enhancr
Release - 0.9.9 +

enhancr est une interface graphique élégante et facile à utiliser pour l'interpolation d'images vidéo et la mise à l'échelle vidéo qui tire parti de l'intelligence artificielle construite à l'aide de node.js et Electron . Il a été créé pour améliorer l'expérience utilisateur de toute personne souhaitant améliorer des séquences vidéo à l'aide de l'intelligence artificielle. L'interface graphique a été conçue pour offrir une expérience époustouflante, alimentée par des technologies de pointe, sans paraître encombrante et obsolète comme les autres alternatives.
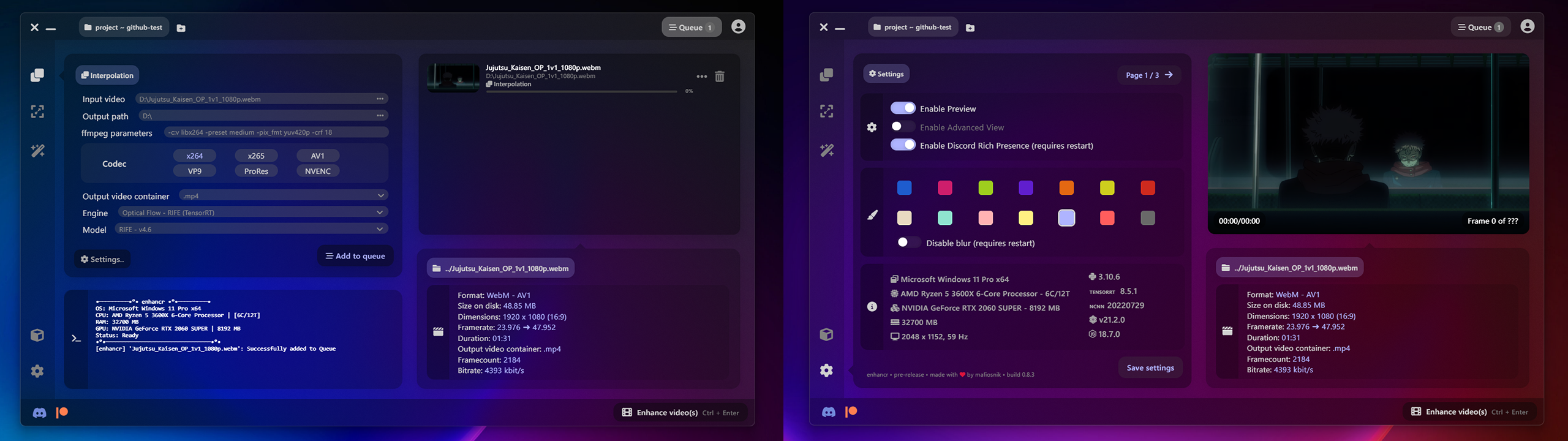
Il intègre une inférence TensorRT ultra-rapide de NVIDIA, qui peut accélérer considérablement les processus d'IA. Pré-emballé, sans avoir besoin d'installer Docker ou WSL (sous-système Windows pour Linux) - et l'inférence NCNN de Tencent qui est légère et fonctionne sur NVIDIA , AMD et même Apple Silicon - contrairement au mammouth d'une inférence PyTorch, qui fonctionne uniquement sur les GPU NVIDIA .
La version 0.9.9 propose une version gratuite ? https://dl.enhancr.app/setup/enhancr-setup-free-0.9.9.exe
Pour vous assurer que vous disposez de la version la plus récente du logiciel et de toutes les dépendances nécessaires, nous vous recommandons de télécharger le programme d'installation depuis Patreon. Veuillez noter que les builds et un environnement Python intégrable pour la version Pro ne sont pas fournis via ce référentiel.
RIFE (NCNN) - megvii-research/ ECCV2022-RIFE - propulsé par styler00dollar/ VapourSynth-RIFE-NCNN-Vulkan
RIFE (TensorRT) - megvii-research/ ECCV2022-RIFE - propulsé par AmusementClub/ vs-mlrt & styler00dollar/ VSGAN-tensorrt-docker
GMFSS - Union (PyTorch/TensorRT) - 98mxr/ GMFSS_Union - propulsé par HolyWu/ vs-gmfss_union
GMFSS - Fortuna (PyTorch/TensorRT) - 98mxr/ GMFSS_Fortuna - propulsé par HolyWu/ vs-gmfss_fortuna
CAIN (NCNN) - myungsub/ CAIN - propulsé par mafiosnik/ vsynth-cain-NCNN-vulkan (inédit)
CAIN (DirectML) - myungsub/ CAIN - propulsé par AmusementClub/ vs-mlrt
CAIN (TensorRT) - myungsub/ CAIN - propulsé par HubertSotnowski/ cain-TensorRT
ShuffleCUGAN (NCNN) - styler00dollar/ VSGAN-tensorrt-docker - propulsé par AmusementClub/ vs-mlrt
ShuffleCUGAN (TensorRT) - styler00dollar/ VSGAN-tensorrt-docker - propulsé par AmusementClub/ vs-mlrt
RealESRGAN (NCNN) - xinntao/ Real-ESRGAN - propulsé par AmusementClub/ vs-mlrt
RealESRGAN (DirectML) - xinntao/ Real-ESRGAN - propulsé par AmusementClub/ vs-mlrt
RealESRGAN (TensorRT) - xinntao/ Real-ESRGAN - propulsé par AmusementClub/ vs-mlrt
RealCUGAN (TensorRT) - bilibili/ ailab/Real-CUGAN - propulsé par AmusementClub/ vs-mlrt
SwinIR (TensorRT) - JingyunLiang/ SwinIR - propulsé par mafiosnik777/ SwinIR-TensorRT (inédit)
DPIR (DirectML) - cszn/ DPIR - optimisé par AmusementClub/ vs-mlrt
DPIR (TensorRT) - cszn/ DPIR - optimisé par AmusementClub/ vs-mlrt
SCUNet (TensorRT) - cszn/ SCUNet - propulsé par mafiosnik777/ SCUNet-TensorRT (inédit)
Remarque : à partir de TensorRT 8.6, la prise en charge de Kepler et Maxwell de 2e génération (série 900 et versions antérieures) a été abandonnée. Vous aurez besoin d'au moins un GPU Pascal (série 1000 et plus) et CUDA 12.0 + version du pilote >= 525.xx pour exécuter l'inférence à l'aide de TensorRT.
L'interface graphique a été créée dans un souci de compatibilité multiplateforme et est compatible avec les deux systèmes d'exploitation. Notre objectif principal pour le moment est de garantir une solution stable et pleinement fonctionnelle pour les utilisateurs Windows, mais la prise en charge de Linux et macOS sera disponible avec la mise à jour 1.0.
Un support pour Apple Silicon est également prévu, mais je n'ai actuellement qu'un Macbook Pro Intel disponible pour les tests j'obtiendrai une instance Apple Silicon sur Amazon AWS pour implémenter cela, à temps pour la version 1.0.
Taille d'entrée : 1 920 x 1 080 à 2x
| RTX2060S1 | RTX30702 | RTXA4000 3 | RTX 3090Ti4 | RTX4090 5 | |
|---|---|---|---|---|---|
| RIFE / rife-v4.6 (NCNN) | 53,78 ips | 64,08 ips | 80,56 ips | 86,24 ips | 136,13 ips |
| RIFE / rife-v4.6 (TensorRT) | 70,34 ips | 94,63 ips | 86,47 ips | 122,68 ips | 170,91 ips |
| CAIN / cvp-v6 (NCNN) | 9,42 ips | 10,56 ips | 13,42 ips | 17,36 ips | 44,87 ips |
| CAIN / cvp-v6 (TensorRT) | 45,41 ips | 63,84 ips | 81,23 ips | 112,87 ips | 183,46 ips |
| GMFSS/Up (PyTorch) | - | - | 4,32 ips | - | 16,35 ips |
| GMFSS/Union (PyTorch) | - | - | 3,68 ips | - | 13,93 ips |
| GMFSS/Union (TensorRT) | - | - | 6,79 ips | - | - |
| RealESRGAN / animevideov3 (TensorRT) | 7,64 ips | 9,10 ips | 8,49 images par seconde | 18,66 ips | 38,67 ips |
| RéelCUGAN (TensorRT) | - | - | 5,96 ips | - | - |
| SwinIR (PyTorch) | - | - | 0,43 ips | - | - |
| DPIR / Débruit (TensorRT) | 4,38 ips | 6,45 ips | 5,39 images par seconde | 11,64 ips | 27,41 ips |
1 Ryzen 5 3600X - Gainward RTX 2060 Super en stock
2 Ryzen 7 3800X - Gigabyte RTX 3070 Eagle OC en stock
3 Ryzen 5 3600X - PNY RTX A4000 en stock
4 i9 12900KF - ASUS RTX 3090 Ti Strix OC à ~ 2220 MHz
5 Ryzen 9 5950X - ASUS RTX 4090 Strix OC - @ ~ 3100 MHz avec courbe pour obtenir des performances maximales
Cette section a été déplacée vers le wiki : https://github.com/mafiosnik777/enhancr/wiki
Consultez-le pour en savoir plus sur la façon de tirer le meilleur parti de l'amélioration ou sur la façon de résoudre divers problèmes.
TensorRT est un runtime d'inférence d'IA hautement optimisé pour les GPU NVIDIA. Il utilise l'analyse comparative pour trouver le noyau optimal à utiliser pour votre GPU spécifique, et il existe une étape supplémentaire pour créer un moteur sur la machine sur laquelle vous allez exécuter l'IA. Cependant, les performances qui en résultent sont généralement bien meilleures que n’importe quelle implémentation de PyTorch ou NCNN.
NCNN est un cadre informatique d'inférence de réseau neuronal haute performance optimisé pour les plates-formes mobiles. NCNN n'a aucune dépendance de tiers. Il est multiplateforme et s'exécute plus rapidement que tous les frameworks open source connus sur la plupart des principales plateformes. Il prend en charge NVIDIA, AMD, Intel Graphics et même Apple Silicon. NCNN est actuellement utilisé dans de nombreuses applications Tencent, telles que QQ, Qzone, WeChat, Pitu, etc.
Je vous serais reconnaissant si vous pouviez montrer votre soutien à ce projet en contribuant sur Patreon ou via un don sur PayPal. Votre soutien contribuera à accélérer le développement et à apporter davantage de mises à jour au projet. De plus, si vous avez les compétences, vous pouvez également contribuer en ouvrant une pull request. Quelle que soit la forme de soutien que vous choisissez d’apporter, sachez qu’elle est grandement appréciée.
Je travaille continuellement à améliorer la base de code, notamment en corrigeant les incohérences qui auraient pu survenir en raison de contraintes de temps. Des mises à jour régulières seront publiées, notamment de nouvelles fonctionnalités, des corrections de bugs et l'incorporation de nouvelles technologies et de nouveaux modèles dès qu'ils seront disponibles. Merci pour votre compréhension et votre soutien.
Notre lecteur dépend de mpv et ModernX pour l'OSC.
Merci à HubertSontowski et styler00dollar pour leur aide dans la mise en œuvre de CAIN.
Pour interagir avec la communauté, partager vos résultats ou obtenir de l'aide en cas de problème, visitez notre discord. Des aperçus des versions à venir y seront également présentés.


