LongNet
0.4.8

Il s'agit d'une implémentation open source pour l'article LongNet : Scaling Transformers to 1 000 000 000 Tokens de Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Furu Wei. Le LongNet est une variante de Transformer conçue pour étendre la longueur des séquences jusqu'à plus d'un milliard de jetons sans sacrifier les performances sur des séquences plus courtes.
pip install longnet Une fois que vous avez installé LongNet, vous pouvez utiliser la classe DilatedAttention comme suit :
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformerUn modèle de transformateur entièrement prêt à entraîner avec des blocs de transformateur dilatés avec Feedforwards avec layernorm, SWIGLU et un bloc de transformateur parallèle
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
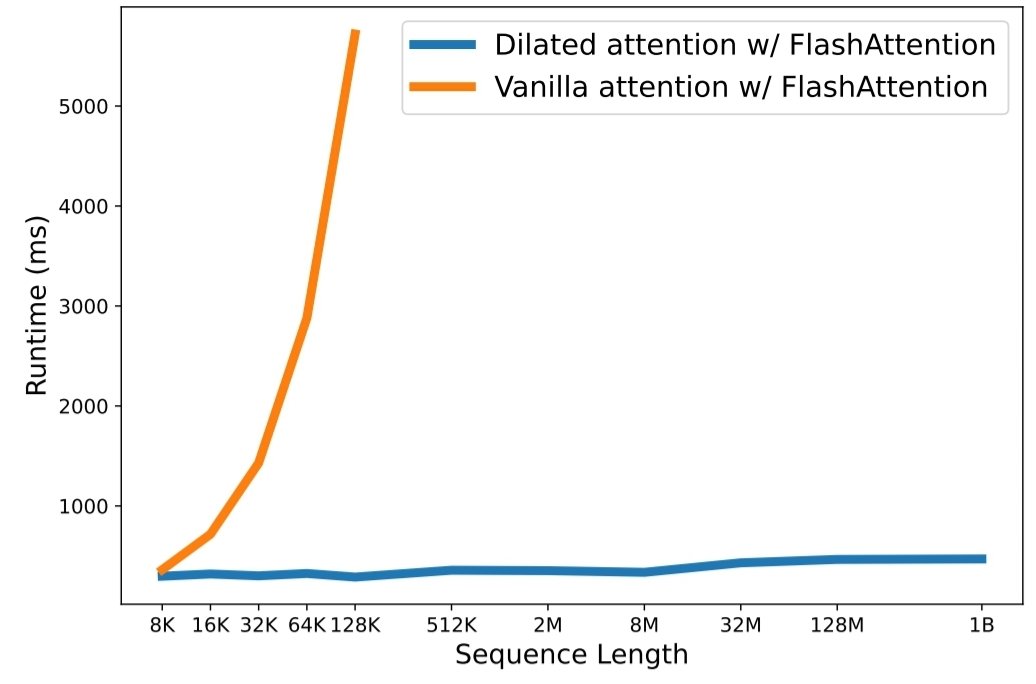
python3 train.py La mise à l’échelle de la longueur des séquences est devenue un goulot d’étranglement critique à l’ère des grands modèles de langage. Cependant, les méthodes existantes ont des difficultés avec la complexité de calcul ou l'expressivité du modèle, ce qui restreint la longueur maximale de la séquence. Dans cet article, ils présentent LongNet, une variante de Transformer qui peut étendre la longueur des séquences à plus d'un milliard de jetons, sans sacrifier les performances sur des séquences plus courtes. Plus précisément, ils proposent une attention dilatée, qui élargit le champ attentif de façon exponentielle à mesure que la distance augmente.
LongNet présente des avantages significatifs :
Les résultats de l'expérience démontrent que LongNet offre de solides performances à la fois sur la modélisation de longues séquences et sur les tâches de langage général. Leurs travaux ouvrent de nouvelles possibilités pour modéliser des séquences très longues, par exemple en traitant un corpus entier, voire l'ensemble d'Internet, comme une séquence.
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

