local attention
1.9.15
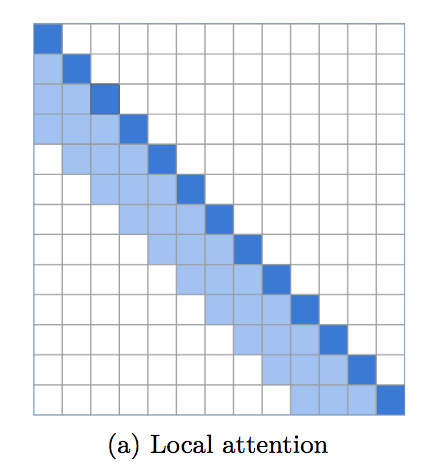
Une implémentation d'une attention locale fenêtrée, qui établit une base de référence incroyablement solide pour la modélisation du langage. Il devient évident qu'un transformateur nécessite une attention locale dans les couches inférieures, les couches supérieures étant réservées à une attention globale afin d'intégrer les découvertes des couches précédentes. Ce référentiel facilite l'utilisation immédiate de l'attention de la fenêtre locale.
Ce code a déjà été testé dans plusieurs référentiels, parallèlement à différentes implémentations d'attention à long terme clairsemée.
$ pip install local-attention import torch
from local_attention import LocalAttention
q = torch . randn ( 2 , 8 , 2048 , 64 )
k = torch . randn ( 2 , 8 , 2048 , 64 )
v = torch . randn ( 2 , 8 , 2048 , 64 )
attn = LocalAttention (
dim = 64 , # dimension of each head (you need to pass this in for relative positional encoding)
window_size = 512 , # window size. 512 is optimal, but 256 or 128 yields good enough results
causal = True , # auto-regressive or not
look_backward = 1 , # each window looks at the window before
look_forward = 0 , # for non-auto-regressive case, will default to 1, so each window looks at the window before and after it
dropout = 0.1 , # post-attention dropout
exact_windowsize = False # if this is set to true, in the causal setting, each query will see at maximum the number of keys equal to the window size
)
mask = torch . ones ( 2 , 2048 ). bool ()
out = attn ( q , k , v , mask = mask ) # (2, 8, 2048, 64)Cette bibliothèque permet également une attention locale dans la configuration de l'espace de requête/clé partagé (architecture Reformer). La normalisation des clés, ainsi que le masquage des tokens sur lui-même, seront pris en charge.
import torch
from local_attention import LocalAttention
qk = torch . randn ( 2 , 8 , 2048 , 64 )
v = torch . randn ( 2 , 8 , 2048 , 64 )
attn = LocalAttention (
dim = 64 ,
window_size = 512 ,
shared_qk = True ,
causal = True
)
mask = torch . ones ( 2 , 2048 ). bool ()
out = attn ( qk , qk , v , mask = mask ) # (2, 8, 2048, 64) Si vous souhaitez que le module remplisse automatiquement votre requête/clé/valeurs ainsi que le masque, définissez simplement le mot-clé autopad sur True
import torch
from local_attention import LocalAttention
q = torch . randn ( 8 , 2057 , 64 )
k = torch . randn ( 8 , 2057 , 64 )
v = torch . randn ( 8 , 2057 , 64 )
attn = LocalAttention (
window_size = 512 ,
causal = True ,
autopad = True # auto pads both inputs and mask, then truncates output appropriately
)
mask = torch . ones ( 1 , 2057 ). bool ()
out = attn ( q , k , v , mask = mask ) # (8, 2057, 64)Un transformateur complet d’attention locale
import torch
from local_attention import LocalTransformer
model = LocalTransformer (
num_tokens = 256 ,
dim = 512 ,
depth = 6 ,
max_seq_len = 8192 ,
causal = True ,
local_attn_window_size = 256
). cuda ()
x = torch . randint ( 0 , 256 , ( 1 , 8192 )). cuda ()
logits = model ( x ) # (1, 8192, 256)taille de fenêtre de 256, rétrospective de 1, champ de réception total de 512
$ python train.py @inproceedings { rae-razavi-2020-transformers ,
title = " Do Transformers Need Deep Long-Range Memory? " ,
author = " Rae, Jack and Razavi, Ali " ,
booktitle = " Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics " ,
month = jul,
year = " 2020 " ,
address = " Online " ,
publisher = " Association for Computational Linguistics " ,
url = " https://www.aclweb.org/anthology/2020.acl-main.672 "
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://arxiv.org/pdf/2003.05997.pdf }
} @misc { beltagy2020longformer ,
title = { Longformer: The Long-Document Transformer } ,
author = { Iz Beltagy and Matthew E. Peters and Arman Cohan } ,
year = { 2020 } ,
eprint = { 2004.05150 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @article { Bondarenko2023QuantizableTR ,
title = { Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing } ,
author = { Yelysei Bondarenko and Markus Nagel and Tijmen Blankevoort } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2306.12929 } ,
url = { https://api.semanticscholar.org/CorpusID:259224568 }
}

