PaLM rlhf pytorch
0.3.9
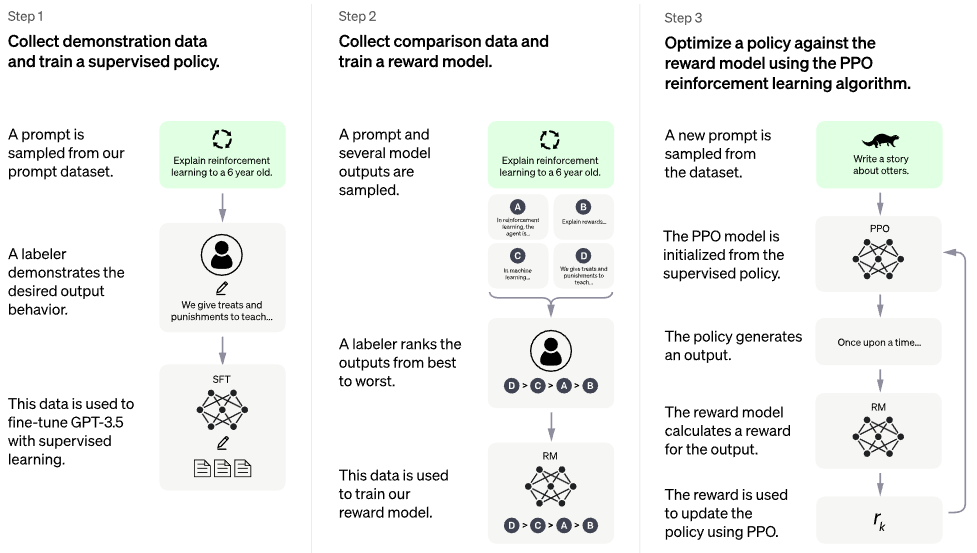
article de blog officiel de chatgpt
Implémentation du RLHF (Reinforcement Learning with Human Feedback) au-dessus de l'architecture PaLM. Peut-être que j'ajouterai aussi une fonctionnalité de récupération, à la RETRO
Si vous souhaitez reproduire ouvertement quelque chose comme ChatGPT, envisagez de rejoindre Laion.
Successeur potentiel : optimisation directe des préférences - tout le code de ce référentiel devient ~ perte d'entropie croisée binaire, < 5 loc. Voilà pour les modèles de récompense et les PPO
Il n’y a pas de modèle formé. Ceci est juste le navire et la carte globale. Nous avons encore besoin de millions de dollars de calcul et de données pour naviguer vers le bon point dans l’espace des paramètres de grande dimension. Même dans ce cas, vous avez besoin de marins professionnels (comme Robin Rombach de la renommée Stable Diffusion) pour guider le navire à travers les périodes de turbulences jusqu'à ce point.
CarperAI travaillait sur un framework RLHF pour les grands modèles de langage depuis plusieurs mois avant la sortie de ChatGPT.
Yannic Kilcher travaille également sur une implémentation open source
AI Coffeebreak avec Letitia | Magasin de codes | Code Emporium Partie 2
Stability.ai pour son généreux parrainage visant à mener des recherches de pointe sur l'intelligence artificielle
? Hugging Face et CarperAI pour avoir écrit le billet de blog Illustrating Reinforcement Learning from Human Feedback (RLHF), et le premier également pour leur bibliothèque accélérée
@kisseternity et @taynoel84 pour la révision du code et la recherche de bugs
Enrico pour l'intégration de Flash Attention de Pytorch 2.0
$ pip install palm-rlhf-pytorch Entraînez d'abord PaLM , comme tout autre transformateur autorégressif
import torch
from palm_rlhf_pytorch import PaLM
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
flash_attn = True # https://arxiv.org/abs/2205.14135
). cuda ()
seq = torch . randint ( 0 , 20000 , ( 1 , 2048 )). cuda ()
loss = palm ( seq , return_loss = True )
loss . backward ()
# after much training, you can now generate sequences
generated = palm . generate ( 2048 ) # (1, 2048) Entraînez ensuite votre modèle de récompense, avec les commentaires humains sélectionnés. Dans l'article original, ils ne pouvaient pas affiner le modèle de récompense à partir d'un transformateur pré-entraîné sans surajustement, mais j'ai quand même donné la possibilité d'affiner avec LoRA , car il s'agit toujours d'une recherche ouverte.
import torch
from palm_rlhf_pytorch import PaLM , RewardModel
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
causal = False
)
reward_model = RewardModel (
palm ,
num_binned_output = 5 # say rating from 1 to 5
). cuda ()
# mock data
seq = torch . randint ( 0 , 20000 , ( 1 , 1024 )). cuda ()
prompt_mask = torch . zeros ( 1 , 1024 ). bool (). cuda () # which part of the sequence is prompt, which part is response
labels = torch . randint ( 0 , 5 , ( 1 ,)). cuda ()
# train
loss = reward_model ( seq , prompt_mask = prompt_mask , labels = labels )
loss . backward ()
# after much training
reward = reward_model ( seq , prompt_mask = prompt_mask ) Ensuite vous transmettrez votre transformateur et le modèle de récompenses au RLHFTrainer
import torch
from palm_rlhf_pytorch import PaLM , RewardModel , RLHFTrainer
# load your pretrained palm
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12
). cuda ()
palm . load ( './path/to/pretrained/palm.pt' )
# load your pretrained reward model
reward_model = RewardModel (
palm ,
num_binned_output = 5
). cuda ()
reward_model . load ( './path/to/pretrained/reward_model.pt' )
# ready your list of prompts for reinforcement learning
prompts = torch . randint ( 0 , 256 , ( 50000 , 512 )). cuda () # 50k prompts
# pass it all to the trainer and train
trainer = RLHFTrainer (
palm = palm ,
reward_model = reward_model ,
prompt_token_ids = prompts
)
trainer . train ( num_episodes = 50000 )
# then, if it succeeded...
# generate say 10 samples and use the reward model to return the best one
answer = trainer . generate ( 2048 , prompt = prompts [ 0 ], num_samples = 10 ) # (<= 2048,) transformateur de base clone avec lora séparé pour critique
permettent également un réglage fin non basé sur LoRA
refaire la normalisation pour pouvoir avoir une version masquée, je ne sais pas si quelqu'un utilisera un jour les récompenses/valeurs par jeton, mais bonne pratique à mettre en œuvre
équiper avec la meilleure attention
ajoutez l'accélération de Hugging Face et testez l'instrumentation wandb
recherchez la littérature pour déterminer quelle est la dernière SOTA pour PPO, en supposant que le domaine RL continue de progresser.
tester le système en utilisant un réseau de sentiments pré-entraîné comme modèle de récompense
écrire la mémoire dans PPO dans le fichier numpy mémmappé
faire fonctionner l'échantillonnage avec des invites de longueur variable, même si cela n'est pas nécessaire étant donné que le goulot d'étranglement est la rétroaction humaine
permettre d'affiner l'avant-dernière couche N uniquement chez l'acteur ou le critique, en supposant qu'elle soit pré-entraînée
intégrer quelques points d'apprentissage de Sparrow, compte tenu de la vidéo de Letitia
interface Web simple avec Django + HTML pour collecter les commentaires humains
pensez au RLAIF
@article { Stiennon2020LearningTS ,
title = { Learning to summarize from human feedback } ,
author = { Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan J. Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul Christiano } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2009.01325 }
} @inproceedings { Chowdhery2022PaLMSL ,
title = { PaLM: Scaling Language Modeling with Pathways } ,
author = {Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam M. Shazeer and Vinodkumar Prabhakaran and Emily Reif and Nan Du and Benton C. Hutchinson and Reiner Pope and James Bradbury and Jacob Austin and Michael Isard and Guy Gur-Ari and Pengcheng Yin and Toju Duke and Anselm Levskaya and Sanjay Ghemawat and Sunipa Dev and Henryk Michalewski and Xavier Garc{'i}a and Vedant Misra and Kevin Robinson and Liam Fedus and Denny Zhou and Daphne Ippolito and David Luan and Hyeontaek Lim and Barret Zoph and Alexander Spiridonov and Ryan Sepassi and David Dohan and Shivani Agrawal and Mark Omernick and Andrew M. Dai and Thanumalayan Sankaranarayana Pillai and Marie Pellat and Aitor Lewkowycz and Erica Oliveira Moreira and Rewon Child and Oleksandr Polozov and Katherine Lee and Zongwei Zhou and Xuezhi Wang and Brennan Saeta and Mark Diaz and Orhan Firat and Michele Catasta and Jason Wei and Kathleen S. Meier-Hellstern and Douglas Eck and Jeff Dean and Slav Petrov and Noah Fiedel},
year = { 2022 }
} @article { Hu2021LoRALA ,
title = { LoRA: Low-Rank Adaptation of Large Language Models } ,
author = { Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09685 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Yuan2024FreePR ,
title = { Free Process Rewards without Process Labels } ,
author = { Lifan Yuan and Wendi Li and Huayu Chen and Ganqu Cui and Ning Ding and Kaiyan Zhang and Bowen Zhou and Zhiyuan Liu and Hao Peng } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:274445748 }
}

