cnn svm
1.0.0
Ce projet a été inspiré par le Deep Learning de Y. Tang utilisant des machines à vecteurs de support linéaire (2013).
L'article complet sur ce projet peut être lu sur arXiv.org.
Les réseaux de neurones convolutifs (CNN) sont similaires aux réseaux de neurones « ordinaires » dans le sens où ils sont constitués de couches cachées constituées de neurones avec des paramètres « apprenables ». Ces neurones reçoivent des entrées, effectuent un produit scalaire, puis le suivent avec une non-linéarité. L'ensemble du réseau exprime le mappage entre les pixels de l'image brute et leurs scores de classe. Classiquement, la fonction Softmax est le classificateur utilisé au niveau de la dernière couche de ce réseau. Cependant, des études (Alalshekmubarak et Smith, 2013 ; Agarap, 2017 ; Tang, 2013) ont été menées pour remettre en question cette norme. Les études citées introduisent l'utilisation d'une machine à vecteurs de support linéaire (SVM) dans une architecture de réseau neuronal artificiel. Ce projet est une autre approche du sujet et s'inspire de (Tang, 2013). Des données empiriques ont montré que le modèle CNN-SVM était capable d'atteindre une précision de test d'environ 99,04 % en utilisant l'ensemble de données MNIST (LeCun, Cortes et Burges, 2010). D'un autre côté, CNN-Softmax a pu atteindre une précision de test d'environ 99,23 % en utilisant le même ensemble de données. Les deux modèles ont également été testés sur l'ensemble de données Fashion-MNIST récemment publié (Xiao, Rasul et Vollgraf, 2017), qui est censé être un ensemble de données de classification d'images plus difficile que le MNIST (Zalandoresearch, 2017). Cela s'est avéré être le cas puisque CNN-SVM a atteint une précision de test d'environ 90,72 %, tandis que CNN-Softmax a atteint une précision de test d'environ 91,86 %. Lesdits résultats pourraient être améliorés si des techniques de prétraitement des données étaient utilisées sur les ensembles de données et si le modèle CNN de base était relativement plus sophistiqué que celui utilisé dans cette étude.
Tout d’abord, clonez le projet.
git clone https://github.com/AFAgarap/cnn-svm.git/ Exécutez setup.sh pour vous assurer que les bibliothèques prérequises sont installées dans l'environnement.
sudo chmod +x setup.sh
./setup.shParamètres du programme.
usage: main.py [-h] -m MODEL -d DATASET [-p PENALTY_PARAMETER] -c
CHECKPOINT_PATH -l LOG_PATH
CNN & CNN-SVM for Image Classification
optional arguments:
-h, --help show this help message and exit
Arguments:
-m MODEL, --model MODEL
[1] CNN-Softmax, [2] CNN-SVM
-d DATASET, --dataset DATASET
path of the MNIST dataset
-p PENALTY_PARAMETER, --penalty_parameter PENALTY_PARAMETER
the SVM C penalty parameter
-c CHECKPOINT_PATH, --checkpoint_path CHECKPOINT_PATH
path where to save the trained model
-l LOG_PATH, --log_path LOG_PATH
path where to save the TensorBoard logs Ensuite, accédez au répertoire du référentiel et exécutez le module main.py selon les paramètres souhaités.
cd cnn-svm
python3 main.py --model 2 --dataset ./MNIST_data --penalty_parameter 1 --checkpoint_path ./checkpoint --log_path ./logsLes hyperparamètres utilisés dans ce projet ont été attribués manuellement et non par optimisation.
| Hyperparamètres | CNN-Softmax | CNN-SVM |
|---|---|---|
| Taille du lot | 128 | 128 |
| Taux d'apprentissage | 1e-3 | 1e-3 |
| Mesures | 10000 | 10000 |
| SVM C | N / A | 1 |
Les expériences ont été menées sur un ordinateur portable équipé d'un processeur Intel Core(TM) i5-6300HQ à 2,30 GHz x 4, de 16 Go de RAM DDR3 et d'un GPU NVIDIA GeForce GTX 960M 4 Go DDR5.
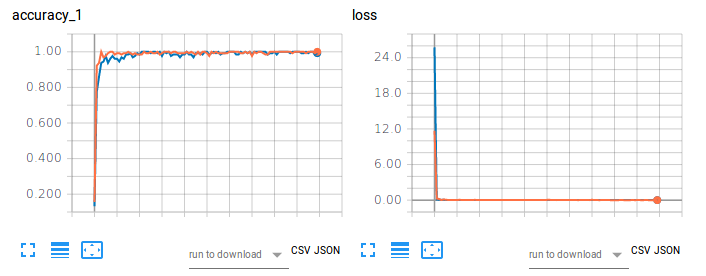
Figure 1. Précision de formation (à gauche) et perte (à droite) de CNN-Softmax et CNN-SVM sur la classification d'images à l'aide de MNIST.
Le tracé orange fait référence à la précision de l'entraînement et à la perte de CNN-Softmax, avec une précision de test de 99,22999739646912 %. D'autre part, le tracé bleu fait référence à la précision de l'entraînement et à la perte de CNN-SVM, avec une précision de test de 99,04000163078308 %. Les résultats ne corroborent pas les conclusions de Tang (2017) pour la classification des chiffres manuscrits du MNIST. Cela peut être attribué au fait qu'aucun prétraitement des données ni réduction de dimensionnalité n'a été effectué sur l'ensemble de données de ce projet.
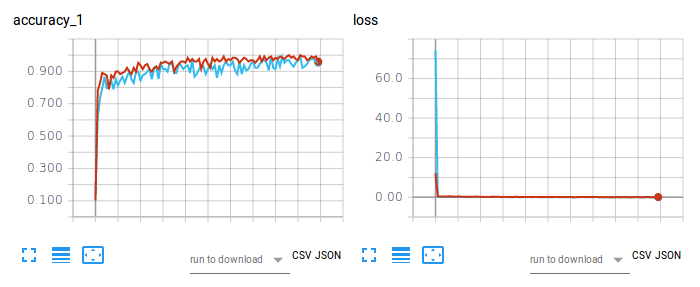
Figure 2. Précision de formation (à gauche) et perte (à droite) de CNN-Softmax et CNN-SVM sur la classification d'images à l'aide de Fashion-MNIST.
Le tracé rouge fait référence à la précision de l'entraînement et à la perte de CNN-Softmax, avec une précision de test de 91,86000227928162 %. D'autre part, le tracé bleu clair fait référence à la précision de l'entraînement et à la perte de CNN-SVM, avec une précision de test de 90,71999788284302 %. Le résultat sur CNN-Softmax corrobore les conclusions de zalandoresearch sur Fashion-MNIST.
Pour citer l'article, veuillez utiliser l'entrée BibTex suivante :
@article{agarap2017architecture,
title={An Architecture Combining Convolutional Neural Network (CNN) and Support Vector Machine (SVM) for Image Classification},
author={Agarap, Abien Fred},
journal={arXiv preprint arXiv:1712.03541},
year={2017}
}
Pour citer le référentiel/logiciel, veuillez utiliser l'entrée BibTex suivante :
@misc{abien_fred_agarap_2017_1098369,
author = {Abien Fred Agarap},
title = {AFAgarap/cnn-svm v0.1.0-alpha},
month = dec,
year = 2017,
doi = {10.5281/zenodo.1098369},
url = {https://doi.org/10.5281/zenodo.1098369}
}
Copyright 2017-2020 Abien Fred Agarap
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


