imagen pytorch
2.1.0
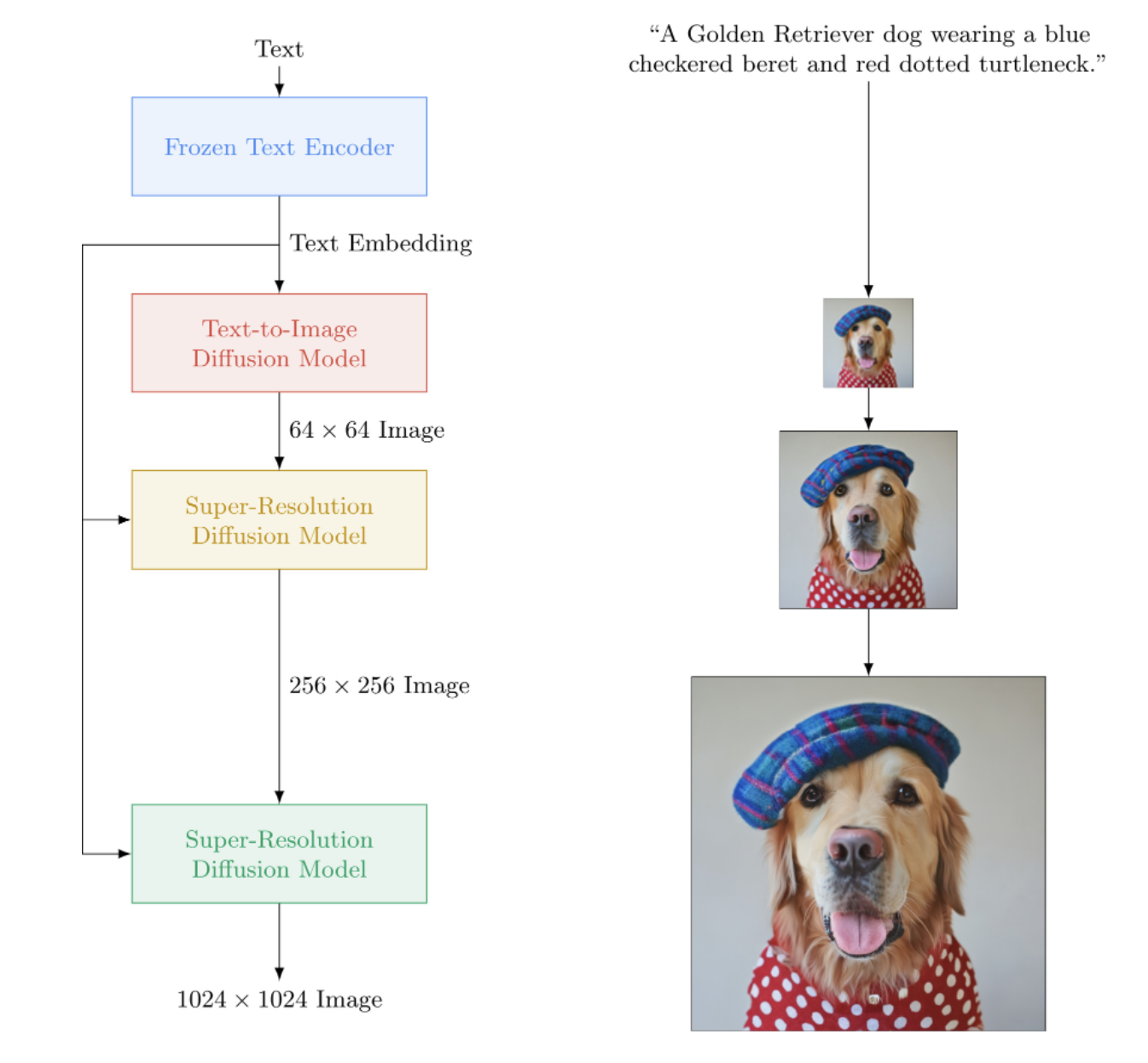
Implémentation d'Imagen, le réseau neuronal texte-image de Google qui bat DALL-E2, dans Pytorch. C'est le nouveau SOTA pour la synthèse texte-image.
Sur le plan architectural, c'est en réalité beaucoup plus simple que DALL-E2. Il s'agit d'un DDPM en cascade conditionné sur des intégrations de texte provenant d'un grand modèle T5 pré-entraîné (réseau d'attention). Il contient également un découpage dynamique pour un guidage amélioré sans classificateur, un conditionnement du niveau de bruit et une conception d'unité efficace en mémoire.
Il semble que ni CLIP ni réseau préalable ne soient nécessaires après tout. Et ainsi les recherches se poursuivent.
Pause-café IA avec Letitia | Assemblée IA | Yannic Kilcher
Veuillez nous rejoindre si vous souhaitez aider à la réplication avec la communauté LAION
StabilityAI pour son généreux parrainage, ainsi que mes autres sponsors
? Huggingface pour leur incroyable bibliothèque de transformateurs. La partie encodeur de texte est à peu près prise en charge grâce à eux
Jonathan Ho pour avoir révolutionné l'intelligence artificielle générative grâce à son article fondateur
Sylvain et Zachary pour la bibliothèque Accelerate, que ce référentiel utilise pour les formations distribuées
Alex pour einops, outil indispensable pour la manipulation tensorielle
Jorge Gomes pour son aide avec le code de chargement T5 et ses conseils sur la bonne version T5
Katherine Crowson, pour son magnifique code, qui m'a aidé à comprendre la version en temps continu de la diffusion gaussienne
Marunine et Netruk44, pour la révision du code, le partage des résultats expérimentaux et l'aide au débogage
Marunine pour avoir fourni une solution potentielle à un problème de changement de couleur dans les u-nets économes en mémoire. Merci à Jacob pour le partage de comparaisons expérimentales entre les unités de base et les unités économes en mémoire
Marunine pour avoir trouvé de nombreux bugs, résolu un problème avec le droit de redimensionnement et partagé ses configurations expérimentales et ses résultats
MalumaDev pour avoir proposé l'utilisation d'un suréchantillonneur de mélange de pixels pour corriger les artefacts du damier
Valentin pour avoir souligné l'insuffisance des connexions sautées dans l'unet, ainsi que la méthode spécifique de conditionnement de l'attention dans la base-unet en annexe
BIGJUN pour attraper un gros bug avec un conditionnement du niveau de bruit de diffusion gaussienne en temps continu au moment de l'inférence
Bingbing pour identifier un bug avec l'échantillonnage et l'ordre de normalisation et de bruit avec une image de conditionnement basse résolution
Kay pour sa contribution à la formation au commandement en ligne d'Imagen !
Hadrien Reynaud pour avoir testé le text-to-video sur un ensemble de données médicales, partagé ses résultats et identifié les problématiques !
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)Pour une formation plus simple, vous pouvez fournir directement des chaînes de texte au lieu de précalculer les encodages de texte. (Bien qu'à des fins de mise à l'échelle, vous souhaiterez certainement précalculer les intégrations textuelles + le masque)
Le nombre de légendes textuelles doit correspondre à la taille du lot des images si vous suivez cette voie.
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward () Avec la classe wrapper ImagenTrainer , les moyennes mobiles exponentielles de tous les U-nets du DDPM en cascade seront automatiquement prises en compte lors de l'appel update
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)Vous pouvez également entraîner Imagen sans texte (génération d'image inconditionnelle) comme suit
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)Ou entraînez uniquement des unités à super résolution
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256) À tout moment, vous pouvez enregistrer et charger le formateur et tous les états associés grâce aux méthodes save et load . Il est recommandé d'utiliser ces méthodes au lieu d'enregistrer manuellement avec un appel state_dict , car une certaine gestion de la mémoire de l'appareil est effectuée sous le capot de l'entraîneur.
ex.
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 Vous pouvez également compter sur ImagenTrainer pour entraîner automatiquement les instances DataLoader . Vous devez simplement créer votre DataLoader pour renvoyer soit images (dans le cas inconditionnel), soit des ('images', 'text_embeds') pour une génération guidée par texte.
ex. formation inconditionnelle
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )Merci à ? Accélérez, vous pouvez facilement effectuer une formation multi-GPU en deux étapes.
Vous devez d'abord appeler accelerate config dans le même répertoire que votre script de formation (disons qu'il s'appelle train.py )
$ accelerate config Ensuite, au lieu d'appeler python train.py comme vous le feriez pour un seul GPU, vous utiliseriez la CLI accélérée ainsi
$ accelerate launch train.pyC'est ça!
Imagen peut également être utilisé directement via CLI.
ex.
$ imagen configou
$ imagen config --path ./configs/config.jsonDans la configuration, vous pouvez modifier les paramètres du formateur, de l'ensemble de données et de la configuration de l'image.
Les paramètres de configuration d'Imagen peuvent être trouvés ici
Les paramètres de configuration Elucidated Imagen peuvent être trouvés ici
Les paramètres de configuration d'Imagen Trainer peuvent être trouvés ici
Pour les paramètres de l'ensemble de données, tous les paramètres du chargeur de données peuvent être utilisés.
Cette commande vous permet d'entraîner ou de reprendre l'entraînement de votre modèle
ex.
$ imagen trainou
$ imagen train --unet 2 --epoches 10Vous pouvez transmettre les arguments suivants à la commande de formation.
--config spécifie le fichier de configuration à utiliser pour la formation [par défaut : ./imagen_config.json]--unet l'index de l'unet à entraîner [par défaut : 1]--epoches combien d'époques pour lesquelles s'entraîner [par défaut : 50]Soyez conscient que lors de l'échantillonnage, votre point de contrôle doit avoir formé toutes les unités pour obtenir un résultat utilisable.
ex.
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.pngVous pouvez transmettre les arguments suivants à l’exemple de commande.
--model spécifie le fichier modèle à utiliser pour l'échantillonnage--cond_scale échelle de conditionnement (guidage sans classificateur) dans le décodeur--load_ema charge la version EMA des unets si disponible Afin d'utiliser un point de contrôle enregistré avec cette fonctionnalité, vous devez soit instancier votre instance Imagen à l'aide des classes de configuration, ImagenConfig et ElucidatedImagenConfig soit créer un point de contrôle directement via la CLI.
Pour une formation appropriée, vous souhaiterez probablement de toute façon configurer une formation basée sur la configuration.
ex.
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminalCela devrait vraiment être aussi simple que ça
Vous pouvez également transmettre ce fichier de point de contrôle, et n'importe qui peut continuer à affiner ses propres données.
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning Inpainting suit la formulation présentée dans le récent article Repaint. Transmettez simplement inpaint_images et inpaint_masks à l' sample de fonction sur Imagen ou ElucidatedImagen
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512) Pour la vidéo, transmettez de la même manière vos vidéos au mot-clé inpaint_videos sur .sample . Le masque d'inpainting peut être soit le même sur tous les cadres (batch, height, width) , soit différent (batch, frames, height, width)
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) Tero Karras de StyleGAN a écrit un nouvel article dont les résultats ont été corroborés par un certain nombre de chercheurs indépendants ainsi que sur ma propre machine. J'ai décidé de créer une version d' Imagen , la ElucidatedImagen , afin que l'on puisse utiliser le nouveau DDPM élucidé pour la génération en cascade guidée par texte.
Importez simplement ElucidatedImagen , puis instanciez l'instance comme vous l'avez fait auparavant. Les hyperparamètres sont différents de ceux habituels pour la diffusion gaussienne à temps discret et continu, et peuvent être individualisés pour chaque unité de la cascade.
Ex.
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above Ce référentiel commencera également à accumuler de nouvelles recherches autour de la synthèse vidéo guidée par texte. Pour commencer, il adoptera l'architecture 3D Unet décrite par Jonathan Ho dans Video Diffusion Models
Mise à jour : fonctionnement vérifié par Hadrien Reynaud !
Ex.
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32) Vous pouvez également vous entraîner sur les paires texte – image en premier. L' Unet3D le convertira automatiquement en vidéos à image unique et apprendra sans les composants temporels (en définissant automatiquement ignore_time = True ), qu'il s'agisse de convolutions 1D ou d'une attention causale dans le temps.
C’est l’approche actuelle adoptée par tous les grands laboratoires d’intelligence artificielle (Brain, MetaAI, Bytedance)
Imagen utilise un algorithme appelé Classifier Free Guidance. Lors de l'échantillonnage, vous appliquez une échelle au conditionnement (texte dans ce cas) supérieure à 1.0 .
Le chercheur Netruk44 a rapporté que 5-10 était optimal, mais que tout ce qui est supérieur à 10 devait être dépassé.
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than averagePas pour le moment, mais l'un d'entre eux sera probablement formé et open source d'ici un an, voire plus tôt. Si vous souhaitez participer, vous pouvez rejoindre la communauté des formateurs de réseaux de neurones artificiels de Laion (le lien Discord se trouve dans le fichier Lisezmoi ci-dessus) et commencer à collaborer.
C'est davantage la raison pour laquelle vous devriez commencer à entraîner votre propre modèle, à partir d'aujourd'hui ! La dernière chose dont nous avons besoin est que cette technologie soit entre les mains d’une élite. Espérons que ce référentiel réduise le travail à la simple recherche du calcul nécessaire et à l'augmentation avec votre propre ensemble de données organisé.
Rien! Il est sous licence MIT. En d’autres termes, vous pouvez librement copier/coller pour votre propre recherche, remixé selon n’importe quelle modalité à laquelle vous pouvez penser. Allez former des modèles étonnants dans un but lucratif, pour la science ou simplement pour assouvir votre plaisir personnel d'assister à quelque chose de divin se dérouler devant vous.
Synthèse d'échocardiogramme [Code]
Synthèse de matrice de contact SOTA Hi-C [Code]
Génération de plan d'étage
Lames d'histopathologie ultra haute résolution
Images laparoscopiques synthétiques
Concevoir des métamatériaux
Diffusion audio de Flavio Schneider
Mini-image de Ryan O. | Rédaction de AssemblyAI
utiliser des transformateurs Huggingface pour les intégrations de texte de petite taille T5
ajouter un seuil dynamique
ajouter également le seuil dynamique DALLE2 et le référentiel de diffusion vidéo
permettre de régler T5-large (et peut-être une petite méthode d'usine pour intégrer n'importe quel transformateur à visage étreignant)
ajoutez le niveau de bruit lowres avec le pseudocode en annexe et déterminez quel est ce balayage qu'ils font au moment de l'inférence
portage sur un code de formation de DALLE2
il faut pouvoir utiliser un programme de bruit différent par unet (le cosinus a été utilisé pour la base, mais linéaire pour SR)
il suffit de créer une unet configurable par le maître
bloc resnet complet (inspiré de biggan ? mais avec groupnorm) - attention personnelle complète
bloc d'encastrement de conditionnement complet (et le rendre complètement configurable, que ce soit une attention, un film etc)
envisagez d'utiliser percevoir-resampler de https://github.com/lucidrains/flamingo-pytorch à la place du regroupement d'attention
ajouter une option de mutualisation de l'attention, en plus de l'attention croisée et du film
ajouter un programme facultatif de désintégration du cosinus avec échauffement, pour chaque unité, à l'entraîneur
passer à des pas de temps continus au lieu de discrétisés, car il semble que ce soit ce qu'ils ont utilisé pour toutes les étapes - déterminez d'abord le cas du programme de bruit linéaire à partir de l'article variationnel ddpm https://openreview.net/forum?id=2LdBqxc1Yv
déterminez le journal (snr) pour le programme de bruit alpha cosinus.
supprimer l'avertissement des transformateurs car seul l'encodeur T5 est utilisé
permettre le réglage de l'utilisation de l'attention linéaire sur les calques où toute l'attention ne peut pas être utilisée
forcer les unités dans le cas du temps continu à utiliser des conditions non fourierées (passez simplement le journal (snr) via un MLP avec des normes de couche facultatives), car c'est ce que je travaille localement
suppression de la variance apprise
ajouter une pondération de perte p2 pour le temps continu
assurez-vous que ddpm en cascade peut être entraîné sans condition de texte et assurez-vous que la diffusion gaussienne à temps continu et discret fonctionne
utilisez les conversions en profondeur de l'amorce sur les projections qkv en attention linéaire (ou utilisez le déplacement de jeton avant les projections) - utilisez également le nouveau dropout proposé par bayesformer, car il semble bien fonctionner avec une attention linéaire
explorer l'excitation de la couche sautée dans le décodeur unet
accélérer l'intégration
créer un outil CLI et une génération d'image sur une seule ligne
éliminer tous les problèmes résultant de l'accélération
ajouter une capacité d'inpainting à l'aide d'un rééchantillonneur à partir du papier de repeinture https://arxiv.org/abs/2201.09865
construire un système de points de contrôle simple, soutenu par un dossier
ajouter une connexion de saut à partir des sorties de tous les blocs de suréchantillonnage, utilisés dans le papier quadrillé Unet et dans certains travaux Unet précédents
ajoutez fsspec, recommandé par Romain @rom1504, pour la persistance agnostique des points de contrôle dans le cloud/système de fichiers local
testez la persistance dans gcs avec https://github.com/fsspec/gcsfs
étendre à la génération vidéo, en utilisant l'attention temporelle axiale comme dans l'article vidéo ddpm de Ho
permettre à l'image élucidée de se généraliser à n'importe quelle forme
permettre à l'image de se généraliser à n'importe quelle forme
ajouter un biais de position dynamique pour le meilleur type d'extrapolation de longueur sur toute la durée de la vidéo
déplacer les images vidéo vers la fonction d'échantillonnage, car nous tenterons une extrapolation temporelle
le biais d'attention sur les clés/valeurs nulles doit être un scalaire appris de la dimension de la tête
ajouter l'autoconditionnement à partir du papier de diffusion de bits, déjà codé sur ddpm-pytorch
ajouter le paramétrage v (https://arxiv.org/abs/2202.00512) à partir du papier vidéo imagen, la seule chose nouvelle
intégrer tous les apprentissages de make-a-video (https://makeavideo.studio/)
créer un outil CLI pour la formation, en reprenant la formation à partir du fichier de configuration
permettre une interpolation temporelle à des étapes spécifiques
assurez-vous que l'interpolation temporelle fonctionne avec l'inpainting
assurez-vous que l'on peut personnaliser tous les modes d'interpolation (certains chercheurs trouvent de meilleurs résultats avec le trilinéaire)
imagen-video : permet de conditionner les images précédentes (et éventuellement futures) de vidéos. ignorer le temps ne devrait pas être autorisé dans ce scénario
assurez-vous de prendre automatiquement en charge le sous-échantillonnage/suréchantillonnage temporel pour le conditionnement des images vidéo, mais autorisez une option pour le désactiver
assurez-vous que l'inpainting fonctionne avec la vidéo
assurez-vous que le masque d'inpainting pour la vidéo peut être personnalisé par image
ajouter une attention flash
relisez cogvideo et découvrez comment le conditionnement de la fréquence d'images pourrait être utilisé
apporter une expertise en matière d'attention aux couches d'auto-attention dans unet3d
envisager d'attirer l'attention convolutive 3D de NUWA
considérer les mémoires Transformer-XL dans les blocs d'attention temporelle
envisager une approche perceptive-ar pour s'occuper du temps passé
abandons de cadre pendant l'attention pour obtenir à la fois un effet de régularisation et un temps d'entraînement raccourci
enquêtez sur les affirmations de Frank Wood https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch et ajoutez la technique d'échantillonnage hiérarchique ou informez les gens de ses lacunes
proposer un mnist en mouvement stimulant (avec des objets de distraction) comme ligne de base pouvant être entraînée sur une seule ligne pour que les chercheurs puissent bifurquer pour passer du texte à la vidéo
préencodage du texte dans des intégrations memmappées
être capable de créer des itérateurs de chargeur de données basés sur l'ancien style d'époque, également de configurer la lecture aléatoire, etc.
pouvoir également transmettre des arguments (au lieu d'exiger que forward soit tous les arguments de mots-clés sur le modèle)
apporter des blocs réversibles de revnets pour unet 3D, pour réduire la charge de mémoire
ajouter la possibilité de former uniquement un réseau super-résolution
lire dpm-solver pour voir s'il est applicable à la diffusion gaussienne en temps continu
permettre le conditionnement d'images vidéo avec des temps absolus arbitraires (calculer le RPE pendant l'attention temporelle)
accueillir le réglage fin du stand de rêve
ajouter une inversion textuelle
auto-conditionnement du nettoyage à extraire lors de l'instanciation de l'image
assurez-vous qu'un éventuel dreambooth fonctionne avec imagen-video
ajouter un conditionnement de framerate pour la diffusion vidéo
assurez-vous que l'on peut conditionner simultanément les images vidéo en guise d'invite, ainsi qu'une image de conditionnement sur toutes les images
tester et ajouter une technique de distillation à partir de modèles de cohérence
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

