atari
1.0.0

Research Playground construit sur l'Atari Gym d'OpenAI, préparé pour la mise en œuvre de divers algorithmes d'apprentissage par renforcement.
Il peut émuler l'un des jeux suivants :
['Astérix', 'Astéroïdes', 'MsPacman', 'Kaboom', 'BankHeist', 'Kangaroo', 'Skiing', 'FishingDerby', 'Krull', 'Berzerk', 'Toutankhamon', 'Zaxxon', ' Venture', 'Riverraid', 'Centipede', "Adventure", "BeamRider", "CrazyClimber", "TimePilot", "Carnival", "Tennis", "Seaquest", "Bowling", "SpaceInvaders", "Freeway", "YarsRevenge", "RoadRunner", "JourneyEscape". ', 'WizardOfWor', 'Gopher', "Breakout", "StarGunner", "Atlantis", "DoubleDunk", "Hero", "BattleZone", "Solaris", "UpNDown", "Frostbite", "KungFuMaster", "Pooyan", "Pitfall", "MontezumaRevenge". ', 'PrivateEye', 'AirRaid', "Amidar", "Robotank", "DemonAttack", "Defender", "NameThisGame", "Phoenix", "Gravitar", "ElevatorAction", "Pong", "VideoPinball", "IceHockey", "Boxing", "Assault" ', 'Alien', 'Qbert', 'Enduro', "ChopperCommand", "Jamesbond"]
Consultez l'article Medium correspondant : Atari - Apprentissage par renforcement en profondeur ? (Partie 1 : DDQN)
Le but ultime de ce projet est de mettre en œuvre et de comparer diverses approches RL avec les jeux Atari comme dénominateur commun.
pip install -r requirements.txt .python atari.py --help . * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
Réseau neuronal à convolution profonde par DeepMind
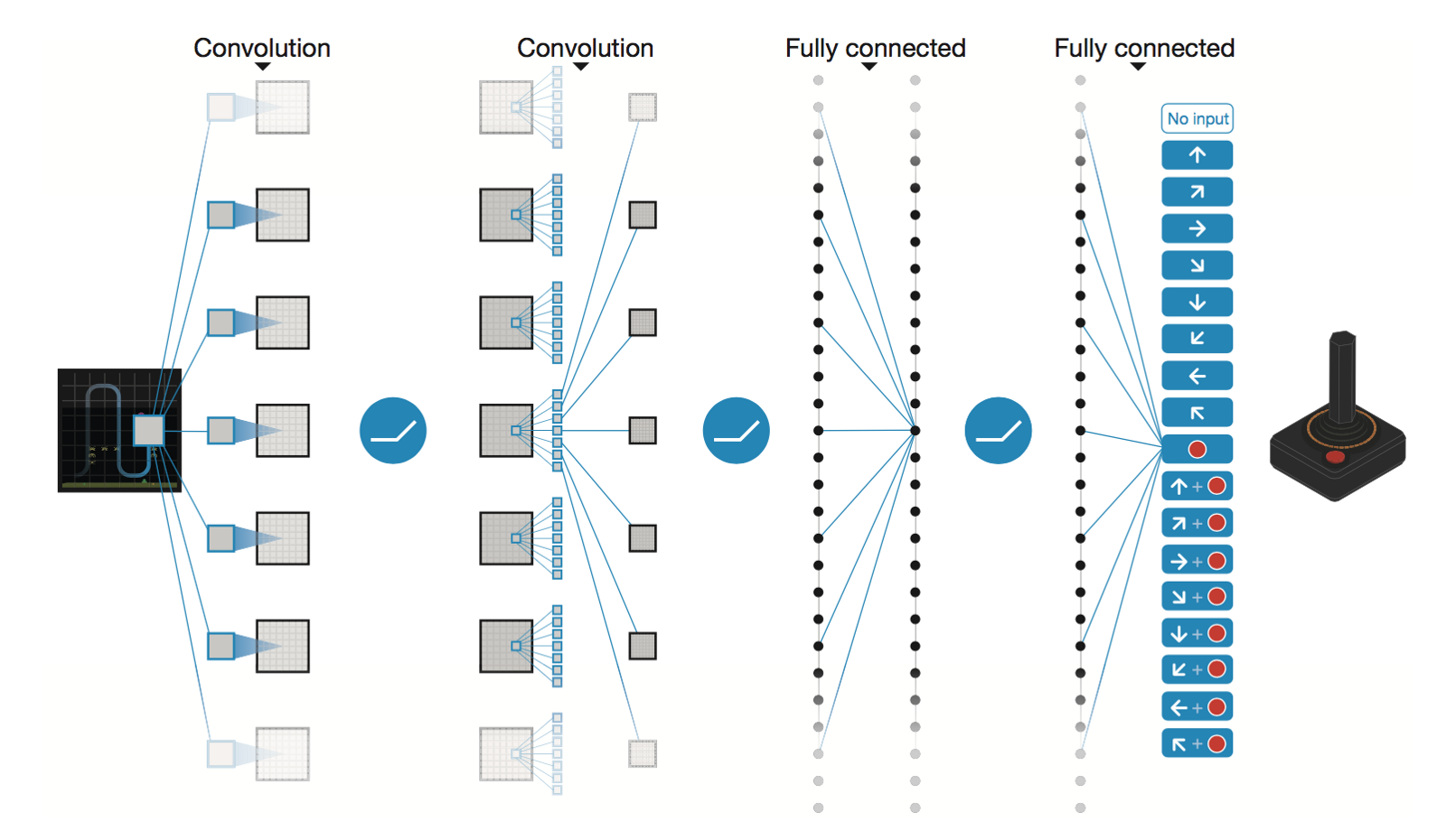
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
Après 5 millions d'étapes ( ~40h sur le GPU Tesla K80 ou ~90h sur le processeur Intel i7 Quad-Core à 2,9 GHz) :
Entraînement:
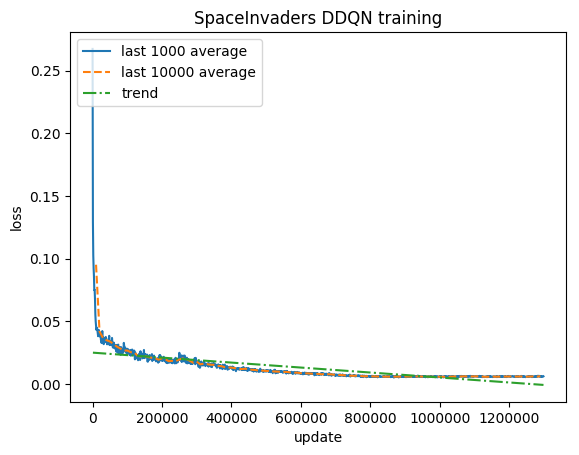
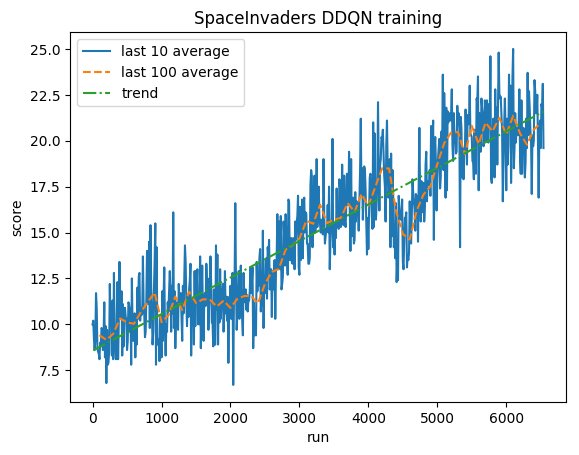
Score normalisé - chaque récompense réduite à (-1, 1)
Essai:
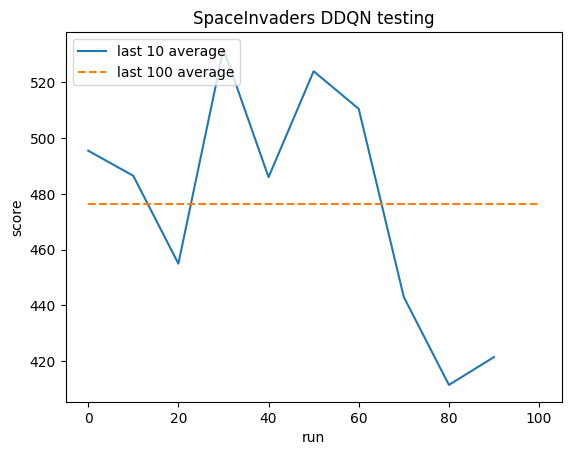
Moyenne humaine : ~372
Moyenne DDQN : ~479 (128 %)
Entraînement:
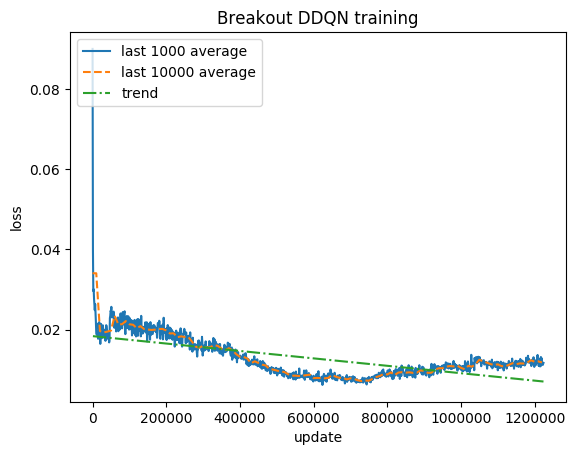
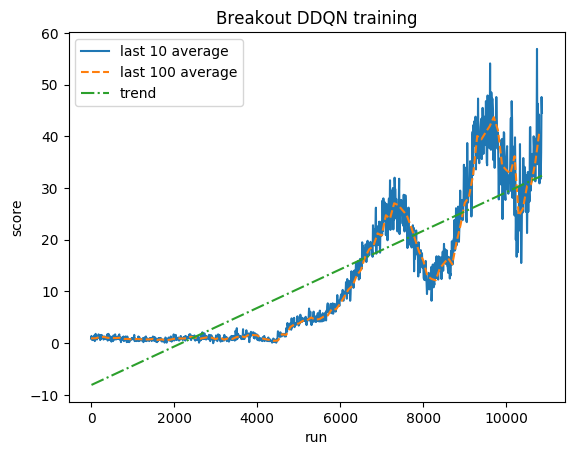
Score normalisé - chaque récompense réduite à (-1, 1)
Essai:
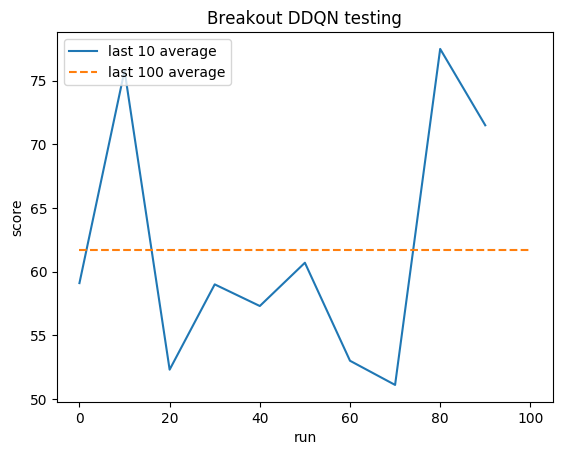
Moyenne humaine : ~28
Moyenne DDQN : ~62 (221 %)
Entraînement:
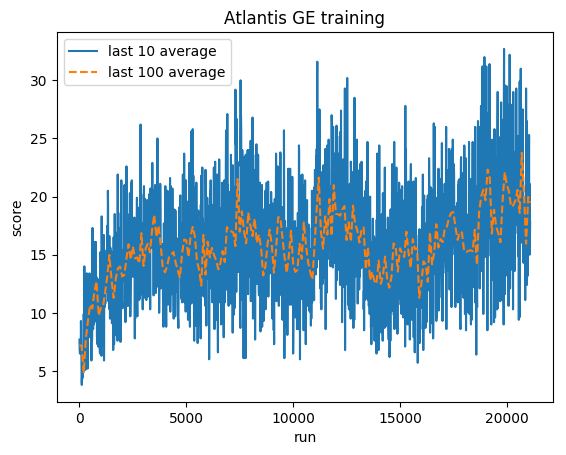
Score normalisé - chaque récompense réduite à (-1, 1)
Essai:

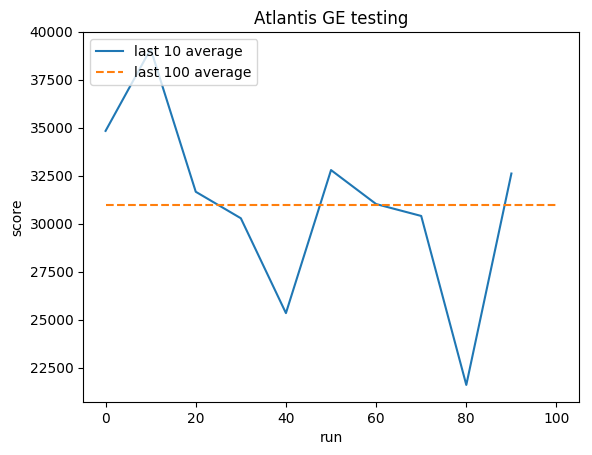
Moyenne humaine : ~29 000
Moyenne GE : 31 000 (106 %)
Greg (Grzegorz) Surma
PORTEFEUILLE
GITHUB
BLOGUE


