performer pytorch
1.1.4
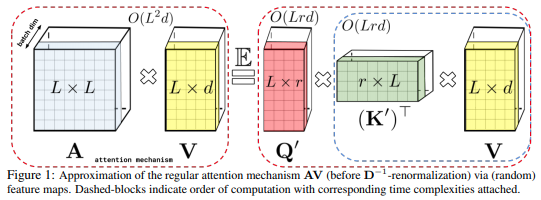
Une implémentation de Performer, une variante de transformateur basée sur l'attention linéaire avec une approche d'attention rapide via une approche de fonctionnalités aléatoires orthogonales positives (FAVOR+).
$ pip install performer-pytorchEnsuite, vous devez exécuter ce qui suit, si vous envisagez de former un modèle autorégressif
$ pip install -r requirements.txtModèle de langage de l'interprète
import torch
from performer_pytorch import PerformerLM
model = PerformerLM (
num_tokens = 20000 ,
max_seq_len = 2048 , # max sequence length
dim = 512 , # dimension
depth = 12 , # layers
heads = 8 , # heads
causal = False , # auto-regressive or not
nb_features = 256 , # number of random features, if not set, will default to (d * log(d)), where d is the dimension of each head
feature_redraw_interval = 1000 , # how frequently to redraw the projection matrix, the more frequent, the slower the training
generalized_attention = False , # defaults to softmax approximation, but can be set to True for generalized attention
kernel_fn = torch . nn . ReLU (), # the kernel function to be used, if generalized attention is turned on, defaults to Relu
reversible = True , # reversible layers, from Reformer paper
ff_chunks = 10 , # chunk feedforward layer, from Reformer paper
use_scalenorm = False , # use scale norm, from 'Transformers without Tears' paper
use_rezero = False , # use rezero, from 'Rezero is all you need' paper
ff_glu = True , # use GLU variant for feedforward
emb_dropout = 0.1 , # embedding dropout
ff_dropout = 0.1 , # feedforward dropout
attn_dropout = 0.1 , # post-attn dropout
local_attn_heads = 4 , # 4 heads are local attention, 4 others are global performers
local_window_size = 256 , # window size of local attention
rotary_position_emb = True , # use rotary positional embedding, which endows linear attention with relative positional encoding with no learned parameters. should always be turned on unless if you want to go back to old absolute positional encoding
shift_tokens = True # shift tokens by 1 along sequence dimension before each block, for better convergence
)
x = torch . randint ( 0 , 20000 , ( 1 , 2048 ))
mask = torch . ones_like ( x ). bool ()
model ( x , mask = mask ) # (1, 2048, 20000)Plain Performer, si vous travaillez avec, par exemple, des images ou d'autres modalités
import torch
from performer_pytorch import Performer
model = Performer (
dim = 512 ,
depth = 1 ,
heads = 8 ,
causal = True
)
x = torch . randn ( 1 , 2048 , 512 )
model ( x ) # (1, 2048, 512)Encodeur / Décodeur - Rendu possible par Thomas Melistas
import torch
from performer_pytorch import PerformerEncDec
SRC_SEQ_LEN = 4096
TGT_SEQ_LEN = 4096
GENERATE_LEN = 512
enc_dec = PerformerEncDec (
dim = 512 ,
tie_token_embed = True ,
enc_num_tokens = 20000 ,
enc_depth = 6 ,
enc_heads = 8 ,
enc_max_seq_len = SRC_SEQ_LEN ,
dec_num_tokens = 20000 ,
dec_depth = 6 ,
dec_heads = 8 ,
dec_max_seq_len = TGT_SEQ_LEN ,
)
src = torch . randint ( 0 , 20000 , ( 1 , SRC_SEQ_LEN ))
tgt = torch . randint ( 0 , 20000 , ( 1 , TGT_SEQ_LEN ))
src_mask = torch . ones_like ( src ). bool ()
tgt_mask = torch . ones_like ( src ). bool ()
# train
enc_dec . train ()
loss = enc_dec ( src , tgt , enc_mask = src_mask , dec_mask = tgt_mask )
loss . backward ()
# generate
generate_in = torch . randint ( 0 , 20000 , ( 1 , SRC_SEQ_LEN )). long ()
generate_out_prime = torch . tensor ([[ 0. ]]). long () # prime with <bos> token
samples = enc_dec . generate ( generate_in , generate_out_prime , seq_len = GENERATE_LEN , eos_token = 1 ) # assume 1 is id of stop token
print ( samples . shape ) # (1, <= GENERATE_LEN) decode the tokensCouche d'auto-attention autonome avec une complexité linéaire en ce qui concerne la longueur de la séquence, pour remplacer les couches d'auto-attention de transformateur à pleine attention entraînées.
import torch
from performer_pytorch import SelfAttention
attn = SelfAttention (
dim = 512 ,
heads = 8 ,
causal = False ,
). cuda ()
x = torch . randn ( 1 , 1024 , 512 ). cuda ()
attn ( x ) # (1, 1024, 512)L'attention croisée est de la même manière
import torch
from performer_pytorch import CrossAttention
attn = CrossAttention (
dim = 512 ,
heads = 8
). cuda ()
x = torch . randn ( 1 , 1024 , 512 ). cuda ()
context = torch . randn ( 1 , 512 , 512 ). cuda ()
attn ( x , context = context ) # (1, 1024, 512) Pour minimiser la chirurgie du modèle, vous pouvez également simplement réécrire le code, afin que l'étape d'attention soit effectuée par le module FastAttention , comme suit.
import torch
from performer_pytorch import FastAttention
# queries / keys / values with heads already split and transposed to first dimension
# 8 heads, dimension of head is 64, sequence length of 512
q = torch . randn ( 1 , 8 , 512 , 64 )
k = torch . randn ( 1 , 8 , 512 , 64 )
v = torch . randn ( 1 , 8 , 512 , 64 )
attn_fn = FastAttention (
dim_heads = 64 ,
nb_features = 256 ,
causal = False
)
out = attn_fn ( q , k , v ) # (1, 8, 512, 64)
# now merge heads and combine outputs with Wo À la fin de la formation, si vous souhaitez corriger les matrices de projection pour obtenir une sortie déterministe du modèle, vous pouvez invoquer ce qui suit
model . fix_projection_matrices_ ()Votre modèle aura désormais des matrices de projection fixes sur toutes les couches
@misc { choromanski2020rethinking ,
title = { Rethinking Attention with Performers } ,
author = { Krzysztof Choromanski and Valerii Likhosherstov and David Dohan and Xingyou Song and Andreea Gane and Tamas Sarlos and Peter Hawkins and Jared Davis and Afroz Mohiuddin and Lukasz Kaiser and David Belanger and Lucy Colwell and Adrian Weller } ,
year = { 2020 } ,
eprint = { 2009.14794 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @inproceedings { katharopoulos_et_al_2020 ,
author = { Katharopoulos, A. and Vyas, A. and Pappas, N. and Fleuret, F. } ,
title = { Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention } ,
booktitle = { Proceedings of the International Conference on Machine Learning (ICML) } ,
year = { 2020 }
} @misc { bachlechner2020rezero ,
title = { ReZero is All You Need: Fast Convergence at Large Depth } ,
author = { Thomas Bachlechner and Bodhisattwa Prasad Majumder and Huanru Henry Mao and Garrison W. Cottrell and Julian McAuley } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2003.04887 }
} @article { 1910.05895 ,
author = { Toan Q. Nguyen and Julian Salazar } ,
title = { Transformers without Tears: Improving the Normalization of Self-Attention } ,
year = { 2019 } ,
eprint = { arXiv:1910.05895 } ,
doi = { 10.5281/zenodo.3525484 } ,
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://arxiv.org/pdf/2003.05997.pdf }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2104.09864 }
}

