-ce que le rendu ? Le rendu consiste essentiellement à interpréter le HTML, le JavaScript, le CSS et les images en quelque chose que nous voyons dans le navigateur.
Beautiful Soup est une bibliothèque Python permettant d'extraire des données de fichiers HTML. Cela implique d'analyser la chaîne HTML dans l'objet BeautifulSoup. Pour l’analyse, nous avons d’abord besoin du code HTML sous forme de chaîne. Les sites Web dynamiques n'ont pas les données directement dans le HTML. Cela signifie que BeautifulSoup ne peut pas fonctionner avec des sites Web dynamiques.
La bibliothèque Selenium peut automatiser le chargement et le rendu des sites Web dans un navigateur comme Chrome ou Firefox. Même si Selenium prend en charge l'extraction de données du HTML, il est possible d'extraire le HTML complet et d'utiliser Beautiful Soup à la place pour extraire les données.
Commençons par le scraping dynamique du Web avec Python en utilisant Selenium.
L'installation de Selenium implique l'installation de trois éléments :
Le navigateur de votre choix (que vous possédez déjà) :
Le pilote de votre navigateur :
Package Python Sélénium :
pip install seleniumconda-forge . conda install -c conda-forge selenium Le squelette de base du script Python pour lancer un navigateur, charger la page, puis fermer le navigateur est simple :
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()Maintenant que nous pouvons charger la page dans le navigateur, voyons comment extraire des éléments spécifiques. Il existe deux façons d’extraire les éléments : le sélénium et la belle soupe.
Notre objectif dans cet exemple est de trouver l'élément auteur.
Chargez le site https://quotes.toscrape.com/js/ dans Chrome, cliquez avec le bouton droit sur le nom de l'auteur et cliquez sur Inspecter. Cela devrait charger les outils de développement avec l'élément auteur mis en évidence comme suit :
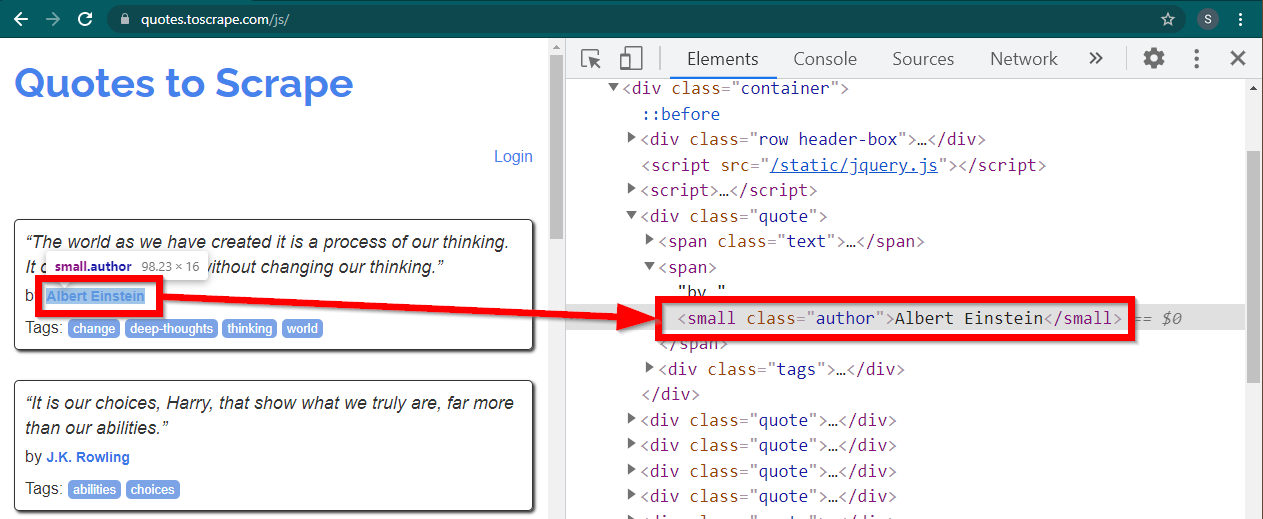
Il s'agit d'un small élément dont l'attribut class est défini sur author .
< small class =" author " > Albert Einstein </ small >Selenium permet diverses méthodes pour localiser les éléments HTML. Ces méthodes font partie de l'objet pilote. Certaines des méthodes qui peuvent être utiles ici sont les suivantes :
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )Il existe peu d'autres méthodes, qui peuvent être utiles pour d'autres scénarios. Ces méthodes sont les suivantes :
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" ) Les méthodes les plus utiles sont peut-être find_element(By.CSS_SELECTOR) et find_element(By.XPATH) . Chacune de ces deux méthodes devrait permettre de sélectionner la plupart des scénarios.
Modifions le code pour que le premier auteur puisse être imprimé.
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()Et si vous souhaitez imprimer tous les auteurs ?
Toutes les méthodes find_element ont une contrepartie - find_elements . Notez la pluralisation. Pour retrouver tous les auteurs, changez simplement une ligne :
elements = driver . find_elements ( By . CLASS_NAME , "author" )Cela renvoie une liste d'éléments. Nous pouvons simplement exécuter une boucle pour imprimer tous les auteurs :
for element in elements :
print ( element . text )Remarque : Le code complet se trouve dans le fichier de code selenium_example.py.
Cependant, si vous êtes déjà à l’aise avec BeautifulSoup, vous pouvez créer l’objet Beautiful Soup.
Comme nous l'avons vu dans le premier exemple, l'objet Beautiful Soup a besoin de HTML. Pour les sites statiques de web scraping, le HTML peut être récupéré à l’aide de la bibliothèque requests . L'étape suivante consiste à analyser cette chaîne HTML dans l'objet BeautifulSoup.
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )Découvrons comment gratter un site Web dynamique avec BeautifulSoup.
La partie suivante reste inchangée par rapport à l'exemple précédent.
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' ) Le HTML rendu de la page est disponible dans l'attribut page_source .
soup = BeautifulSoup ( driver . page_source , "lxml" )Une fois l’objet soupe disponible, toutes les méthodes Beautiful Soup peuvent être utilisées comme d’habitude.
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )Remarque : le code source complet se trouve dans selenium_bs4.py
Browser sans têteUne fois le script prêt, il n'est pas nécessaire que le navigateur soit visible lorsque le script est en cours d'exécution. Le navigateur peut être masqué et le script fonctionnera toujours correctement. Ce comportement d'un navigateur est également connu sous le nom de navigateur sans tête.
Pour rendre le navigateur sans tête, importez ChromeOptions . Pour les autres navigateurs, leurs propres classes d'options sont disponibles.
from selenium . webdriver import ChromeOptions Maintenant, créez un objet de cette classe et définissez l'attribut headless sur True.
options = ChromeOptions ()
options . headless = TrueEnfin, envoyez cet objet lors de la création de l'instance Chrome.
driver = Chrome ( ChromeDriverManager (). install (), options = options )Désormais, lorsque vous exécuterez le script, le navigateur ne sera plus visible. Voir le fichier selenium_bs4_headless.py pour l'implémentation complète.
Le chargement du navigateur coûte cher : il consomme du processeur, de la RAM et de la bande passante qui ne sont pas vraiment nécessaires. Lorsqu'un site Web est supprimé, ce sont les données qui sont importantes. Tous ces CSS, images et rendus ne sont pas vraiment nécessaires.
Le moyen le plus rapide et le plus efficace de supprimer des pages Web dynamiques avec Python consiste à localiser l'endroit réel où se trouvent les données.
Il existe deux endroits où ces données peuvent être localisées :
<script>Regardons quelques exemples.
Ouvrez https://quotes.toscrape.com/js dans Chrome. Une fois la page chargée, appuyez sur Ctrl+U pour afficher la source. Appuyez sur Ctrl+F pour afficher le champ de recherche, recherchez Albert.
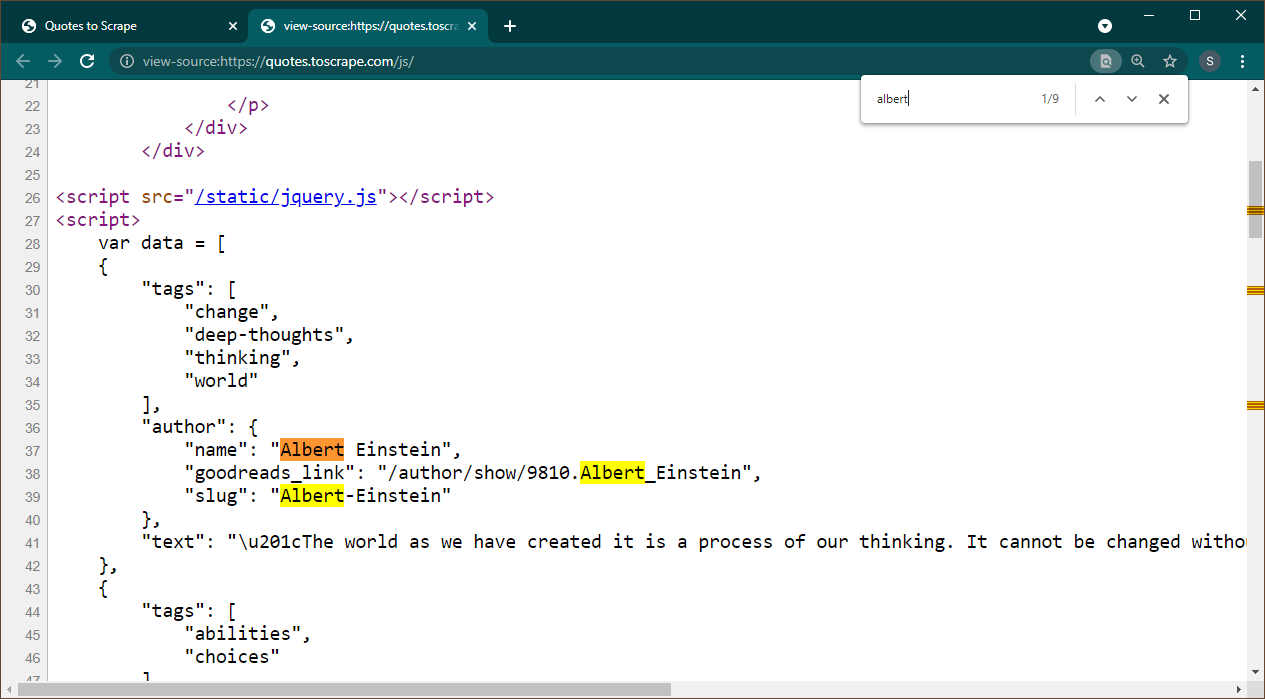
Nous pouvons immédiatement voir que les données sont intégrées en tant qu'objet JSON sur la page. Notez également que cela fait partie d'un script dans lequel ces données sont affectées à une variable data .
Dans ce cas, nous pouvons utiliser la bibliothèque Requests pour obtenir la page et utiliser Beautiful Soup pour analyser la page et obtenir l'élément de script.
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" ) Notez qu'il existe plusieurs éléments <script> . Celui qui contient les données dont nous avons besoin n’a pas d’attribut src . Utilisons ceci pour extraire l'élément de script.
script_tag = soup . find ( "script" , src = None )N'oubliez pas que ce script contient d'autres codes JavaScript que les données qui nous intéressent. Pour cette raison, nous allons utiliser une expression régulière pour extraire ces données.
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )La variable de données est une liste contenant un élément. Nous pouvons maintenant utiliser la bibliothèque JSON pour convertir ces données de chaîne en un objet Python.
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )La sortie sera l'objet python :
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................Cette liste ne peut être convertie dans aucun format selon les besoins. Notez également que chaque élément contient un lien vers la page de l'auteur. Cela signifie que vous pouvez lire ces liens et créer une araignée pour obtenir les données de toutes ces pages.
Ce code complet est inclus dans data_in_same_page.py.
Les sites dynamiques de web scraping peuvent suivre un chemin complètement différent. Parfois, les données sont chargées sur une page distincte. Un tel exemple est Librivox.
Ouvrez les outils de développement, accédez à l'onglet Réseau et filtrez par XHR. Maintenant, ouvrez ce lien ou recherchez n'importe quel livre. Vous verrez que les données sont un HTML intégré dans JSON.
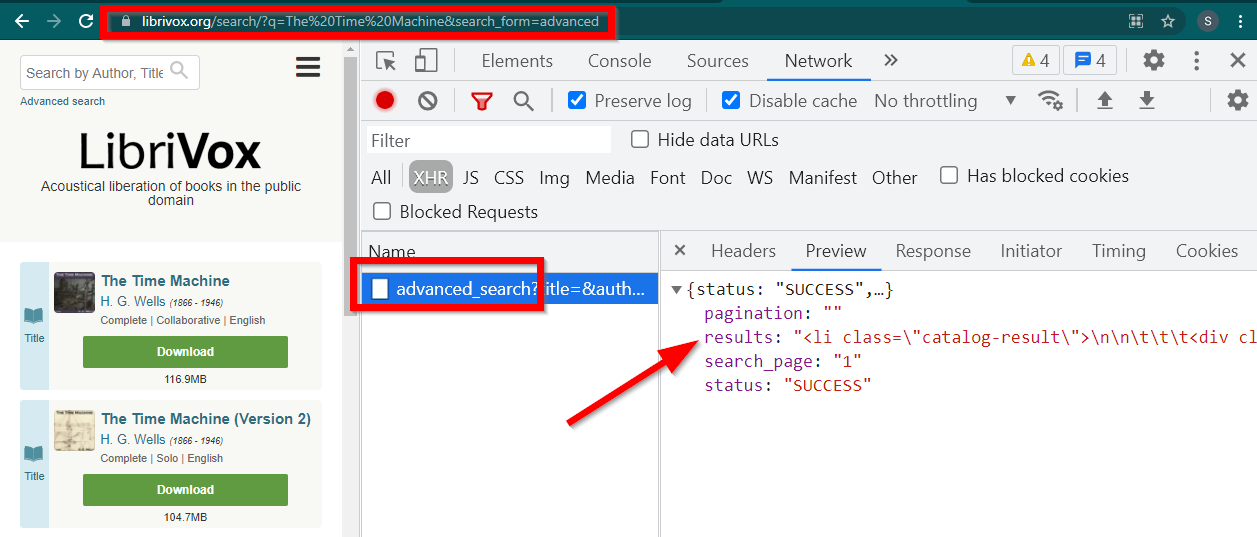
Notez quelques choses :
L'URL affichée par le navigateur est https://librivox.org/search/?q=...
Les données sont sur https://librivox.org/advanced_search?....
Si vous regardez les en-têtes, vous constaterez que la page advanced_search reçoit un en-tête spécial X-Requested-With: XMLHttpRequest
Voici un extrait pour extraire ces données :
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )Le code complet est inclus dans le fichier librivox.py.


