disclosure backend static
1.0.0
Le dépôt disclosure-backend-static est le backend qui alimente Open Disclosure California.
Il a été créé à la hâte avant les élections de 2016 et s'articule donc autour d'une philosophie « faites-le ». À cette époque, nous avions déjà conçu une API et construit (la plupart) un frontend ; ce dépôt a été créé pour les mettre en œuvre le plus rapidement possible.
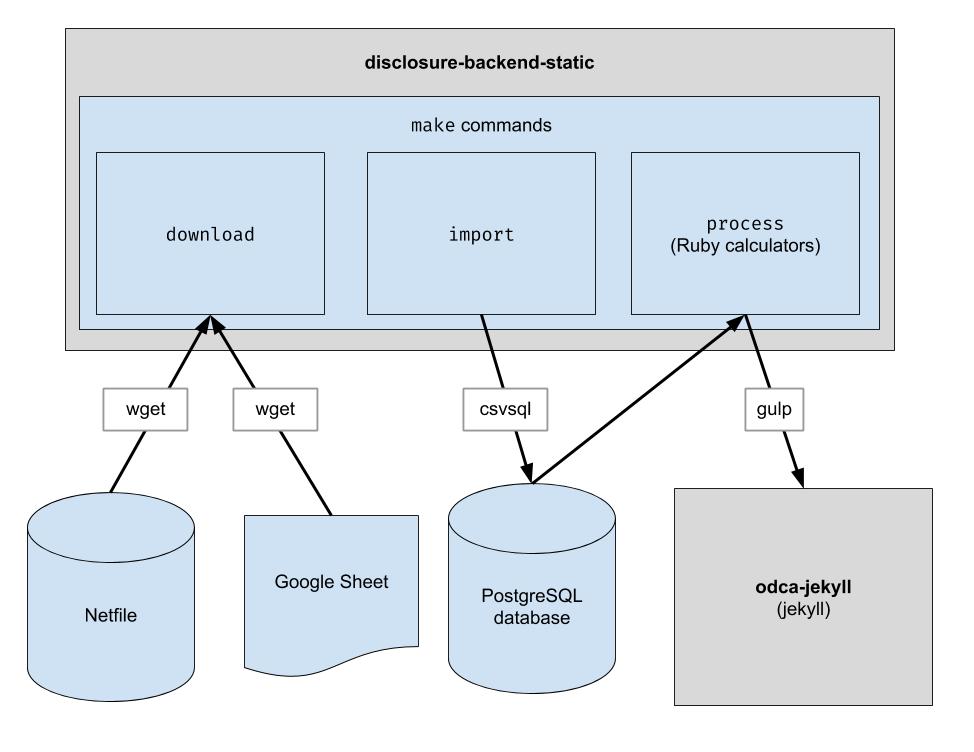
Ce projet implémente un pipeline ETL de base pour télécharger les données Netfile d'Oakland, télécharger les données CSV organisées par l'homme pour Oakland et combiner les deux. Le résultat est un répertoire de fichiers JSON qui imitent la structure de l'API existante afin qu'aucune modification du code client ne soit requise.
.ruby-version ) Remarque : Vous n'avez pas besoin d'exécuter ces commandes pour développer sur le frontend. Tout ce que vous avez à faire est de cloner le référentiel adjacent au dépôt frontend.
Si vous envisagez de modifier le code backend, suivez ces étapes pour configurer toutes les dépendances de développement nécessaires, y compris une nouvelle base de données PostgreSQL et Python 3 :
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
python3 -m pip au lieu de pip pour garantir que Python 3 est utilisé : python3 -m pip install ...
pip de votre système pointe vers Python 3, vous pouvez utiliser pip directement : pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
Ce référentiel est configuré pour fonctionner dans un conteneur sous Codespaces. En d’autres termes, vous pouvez démarrer un environnement déjà configuré sans avoir à effectuer aucune des étapes d’installation requises pour configurer un environnement local. Cela peut être utilisé comme moyen de dépanner le code avant qu’il ne soit validé dans le pipeline de production. Les informations suivantes peuvent être utiles pour commencer à utiliser Codespaces :
Code et cliquez sur l'onglet Codespaces dans la liste déroulante/workspace soit présentée dans la page Web, ce qui vous semblera familier si vous avez déjà travaillé avec VS Codemake downloadpsql dans le terminal pour vous connecter au serveur.make import remplira la base de données Postgresgit pushCe référentiel est également configuré pour s'exécuter dans un conteneur Docker. Ceci est similaire aux Codespaces, sauf que vous pouvez utiliser l'IDE et la configuration locale de votre choix. Voici comment commencer à utiliser Docker avec VSCode :
Téléchargez les fichiers de données brutes. Il vous suffit de l'exécuter de temps en temps pour obtenir les dernières données.
$ make download
Importez les données dans la base de données pour un traitement plus facile. Vous ne devez l'exécuter qu'après avoir téléchargé de nouvelles données.
$ make import
Exécutez les calculatrices. Tout est sorti dans le dossier "build".
$ make process
Éventuellement, réindexez les sorties de build dans Algolia. (La réindexation nécessite les variables d'environnement ALGOLIASEARCH_APPLICATION_ID et ALGOLIASEARCH_API_KEY).
$ make reindex
Si vous souhaitez diffuser les fichiers JSON statiques via un serveur Web local :
$ make run
Lorsque make import est exécuté, un certain nombre de tables postgres sont créées pour importer les données téléchargées. Le schéma de ces tables est explicitement défini dans le répertoire dbschema et devra peut-être être mis à jour à l'avenir pour prendre en compte les données futures. Les colonnes contenant des données de chaîne peuvent ne pas être suffisamment grandes pour les données futures. Par exemple, si une colonne de nom accepte des noms d'au plus 20 caractères et qu'à l'avenir, nous avons des données dont le nom comporte 21 caractères, l'importation des données échouera. Lorsque cela se produit, nous devrons mettre à jour le fichier de schéma correspondant dans dbschema pour prendre en charge davantage de caractères. Effectuez simplement la modification et réexécutez make import pour vérifier qu'elle réussit.
Ce référentiel est utilisé pour générer des fichiers de données utilisés par le site Web. Une fois make process exécuté, un répertoire build est généré contenant les fichiers de données. Ce répertoire est archivé dans le référentiel puis extrait lors de la génération du site Web. Après avoir apporté des modifications au code, il est important de comparer le répertoire build généré avec le répertoire build généré avant les modifications de code et de vérifier que les modifications apportées par les modifications de code sont conformes aux attentes.
Étant donné qu'une comparaison stricte de tout le contenu du répertoire build inclura toujours les modifications qui se produisent indépendamment de toute modification du code, chaque développeur doit connaître ces modifications attendues afin d'effectuer cette vérification. Pour supprimer ce besoin, un fichier spécifique, bin/create-digests.py , génère des résumés pour les données JSON dans le répertoire build après avoir exclu ces modifications attendues. Pour rechercher des modifications qui excluent ces modifications attendues, recherchez simplement une modification dans le fichier build/digests.json .
Actuellement, voici les changements attendus qui se produisent indépendamment de tout changement de code :
Les modifications attendues sont exclues avant de générer des résumés pour les données dans le répertoire build . La logique pour cela peut être trouvée dans la fonction clean_data , trouvée dans le fichier bin/create-digests.py . Une fois le code modifié de telle sorte qu'un changement attendu n'existe plus, l'exclusion de ce changement peut être supprimée de clean_data . Par exemple, l'arrondi des flottants n'est pas systématiquement le même à chaque fois que make process est exécuté, en raison des différences dans l'environnement. Lorsque le code est corrigé de manière à ce que l'arrondi des flottants soit le même tant que les données n'ont pas changé, l'appel round_float dans clean_data peut être supprimé.
Un script supplémentaire a été créé pour générer un rapport permettant de comparer les totaux des candidats. Le script est bin/report-candidates.py et génère build/candidates.csv et build/candidates.xlsx . Les rapports comprennent une liste de tous les candidats et des totaux calculés de plusieurs manières qui devraient donner le même nombre.
Pour garantir que les modifications du schéma de base de données sont visibles dans les demandes d'extraction, le schéma postgres complet est également enregistré dans un fichier schema.sql dans le répertoire build . Étant donné que le répertoire build est automatiquement reconstruit pour chaque branche d'un PR et validé dans le référentiel, toute modification du schéma provoquée par un changement de code affichera une différence dans le fichier schema.sql lors de l'examen du PR.
Chaque métrique concernant un candidat est calculée indépendamment. Une mesure peut être quelque chose comme « le total des contributions reçues » ou quelque chose de plus complexe comme « le pourcentage de contributions inférieures à 100 $ ».
Lorsque vous ajoutez un nouveau calcul, un bon premier point de départ est le formulaire officiel 460. Les données que vous recherchez sont-elles déclarées sur ce formulaire ? Si tel est le cas, vous le trouverez probablement dans votre base de données après le processus d'importation. Il existe également quelques autres formulaires que nous importons, comme le formulaire 496. (Ce sont les noms des fichiers dans le répertoire input . Vérifiez-les.)
Chaque planning de chaque formulaire est importé dans une table postgres distincte. Par exemple, l'annexe A du formulaire 460 est importée dans le tableau A-Contributions .
Maintenant que vous disposez d'un moyen d'interroger les données, vous devez créer une requête SQL qui calcule la valeur que vous essayez d'obtenir. Une fois que vous pouvez exprimer votre calcul en SQL, placez-le dans un fichier de calcul comme ceci :
calculators/[your_thing]_calculator.rb # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID .candidate.save_calculation . Cette méthode sérialisera son deuxième argument au format JSON, afin de pouvoir stocker tout type de données.candidate.calculation(:your_thing) . Vous souhaiterez l'ajouter à une réponse API dans le fichier process.rb . C’est ainsi que les données transitent par le back-end. Les données financières sont extraites de Netfile qui est complété par une feuille Google Mapper les identifiants de fichier pour les informations de vote telles que les noms des candidats, les fonctions, les mesures de vote, etc. Une fois les données filtrées, agrégées et transformées, le frontal les consomme et crée le code HTML statique. l'extrémité avant.
Pendant l'installation du bundle
error: use of undeclared identifier 'LZMA_OK'
Essayer:
brew unlink xz
bundle install
brew link xz
Pendant make download
wget: command not found
Exécutez brew install wget .
Pendant make import
Il semble qu'il y ait un problème sur les systèmes Macintosh utilisant les puces Apple.
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
Essayez ce qui suit :
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


